 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoQA: Evidence-based Question Answering with Generated News Events
May 09, 2025Evaluating Retrieval-Augmented Generation (RAG) in large language models (LLMs) is challenging because benchmarks can quickly become stale. Questions initially requiring retrieval may become answerable from pretraining knowledge as newer models incorporate more recent information during pretraining, making it difficult to distinguish evidence-based reasoning from recall. We introduce NeoQA (News Events for Out-of-training Question Answering), a benchmark designed to address this issue. To construct NeoQA, we generated timelines and knowledge bases of fictional news events and entities along with news articles and Q\&A pairs to prevent LLMs from leveraging pretraining knowledge, ensuring that no prior evidence exists in their training data. We propose our dataset as a new platform for evaluating evidence-based question answering, as it requires LLMs to generate responses exclusively from retrieved evidence and only when sufficient evidence is available. NeoQA enables controlled evaluation across various evidence scenarios, including cases with missing or misleading details. Our findings indicate that LLMs struggle to distinguish subtle mismatches between questions and evidence, and suffer from short-cut reasoning when key information required to answer a question is missing from the evidence, underscoring key limitations in evidence-based reasoning.
NewsQs: Multi-Source Question Generation for the Inquiring Mind
Feb 28, 2024



We present NewsQs (news-cues), a dataset that provides question-answer pairs for multiple news documents. To create NewsQs, we augment a traditional multi-document summarization dataset with questions automatically generated by a T5-Large model fine-tuned on FAQ-style news articles from the News On the Web corpus. We show that fine-tuning a model with control codes produces questions that are judged acceptable more often than the same model without them as measured through human evaluation. We use a QNLI model with high correlation with human annotations to filter our data. We release our final dataset of high-quality questions, answers, and document clusters as a resource for future work in query-based multi-document summarization.
Background Summarization of Event Timelines
Oct 24, 2023Generating concise summaries of news events is a challenging natural language processing task. While journalists often curate timelines to highlight key sub-events, newcomers to a news event face challenges in catching up on its historical context. In this paper, we address this need by introducing the task of background news summarization, which complements each timeline update with a background summary of relevant preceding events. We construct a dataset by merging existing timeline datasets and asking human annotators to write a background summary for each timestep of each news event. We establish strong baseline performance using state-of-the-art summarization systems and propose a query-focused variant to generate background summaries. To evaluate background summary quality, we present a question-answering-based evaluation metric, Background Utility Score (BUS), which measures the percentage of questions about a current event timestep that a background summary answers. Our experiments show the effectiveness of instruction fine-tuned systems such as Flan-T5, in addition to strong zero-shot performance using GPT-3.5.
Generating Summaries with Controllable Readability Levels
Oct 16, 2023Readability refers to how easily a reader can understand a written text. Several factors affect the readability level, such as the complexity of the text, its subject matter, and the reader's background knowledge. Generating summaries based on different readability levels is critical for enabling knowledge consumption by diverse audiences. However, current text generation approaches lack refined control, resulting in texts that are not customized to readers' proficiency levels. In this work, we bridge this gap and study techniques to generate summaries at specified readability levels. Unlike previous methods that focus on a specific readability level (e.g., lay summarization), we generate summaries with fine-grained control over their readability. We develop three text generation techniques for controlling readability: (1) instruction-based readability control, (2) reinforcement learning to minimize the gap between requested and observed readability and (3) a decoding approach that uses lookahead to estimate the readability of upcoming decoding steps. We show that our generation methods significantly improve readability control on news summarization (CNN/DM dataset), as measured by various readability metrics and human judgement, establishing strong baselines for controllable readability in summarization.
On Conditional and Compositional Language Model Differentiable Prompting
Jul 04, 2023Prompts have been shown to be an effective method to adapt a frozen Pretrained Language Model (PLM) to perform well on downstream tasks. Prompts can be represented by a human-engineered word sequence or by a learned continuous embedding. In this work, we investigate conditional and compositional differentiable prompting. We propose a new model, Prompt Production System (PRopS), which learns to transform task instructions or input metadata, into continuous prompts that elicit task-specific outputs from the PLM. Our model uses a modular network structure based on our neural formulation of Production Systems, which allows the model to learn discrete rules -- neural functions that learn to specialize in transforming particular prompt input patterns, making it suitable for compositional transfer learning and few-shot learning. We present extensive empirical and theoretical analysis and show that PRopS consistently surpasses other PLM adaptation techniques, and often improves upon fully fine-tuned models, on compositional generalization tasks, controllable summarization and multilingual translation, while needing fewer trainable parameters.
Faithfulness-Aware Decoding Strategies for Abstractive Summarization
Mar 06, 2023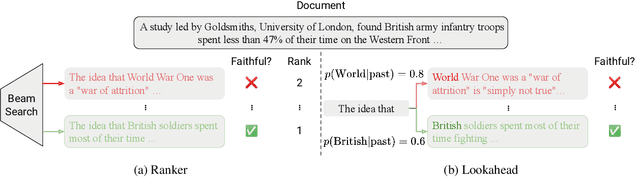
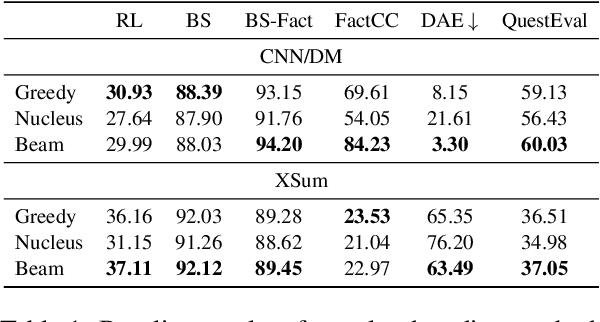
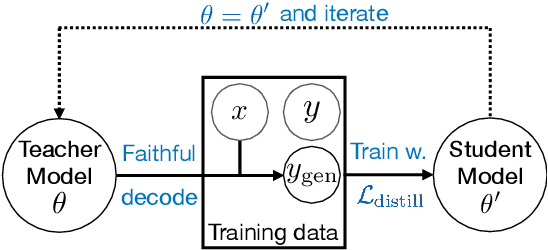
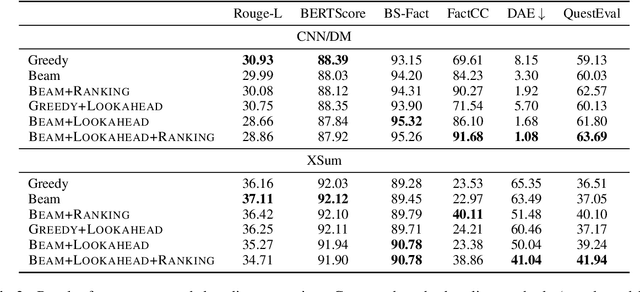
Despite significant progress in understanding and improving faithfulness in abstractive summarization, the question of how decoding strategies affect faithfulness is less studied. We present a systematic study of the effect of generation techniques such as beam search and nucleus sampling on faithfulness in abstractive summarization. We find a consistent trend where beam search with large beam sizes produces the most faithful summaries while nucleus sampling generates the least faithful ones. We propose two faithfulness-aware generation methods to further improve faithfulness over current generation techniques: (1) ranking candidates generated by beam search using automatic faithfulness metrics and (2) incorporating lookahead heuristics that produce a faithfulness score on the future summary. We show that both generation methods significantly improve faithfulness across two datasets as evaluated by four automatic faithfulness metrics and human evaluation. To reduce computational cost, we demonstrate a simple distillation approach that allows the model to generate faithful summaries with just greedy decoding. Our code is publicly available at https://github.com/amazon-science/faithful-summarization-generation
Efficient Few-Shot Fine-Tuning for Opinion Summarization
May 08, 2022



Abstractive summarization models are typically pre-trained on large amounts of generic texts, then fine-tuned on tens or hundreds of thousands of annotated samples. However, in opinion summarization, large annotated datasets of reviews paired with reference summaries are not available and would be expensive to create. This calls for fine-tuning methods robust to overfitting on small datasets. In addition, generically pre-trained models are often not accustomed to the specifics of customer reviews and, after fine-tuning, yield summaries with disfluencies and semantic mistakes. To address these problems, we utilize an efficient few-shot method based on adapters which, as we show, can easily store in-domain knowledge. Instead of fine-tuning the entire model, we add adapters and pre-train them in a task-specific way on a large corpus of unannotated customer reviews, using held-out reviews as pseudo summaries. Then, fine-tune the adapters on the small available human-annotated dataset. We show that this self-supervised adapter pre-training improves summary quality over standard fine-tuning by 2.0 and 1.3 ROUGE-L points on the Amazon and Yelp datasets, respectively. Finally, for summary personalization, we condition on aspect keyword queries, automatically created from generic datasets. In the same vein, we pre-train the adapters in a query-based manner on customer reviews and then fine-tune them on annotated datasets. This results in better-organized summary content reflected in improved coherence and fewer redundancies.
FactGraph: Evaluating Factuality in Summarization with Semantic Graph Representations
Apr 13, 2022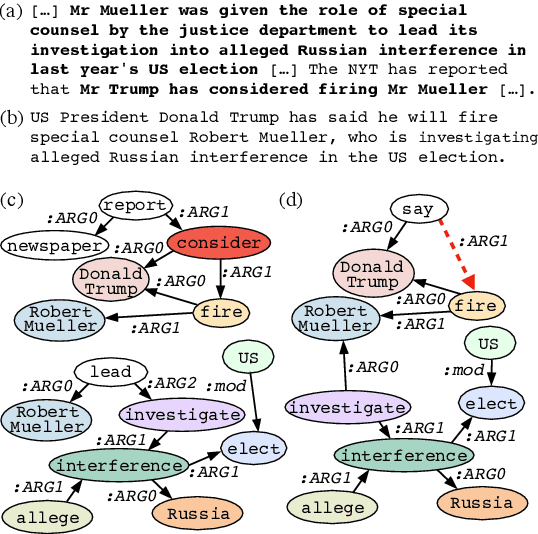
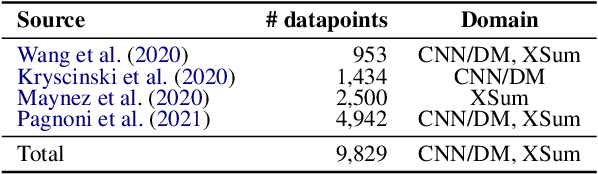
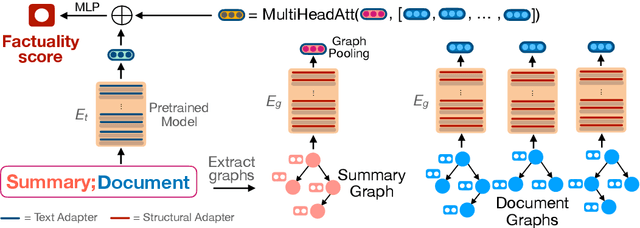

Despite recent improvements in abstractive summarization, most current approaches generate summaries that are not factually consistent with the source document, severely restricting their trust and usage in real-world applications. Recent works have shown promising improvements in factuality error identification using text or dependency arc entailments; however, they do not consider the entire semantic graph simultaneously. To this end, we propose FactGraph, a method that decomposes the document and the summary into structured meaning representations (MR), which are more suitable for factuality evaluation. MRs describe core semantic concepts and their relations, aggregating the main content in both document and summary in a canonical form, and reducing data sparsity. FactGraph encodes such graphs using a graph encoder augmented with structure-aware adapters to capture interactions among the concepts based on the graph connectivity, along with text representations using an adapter-based text encoder. Experiments on different benchmarks for evaluating factuality show that FactGraph outperforms previous approaches by up to 15%. Furthermore, FactGraph improves performance on identifying content verifiability errors and better captures subsentence-level factual inconsistencies.
Analyzing the Abstractiveness-Factuality Tradeoff With Nonlinear Abstractiveness Constraints
Aug 05, 2021
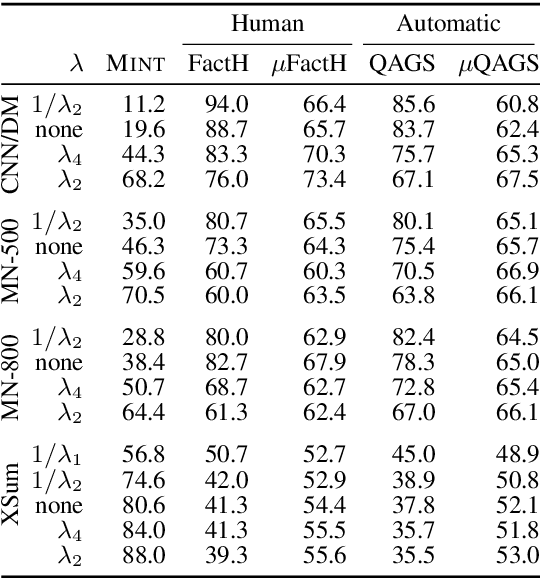
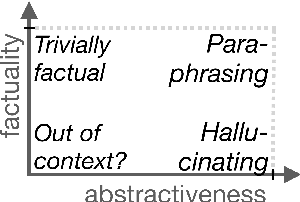
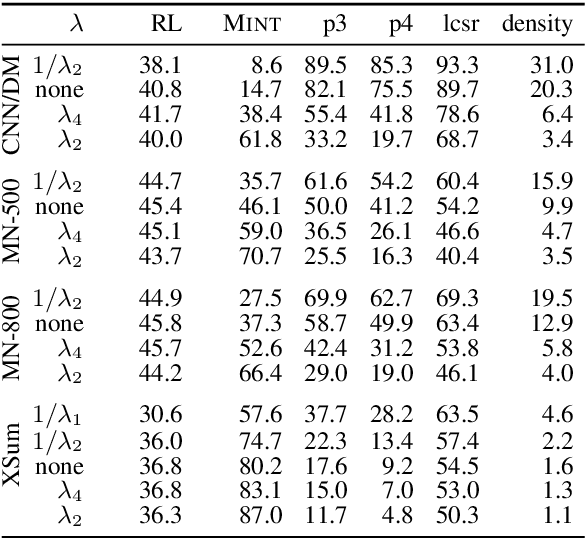
We analyze the tradeoff between factuality and abstractiveness of summaries. We introduce abstractiveness constraints to control the degree of abstractiveness at decoding time, and we apply this technique to characterize the abstractiveness-factuality tradeoff across multiple widely-studied datasets, using extensive human evaluations. We train a neural summarization model on each dataset and visualize the rates of change in factuality as we gradually increase abstractiveness using our abstractiveness constraints. We observe that, while factuality generally drops with increased abstractiveness, different datasets lead to different rates of factuality decay. We propose new measures to quantify the tradeoff between factuality and abstractiveness, incl. muQAGS, which balances factuality with abstractiveness. We also quantify this tradeoff in previous works, aiming to establish baselines for the abstractiveness-factuality tradeoff that future publications can compare against.
Transductive Learning for Abstractive News Summarization
Apr 17, 2021
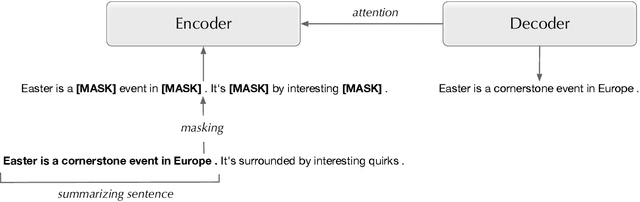
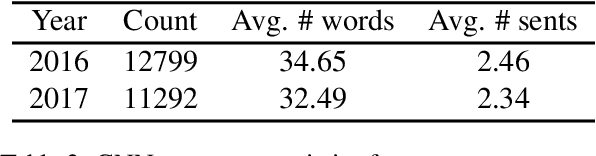
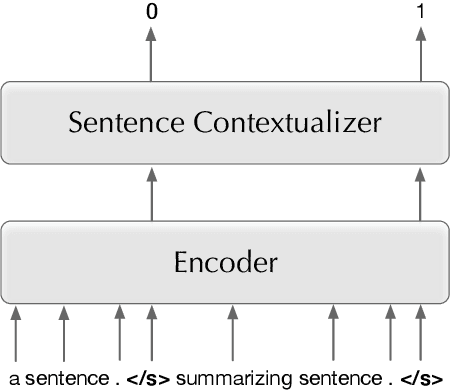
Pre-trained language models have recently advanced abstractive summarization. These models are further fine-tuned on human-written references before summary generation in test time. In this work, we propose the first application of transductive learning to summarization. In this paradigm, a model can learn from the test set's input before inference. To perform transduction, we propose to utilize input document summarizing sentences to construct references for learning in test time. These sentences are often compressed and fused to form abstractive summaries and provide omitted details and additional context to the reader. We show that our approach yields state-of-the-art results on CNN/DM and NYT datasets. For instance, we achieve over 1 ROUGE-L point improvement on CNN/DM. Further, we show the benefits of transduction from older to more recent news. Finally, through human and automatic evaluation, we show that our summaries become more abstractive and coherent.