 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
May 13, 2024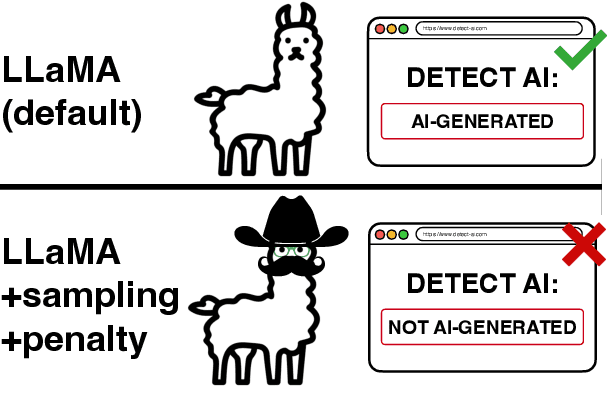
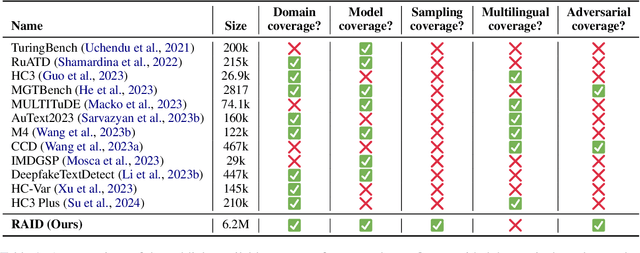
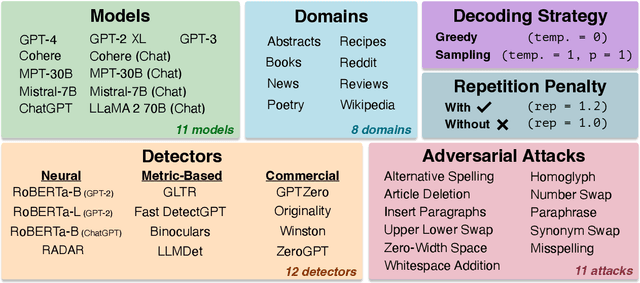

Many commercial and open-source models claim to detect machine-generated text with very high accuracy (99\% or higher). However, very few of these detectors are evaluated on shared benchmark datasets and even when they are, the datasets used for evaluation are insufficiently challenging -- lacking variations in sampling strategy, adversarial attacks, and open-source generative models. In this work we present RAID: the largest and most challenging benchmark dataset for machine-generated text detection. RAID includes over 6 million generations spanning 11 models, 8 domains, 11 adversarial attacks and 4 decoding strategies. Using RAID, we evaluate the out-of-domain and adversarial robustness of 8 open- and 4 closed-source detectors and find that current detectors are easily fooled by adversarial attacks, variations in sampling strategies, repetition penalties, and unseen generative models. We release our dataset and tools to encourage further exploration into detector robustness.
NewsQs: Multi-Source Question Generation for the Inquiring Mind
Feb 28, 2024



We present NewsQs (news-cues), a dataset that provides question-answer pairs for multiple news documents. To create NewsQs, we augment a traditional multi-document summarization dataset with questions automatically generated by a T5-Large model fine-tuned on FAQ-style news articles from the News On the Web corpus. We show that fine-tuning a model with control codes produces questions that are judged acceptable more often than the same model without them as measured through human evaluation. We use a QNLI model with high correlation with human annotations to filter our data. We release our final dataset of high-quality questions, answers, and document clusters as a resource for future work in query-based multi-document summarization.
FanOutQA: Multi-Hop, Multi-Document Question Answering for Large Language Models
Feb 21, 2024One type of question that is commonly found in day-to-day scenarios is ``fan-out'' questions, complex multi-hop, multi-document reasoning questions that require finding information about a large number of entities. However, there exist few resources to evaluate this type of question-answering capability among large language models. To evaluate complex reasoning in LLMs more fully, we present FanOutQA, a high-quality dataset of fan-out question-answer pairs and human-annotated decompositions with English Wikipedia as the knowledge base. We formulate three benchmark settings across our dataset and benchmark 7 LLMs, including GPT-4, LLaMA 2, Claude-2.1, and Mixtral-8x7B, finding that contemporary models still have room to improve reasoning over inter-document dependencies in a long context. We provide our dataset and open-source tools to run models to encourage evaluation at https://fanoutqa.com
Grounded Intuition of GPT-Vision's Abilities with Scientific Images
Nov 03, 2023GPT-Vision has impressed us on a range of vision-language tasks, but it comes with the familiar new challenge: we have little idea of its capabilities and limitations. In our study, we formalize a process that many have instinctively been trying already to develop "grounded intuition" of this new model. Inspired by the recent movement away from benchmarking in favor of example-driven qualitative evaluation, we draw upon grounded theory and thematic analysis in social science and human-computer interaction to establish a rigorous framework for qualitative evaluation in natural language processing. We use our technique to examine alt text generation for scientific figures, finding that GPT-Vision is particularly sensitive to prompting, counterfactual text in images, and relative spatial relationships. Our method and analysis aim to help researchers ramp up their own grounded intuitions of new models while exposing how GPT-Vision can be applied to make information more accessible.
Kani: A Lightweight and Highly Hackable Framework for Building Language Model Applications
Sep 11, 2023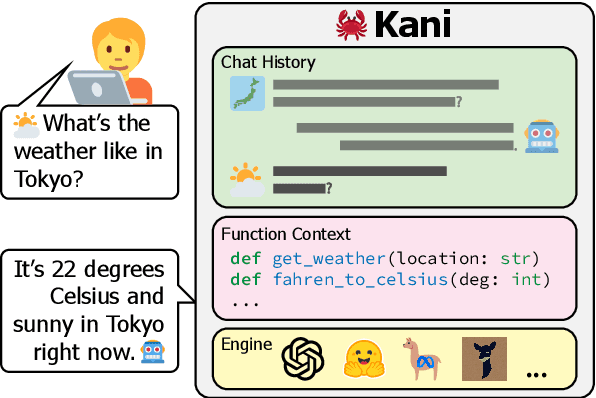

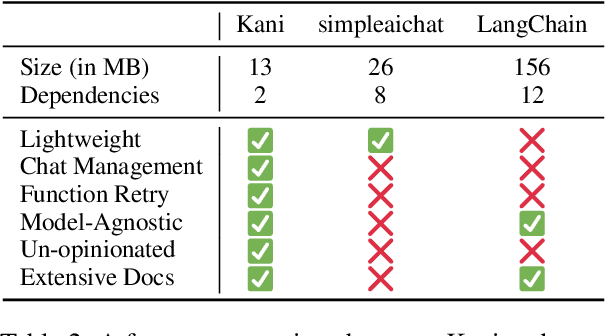
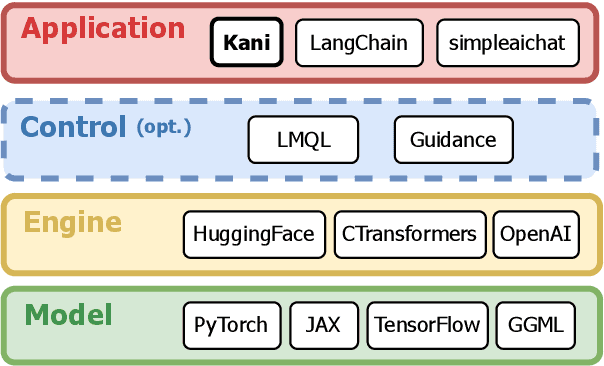
Language model applications are becoming increasingly popular and complex, often including features like tool usage and retrieval augmentation. However, existing frameworks for such applications are often opinionated, deciding for developers how their prompts ought to be formatted and imposing limitations on customizability and reproducibility. To solve this we present Kani: a lightweight, flexible, and model-agnostic open-source framework for building language model applications. Kani helps developers implement a variety of complex features by supporting the core building blocks of chat interaction: model interfacing, chat management, and robust function calling. All Kani core functions are easily overridable and well documented to empower developers to customize functionality for their own needs. Kani thus serves as a useful tool for researchers, hobbyists, and industry professionals alike to accelerate their development while retaining interoperability and fine-grained control.
Large Language Models as Sous Chefs: Revising Recipes with GPT-3
Jun 24, 2023


With their remarkably improved text generation and prompting capabilities, large language models can adapt existing written information into forms that are easier to use and understand. In our work, we focus on recipes as an example of complex, diverse, and widely used instructions. We develop a prompt grounded in the original recipe and ingredients list that breaks recipes down into simpler steps. We apply this prompt to recipes from various world cuisines, and experiment with several large language models (LLMs), finding best results with GPT-3.5. We also contribute an Amazon Mechanical Turk task that is carefully designed to reduce fatigue while collecting human judgment of the quality of recipe revisions. We find that annotators usually prefer the revision over the original, demonstrating a promising application of LLMs in serving as digital sous chefs for recipes and beyond. We release our prompt, code, and MTurk template for public use.
AMPERSAND: Argument Mining for PERSuAsive oNline Discussions
Apr 30, 2020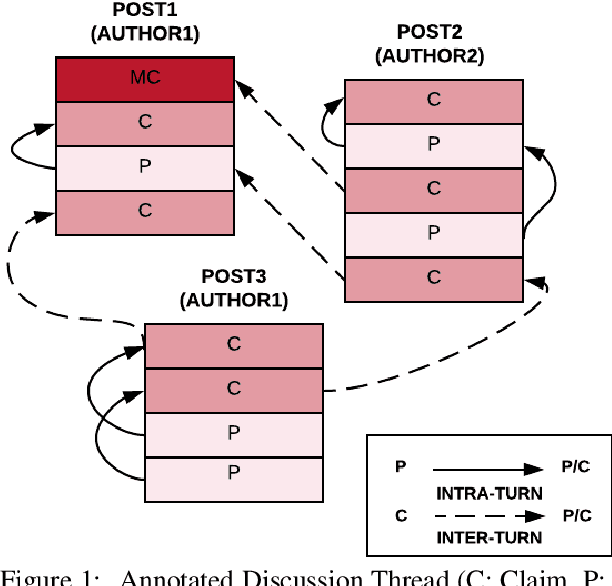

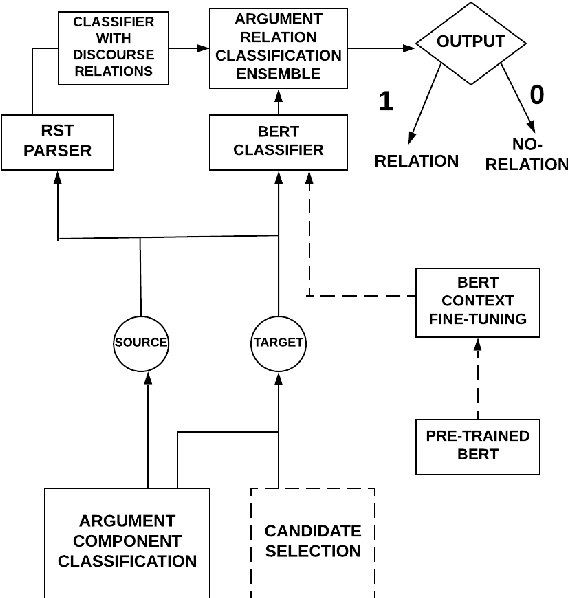
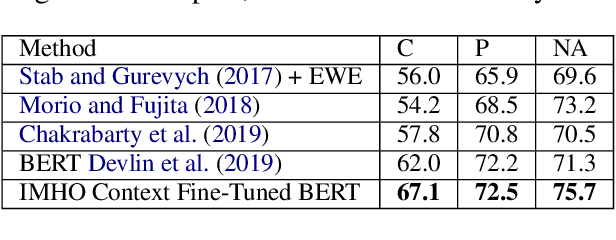
Argumentation is a type of discourse where speakers try to persuade their audience about the reasonableness of a claim by presenting supportive arguments. Most work in argument mining has focused on modeling arguments in monologues. We propose a computational model for argument mining in online persuasive discussion forums that brings together the micro-level (argument as product) and macro-level (argument as process) models of argumentation. Fundamentally, this approach relies on identifying relations between components of arguments in a discussion thread. Our approach for relation prediction uses contextual information in terms of fine-tuning a pre-trained language model and leveraging discourse relations based on Rhetorical Structure Theory. We additionally propose a candidate selection method to automatically predict what parts of one's argument will be targeted by other participants in the discussion. Our models obtain significant improvements compared to recent state-of-the-art approaches using pointer networks and a pre-trained language model.