 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Distilling Knowledge Priors from Literature for Therapeutic Design
Aug 14, 2025AI-driven discovery can greatly reduce design time and enhance new therapeutics' effectiveness. Models using simulators explore broad design spaces but risk violating implicit constraints due to a lack of experimental priors. For example, in a new analysis we performed on a diverse set of models on the GuacaMol benchmark using supervised classifiers, over 60\% of molecules proposed had high probability of being mutagenic. In this work, we introduce \ourdataset, a dataset of priors for design problems extracted from literature describing compounds used in lab settings. It is constructed with LLM pipelines for discovering therapeutic entities in relevant paragraphs and summarizing information in concise fair-use facts. \ourdataset~ consists of 32.3 million pairs of natural language facts, and appropriate entity representations (i.e. SMILES or refseq IDs). To demonstrate the potential of the data, we train LLM, CLIP, and LLava architectures to reason jointly about text and design targets and evaluate on tasks from the Therapeutic Data Commons (TDC). \ourdataset~is highly effective for creating models with strong priors: in supervised prediction problems that use our data as pretraining, our best models with 15M learnable parameters outperform larger 2B TxGemma on both regression and classification TDC tasks, and perform comparably to 9B models on average. Models built with \ourdataset~can be used as constraints while optimizing for novel molecules in GuacaMol, resulting in proposals that are safer and nearly as effective. We release our dataset at \href{https://huggingface.co/datasets/medexanon/Medex}{huggingface.co/datasets/medexanon/Medex}, and will provide expanded versions as available literature grows.
RAID: A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
May 13, 2024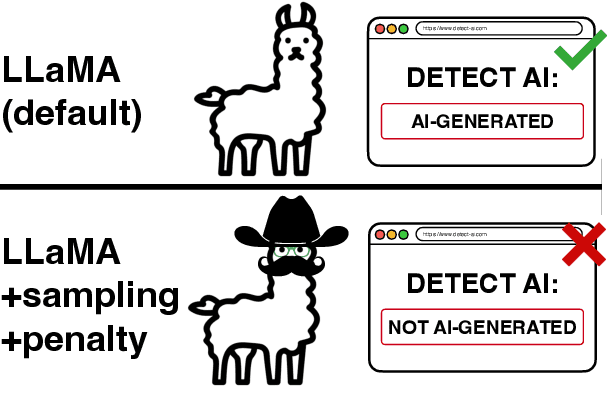
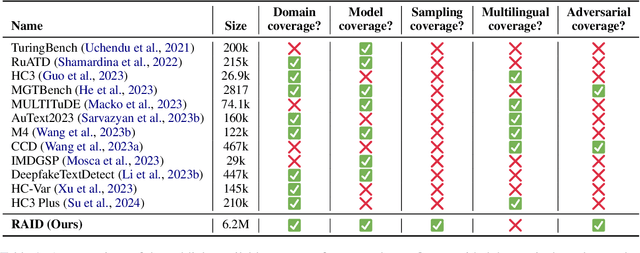
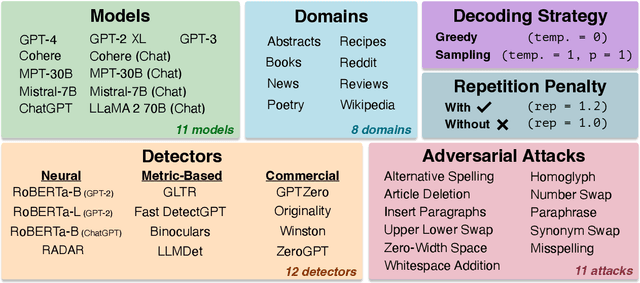

Many commercial and open-source models claim to detect machine-generated text with very high accuracy (99\% or higher). However, very few of these detectors are evaluated on shared benchmark datasets and even when they are, the datasets used for evaluation are insufficiently challenging -- lacking variations in sampling strategy, adversarial attacks, and open-source generative models. In this work we present RAID: the largest and most challenging benchmark dataset for machine-generated text detection. RAID includes over 6 million generations spanning 11 models, 8 domains, 11 adversarial attacks and 4 decoding strategies. Using RAID, we evaluate the out-of-domain and adversarial robustness of 8 open- and 4 closed-source detectors and find that current detectors are easily fooled by adversarial attacks, variations in sampling strategies, repetition penalties, and unseen generative models. We release our dataset and tools to encourage further exploration into detector robustness.
Interpretable-by-Design Text Classification with Iteratively Generated Concept Bottleneck
Oct 30, 2023
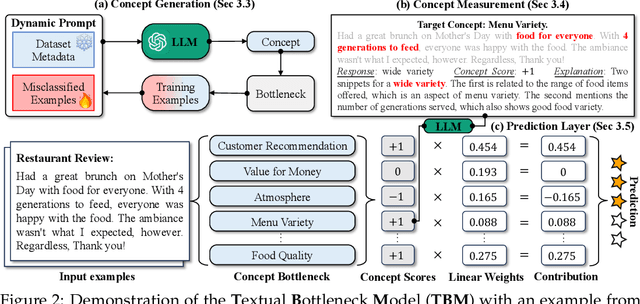

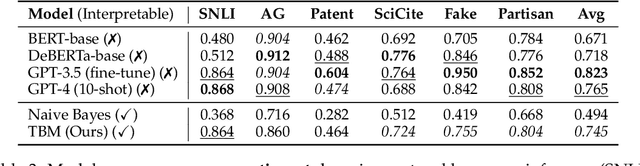
Deep neural networks excel in text classification tasks, yet their application in high-stakes domains is hindered by their lack of interpretability. To address this, we propose Text Bottleneck Models (TBMs), an intrinsically interpretable text classification framework that offers both global and local explanations. Rather than directly predicting the output label, TBMs predict categorical values for a sparse set of salient concepts and use a linear layer over those concept values to produce the final prediction. These concepts can be automatically discovered and measured by a Large Language Model (LLM), without the need for human curation. On 12 diverse datasets, using GPT-4 for both concept generation and measurement, we show that TBMs can rival the performance of established black-box baselines such as GPT-4 fewshot and finetuned DeBERTa, while falling short against finetuned GPT-3.5. Overall, our findings suggest that TBMs are a promising new framework that enhances interpretability, with minimal performance tradeoffs, particularly for general-domain text.
Explanation-based Finetuning Makes Models More Robust to Spurious Cues
May 08, 2023Large Language Models (LLMs) are so powerful that they sometimes learn correlations between labels and features that are irrelevant to the task, leading to poor generalization on out-of-distribution data. We propose explanation-based finetuning as a novel and general approach to mitigate LLMs' reliance on spurious correlations. Unlike standard finetuning where the model only predicts the answer given the input, we finetune the model to additionally generate a free-text explanation supporting its answer. To evaluate our method, we finetune the model on artificially constructed training sets containing different types of spurious cues, and test it on a test set without these cues. Compared to standard finetuning, our method makes models remarkably more robust against spurious cues in terms of accuracy drop across four classification tasks: ComVE (+1.2), CREAK (+9.1), e-SNLI (+15.4), and SBIC (+6.5). Moreover, our method works equally well with explanations generated by the model, implying its applicability to more datasets without human-written explanations.