 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLAtE: A Large-scale Dataset for List Page Web Extraction
May 24, 2022
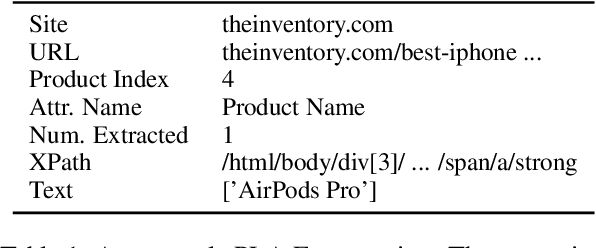

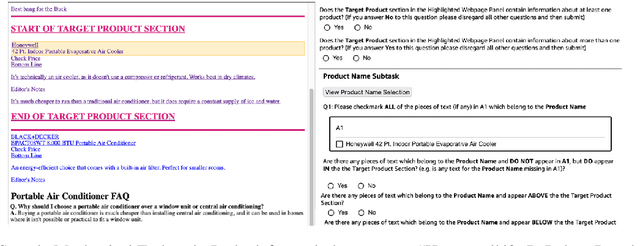
Recently, neural models have been leveraged to significantly improve the performance of information extraction from semi-structured websites. However, a barrier for continued progress is the small number of datasets large enough to train these models. In this work, we introduce the PLAtE (Pages of Lists Attribute Extraction) dataset as a challenging new web extraction task. PLAtE focuses on shopping data, specifically extractions from product review pages with multiple items. PLAtE encompasses both the tasks of: (1) finding product-list segmentation boundaries and (2) extracting attributes for each product. PLAtE is composed of 53, 905 items from 6, 810 pages, making it the first large-scale list page web extraction dataset. We construct PLAtE by collecting list pages from Common Crawl, then annotating them on Mechanical Turk. Quantitative and qualitative analyses are performed to demonstrate PLAtE has high-quality annotations. We establish strong baseline performance on PLAtE with a SOTA model achieving an F1-score of 0.750 for attribute classification and 0.915 for segmentation, indicating opportunities for future research innovations in web extraction.
Generating Self-Contained and Summary-Centric Question Answer Pairs via Differentiable Reward Imitation Learning
Sep 10, 2021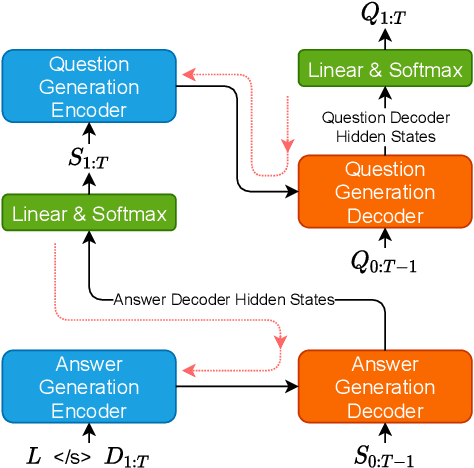
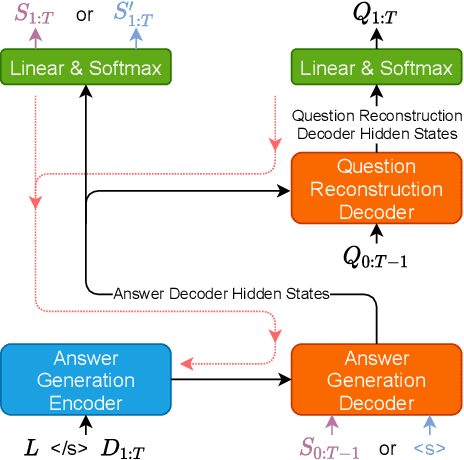
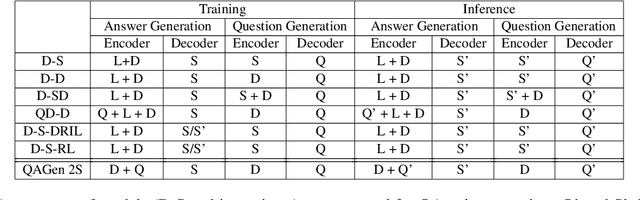
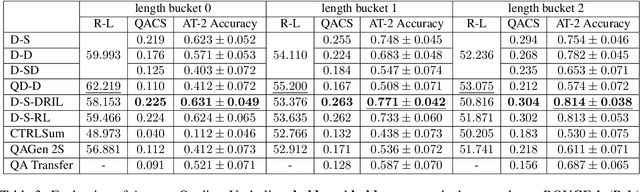
Motivated by suggested question generation in conversational news recommendation systems, we propose a model for generating question-answer pairs (QA pairs) with self-contained, summary-centric questions and length-constrained, article-summarizing answers. We begin by collecting a new dataset of news articles with questions as titles and pairing them with summaries of varying length. This dataset is used to learn a QA pair generation model producing summaries as answers that balance brevity with sufficiency jointly with their corresponding questions. We then reinforce the QA pair generation process with a differentiable reward function to mitigate exposure bias, a common problem in natural language generation. Both automatic metrics and human evaluation demonstrate these QA pairs successfully capture the central gists of the articles and achieve high answer accuracy.
Analyzing the Abstractiveness-Factuality Tradeoff With Nonlinear Abstractiveness Constraints
Aug 05, 2021
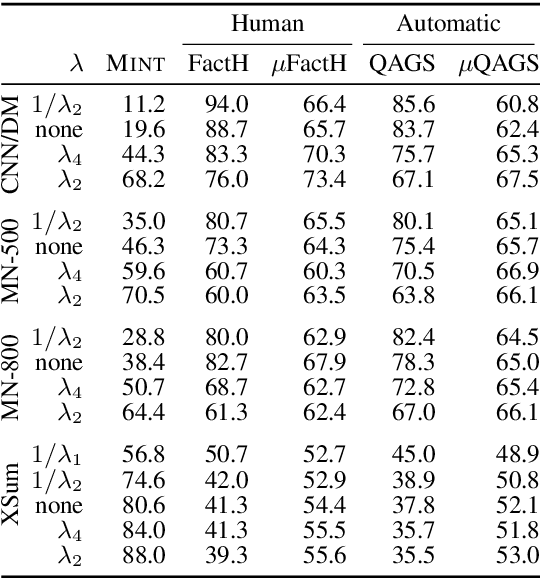
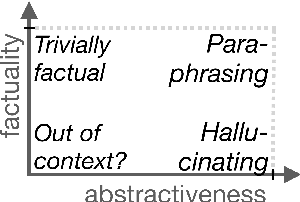
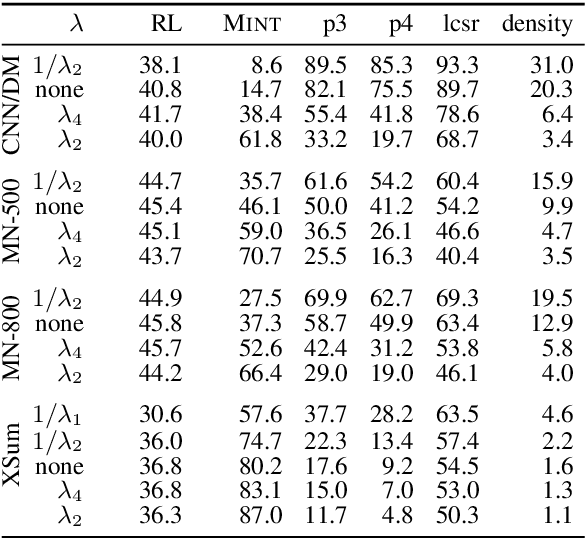
We analyze the tradeoff between factuality and abstractiveness of summaries. We introduce abstractiveness constraints to control the degree of abstractiveness at decoding time, and we apply this technique to characterize the abstractiveness-factuality tradeoff across multiple widely-studied datasets, using extensive human evaluations. We train a neural summarization model on each dataset and visualize the rates of change in factuality as we gradually increase abstractiveness using our abstractiveness constraints. We observe that, while factuality generally drops with increased abstractiveness, different datasets lead to different rates of factuality decay. We propose new measures to quantify the tradeoff between factuality and abstractiveness, incl. muQAGS, which balances factuality with abstractiveness. We also quantify this tradeoff in previous works, aiming to establish baselines for the abstractiveness-factuality tradeoff that future publications can compare against.