 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable language model adaptation for spoken dialogue systems
Dec 11, 2018



Language models (LM) for interactive speech recognition systems are trained on large amounts of data and the model parameters are optimized on past user data. New application intents and interaction types are released for these systems over time, imposing challenges to adapt the LMs since the existing training data is no longer sufficient to model the future user interactions. It is unclear how to adapt LMs to new application intents without degrading the performance on existing applications. In this paper, we propose a solution to (a) estimate n-gram counts directly from the hand-written grammar for training LMs and (b) use constrained optimization to optimize the system parameters for future use cases, while not degrading the performance on past usage. We evaluated our approach on new applications intents for a personal assistant system and find that the adaptation improves the word error rate by up to 15% on new applications even when there is no adaptation data available for an application.
Just ASK: Building an Architecture for Extensible Self-Service Spoken Language Understanding
Mar 02, 2018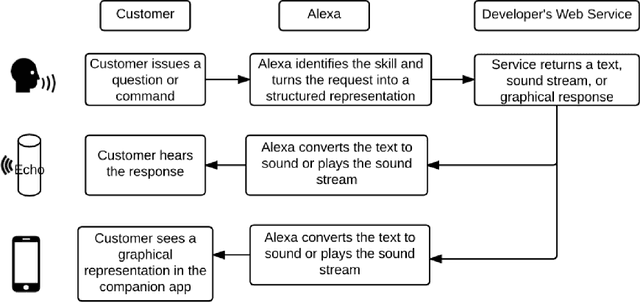
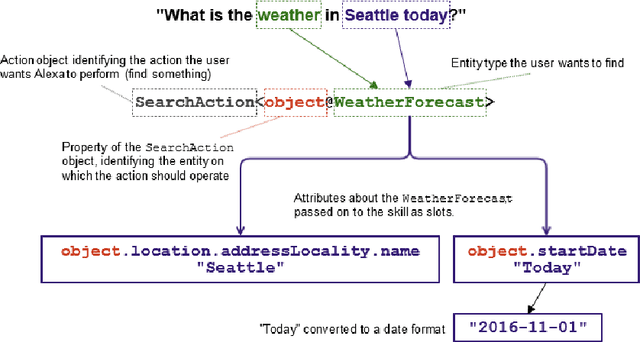
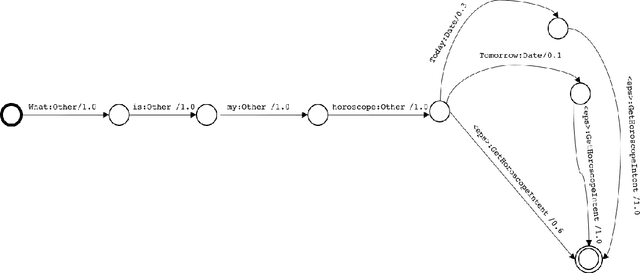
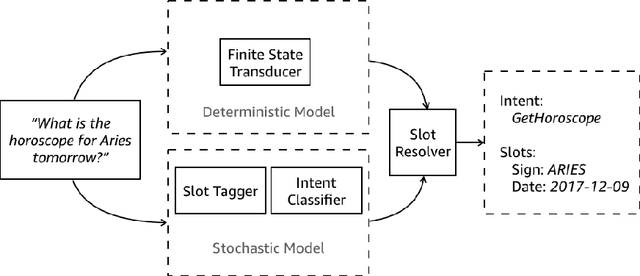
This paper presents the design of the machine learning architecture that underlies the Alexa Skills Kit (ASK) a large scale Spoken Language Understanding (SLU) Software Development Kit (SDK) that enables developers to extend the capabilities of Amazon's virtual assistant, Alexa. At Amazon, the infrastructure powers over 25,000 skills deployed through the ASK, as well as AWS's Amazon Lex SLU Service. The ASK emphasizes flexibility, predictability and a rapid iteration cycle for third party developers. It imposes inductive biases that allow it to learn robust SLU models from extremely small and sparse datasets and, in doing so, removes significant barriers to entry for software developers and dialogue systems researchers.