 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI-to-CT synthesis using drifting models
Mar 30, 2026Accurate MRI-to-CT synthesis could enable MR-only pelvic workflows by providing CT-like images with bone details while avoiding additional ionizing radiation. In this work, we investigate recently proposed drifting models for synthesizing pelvis CT images from MRI and benchmark them against convolutional neural networks (UNet, VAE), a generative adversarial network (WGAN-GP), a physics-inspired probabilistic model (PPFM), and diffusion-based methods (FastDDPM, DDIM, DDPM). Experiments are performed on two complementary datasets: Gold Atlas Male Pelvis and the SynthRAD2023 pelvis subset. Image fidelity and structural consistency are evaluated with SSIM, PSNR, and RMSE, complemented by qualitative assessment of anatomically critical regions such as cortical bone and pelvic soft-tissue interfaces. Across both datasets, the proposed drifting model achieves high SSIM and PSNR and low RMSE, surpassing strong diffusion baselines and conventional CNN-, VAE-, GAN-, and PPFM-based methods. Visual inspection shows sharper cortical bone edges, improved depiction of sacral and femoral head geometry, and reduced artifacts or over-smoothing, particularly at bone-air-soft tissue boundaries. Moreover, the drifting model attains these gains with one-step inference and inference times on the order of milliseconds, yielding a more favorable accuracy-efficiency trade-off than iterative diffusion sampling while remaining competitive in image quality. These findings suggest that drifting models are a promising direction for fast, high-quality pelvic synthetic CT generation from MRI and warrant further investigation for downstream applications such as MRI-only radiotherapy planning and PET/MR attenuation correction.
Unsupervised Anomaly Detection in Multi-Agent Trajectory Prediction via Transformer-Based Models
Jan 28, 2026Identifying safety-critical scenarios is essential for autonomous driving, but the rarity of such events makes supervised labeling impractical. Traditional rule-based metrics like Time-to-Collision are too simplistic to capture complex interaction risks, and existing methods lack a systematic way to verify whether statistical anomalies truly reflect physical danger. To address this gap, we propose an unsupervised anomaly detection framework based on a multi-agent Transformer that models normal driving and measures deviations through prediction residuals. A dual evaluation scheme has been proposed to assess both detection stability and physical alignment: Stability is measured using standard ranking metrics in which Kendall Rank Correlation Coefficient captures rank agreement and Jaccard index captures the consistency of the top-K selected items; Physical alignment is assessed through correlations with established Surrogate Safety Measures (SSM). Experiments on the NGSIM dataset demonstrate our framework's effectiveness: We show that the maximum residual aggregator achieves the highest physical alignment while maintaining stability. Furthermore, our framework identifies 388 unique anomalies missed by Time-to-Collision and statistical baselines, capturing subtle multi-agent risks like reactive braking under lateral drift. The detected anomalies are further clustered into four interpretable risk types, offering actionable insights for simulation and testing.
MCR-VQGAN: A Scalable and Cost-Effective Tau PET Synthesis Approach for Alzheimer's Disease Imaging
Dec 17, 2025
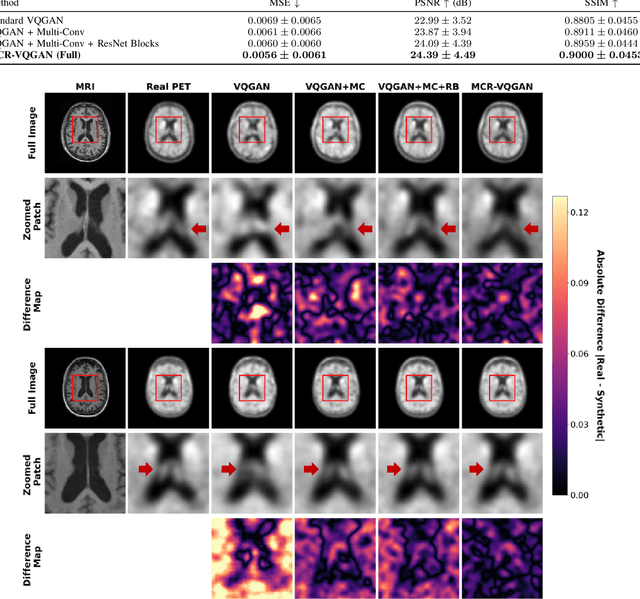


Tau positron emission tomography (PET) is a critical diagnostic modality for Alzheimer's disease (AD) because it visualizes and quantifies neurofibrillary tangles, a hallmark of AD pathology. However, its widespread clinical adoption is hindered by significant challenges, such as radiation exposure, limited availability, high clinical workload, and substantial financial costs. To overcome these limitations, we propose Multi-scale CBAM Residual Vector Quantized Generative Adversarial Network (MCR-VQGAN) to synthesize high-fidelity tau PET images from structural T1-weighted MRI scans. MCR-VQGAN improves standard VQGAN by integrating three key architectural enhancements: multi-scale convolutions, ResNet blocks, and Convolutional Block Attention Modules (CBAM). Using 222 paired structural T1-weighted MRI and tau PET scans from Alzheimer's Disease Neuroimaging Initiative (ADNI), we trained and compared MCR-VQGAN with cGAN, WGAN-GP, CycleGAN, and VQGAN. Our proposed model achieved superior image synthesis performance across all metrics: MSE of 0.0056 +/- 0.0061, PSNR of 24.39 +/- 4.49 dB, and SSIM of 0.9000 +/- 0.0453. To assess the clinical utility of the synthetic images, we trained and evaluated a CNN-based AD classifier. The classifier achieved comparable accuracy when tested on real (63.64%) and synthetic (65.91%) images. This result indicates that our synthesis process successfully preserves diagnostically relevant features without significant information loss. Our results demonstrate that MCR-VQGAN can offer a reliable and scalable surrogate for conventional tau PET imaging, potentially improving the accessibility and scalability of tau imaging biomarkers for AD research and clinical workflows.
Joint Beamforming and Integer User Association using a GNN with Gumbel-Softmax Reparameterizations
Jun 05, 2025

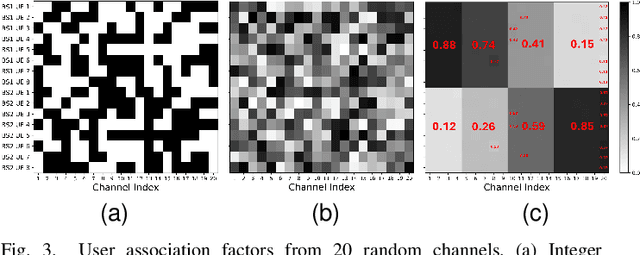

Machine learning (ML) models can effectively optimize a multi-cell wireless network by designing the beamforming vectors and association decisions. Existing ML designs, however, often needs to approximate the integer association variables with a probability distribution output. We propose a novel graph neural network (GNN) structure that jointly optimize beamforming vectors and user association while guaranteeing association output as integers. The integer association constraints are satisfied using the Gumbel-Softmax (GS) reparameterization, without increasing computational complexity. Simulation results demonstrate that our proposed GS-based GNN consistently achieves integer association decisions and yields a higher sum-rate, especially when generalized to larger networks, compared to all other fractional association methods.
Nonhuman Primate Brain Tissue Segmentation Using a Transfer Learning Approach
Apr 01, 2025Non-human primates (NHPs) serve as critical models for understanding human brain function and neurological disorders due to their close evolutionary relationship with humans. Accurate brain tissue segmentation in NHPs is critical for understanding neurological disorders, but challenging due to the scarcity of annotated NHP brain MRI datasets, the small size of the NHP brain, the limited resolution of available imaging data and the anatomical differences between human and NHP brains. To address these challenges, we propose a novel approach utilizing STU-Net with transfer learning to leverage knowledge transferred from human brain MRI data to enhance segmentation accuracy in the NHP brain MRI, particularly when training data is limited. The combination of STU-Net and transfer learning effectively delineates complex tissue boundaries and captures fine anatomical details specific to NHP brains. Notably, our method demonstrated improvement in segmenting small subcortical structures such as putamen and thalamus that are challenging to resolve with limited spatial resolution and tissue contrast, and achieved DSC of over 0.88, IoU over 0.8 and HD95 under 7. This study introduces a robust method for multi-class brain tissue segmentation in NHPs, potentially accelerating research in evolutionary neuroscience and preclinical studies of neurological disorders relevant to human health.
Synthesizing beta-amyloid PET images from T1-weighted Structural MRI: A Preliminary Study
Sep 26, 2024


Beta-amyloid positron emission tomography (A$\beta$-PET) imaging has become a critical tool in Alzheimer's disease (AD) research and diagnosis, providing insights into the pathological accumulation of amyloid plaques, one of the hallmarks of AD. However, the high cost, limited availability, and exposure to radioactivity restrict the widespread use of A$\beta$-PET imaging, leading to a scarcity of comprehensive datasets. Previous studies have suggested that structural magnetic resonance imaging (MRI), which is more readily available, may serve as a viable alternative for synthesizing A$\beta$-PET images. In this study, we propose an approach to utilize 3D diffusion models to synthesize A$\beta$-PET images from T1-weighted MRI scans, aiming to overcome the limitations associated with direct PET imaging. Our method generates high-quality A$\beta$-PET images for cognitive normal cases, although it is less effective for mild cognitive impairment (MCI) patients due to the variability in A$\beta$ deposition patterns among subjects. Our preliminary results suggest that incorporating additional data, such as a larger sample of MCI cases and multi-modality information including clinical and demographic details, cognitive and functional assessments, and longitudinal data, may be necessary to improve A$\beta$-PET image synthesis for MCI patients.
Cross-Institutional Structured Radiology Reporting for Lung Cancer Screening Using a Dynamic Template-Constrained Large Language Model
Sep 26, 2024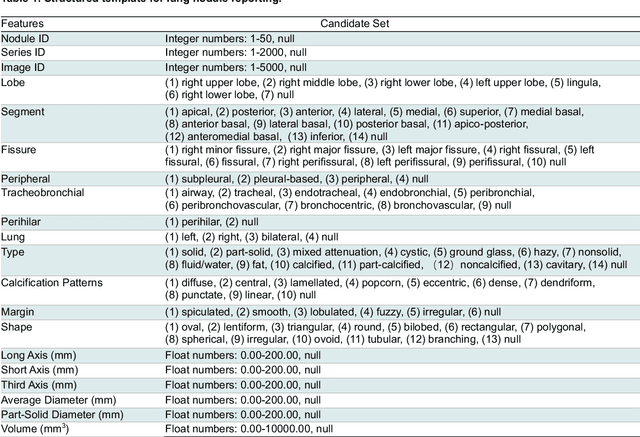
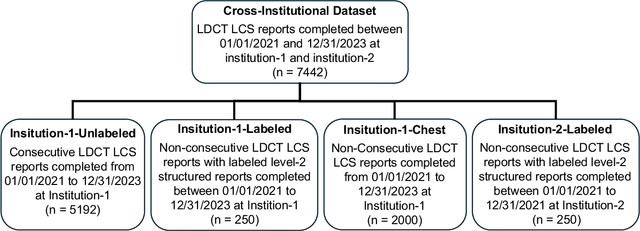
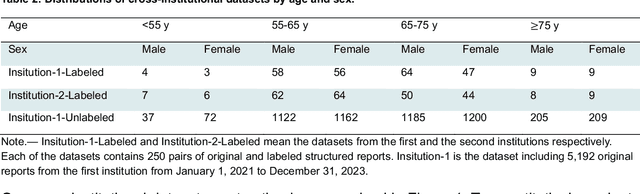
Structured radiology reporting is advantageous for optimizing clinical workflows and patient outcomes. Current LLMs in creating structured reports face the challenges of formatting errors, content hallucinations, and privacy leakage concerns when uploaded to external servers. We aim to develop an enhanced open-source LLM for creating structured and standardized LCS reports from free-text descriptions. After institutional IRB approvals, 5,442 de-identified LCS reports from two institutions were retrospectively analyzed. 500 reports were randomly selected from the two institutions evenly and then manually labeled for evaluation. Two radiologists from the two institutions developed a standardized template including 29 features for lung nodule reporting. We proposed template-constrained decoding to enhance state-of-the-art open-source LLMs, including LLAMA, Qwen, and Mistral. The LLM performance was extensively evaluated in terms of F1 score, confidence interval, McNemar test, and z-test. Based on the structured reports created from the large-scale dataset, a nodule-level retrieval system was prototyped and an automatic statistical analysis was performed. Our software, vLLM-structure, is publicly available for local deployment with enhanced LLMs. Our template-constrained decoding approach consistently enhanced the LLM performance on multi-institutional datasets, with neither formatting errors nor content hallucinations. Our method improved the best open-source LLAMA-3.1 405B by up to 10.42%, and outperformed GPT-4o by 17.19%. A novel nodule retrieval system was successfully prototyped and demonstrated on a large-scale multimodal database using our enhanced LLM technologies. The automatically derived statistical distributions were closely consistent with the prior findings in terms of nodule type, location, size, status, and Lung-RADS.
Avoiding Copyright Infringement via Machine Unlearning
Jun 16, 2024Pre-trained Large Language Models (LLMs) have demonstrated remarkable capabilities but also pose risks by learning and generating copyrighted material, leading to significant legal and ethical concerns. To address these issues, it is critical for model owners to be able to unlearn copyrighted content at various time steps. We explore the setting of sequential unlearning, where copyrighted content is removed over multiple time steps - a scenario that has not been rigorously addressed. To tackle this challenge, we propose Stable Sequential Unlearning (SSU), a novel unlearning framework for LLMs, designed to have a more stable process to remove copyrighted content from LLMs throughout different time steps using task vectors, by incorporating additional random labeling loss and applying gradient-based weight saliency mapping. Experiments demonstrate that SSU finds a good balance between unlearning efficacy and maintaining the model's general knowledge compared to existing baselines.
Calibrating Large Language Models with Sample Consistency
Feb 21, 2024Accurately gauging the confidence level of Large Language Models' (LLMs) predictions is pivotal for their reliable application. However, LLMs are often uncalibrated inherently and elude conventional calibration techniques due to their proprietary nature and massive scale. In this work, we explore the potential of deriving confidence from the distribution of multiple randomly sampled model generations, via three measures of consistency. We perform an extensive evaluation across various open and closed-source models on nine reasoning datasets. Results show that consistency-based calibration methods outperform existing post-hoc approaches. Meanwhile, we find that factors such as intermediate explanations, model scaling, and larger sample sizes enhance calibration, while instruction-tuning makes calibration more difficult. Moreover, confidence scores obtained from consistency have the potential to enhance model performance. Finally, we offer practical guidance on choosing suitable consistency metrics for calibration, tailored to the characteristics of various LMs.
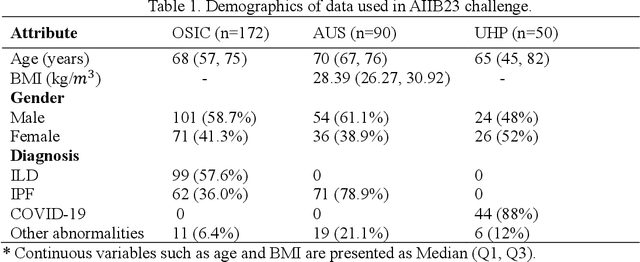
Hunting imaging biomarkers in pulmonary fibrosis: Benchmarks of the AIIB23 challenge
Dec 21, 2023
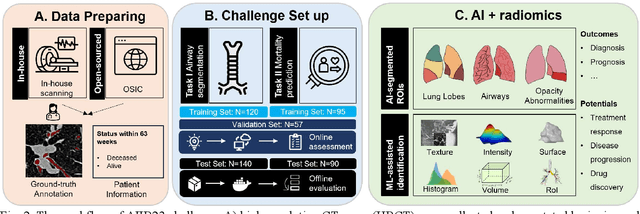
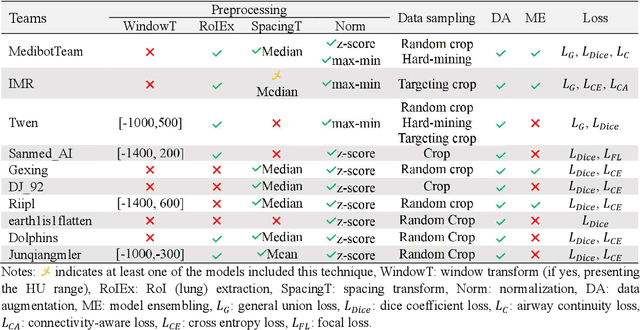
Airway-related quantitative imaging biomarkers are crucial for examination, diagnosis, and prognosis in pulmonary diseases. However, the manual delineation of airway trees remains prohibitively time-consuming. While significant efforts have been made towards enhancing airway modelling, current public-available datasets concentrate on lung diseases with moderate morphological variations. The intricate honeycombing patterns present in the lung tissues of fibrotic lung disease patients exacerbate the challenges, often leading to various prediction errors. To address this issue, the 'Airway-Informed Quantitative CT Imaging Biomarker for Fibrotic Lung Disease 2023' (AIIB23) competition was organized in conjunction with the official 2023 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI). The airway structures were meticulously annotated by three experienced radiologists. Competitors were encouraged to develop automatic airway segmentation models with high robustness and generalization abilities, followed by exploring the most correlated QIB of mortality prediction. A training set of 120 high-resolution computerised tomography (HRCT) scans were publicly released with expert annotations and mortality status. The online validation set incorporated 52 HRCT scans from patients with fibrotic lung disease and the offline test set included 140 cases from fibrosis and COVID-19 patients. The results have shown that the capacity of extracting airway trees from patients with fibrotic lung disease could be enhanced by introducing voxel-wise weighted general union loss and continuity loss. In addition to the competitive image biomarkers for prognosis, a strong airway-derived biomarker (Hazard ratio>1.5, p<0.0001) was revealed for survival prognostication compared with existing clinical measurements, clinician assessment and AI-based biomarkers.