 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFigure: Generating and Refining Publication-Ready Scientific Illustrations
Feb 03, 2026High-quality scientific illustrations are crucial for effectively communicating complex scientific and technical concepts, yet their manual creation remains a well-recognized bottleneck in both academia and industry. We present FigureBench, the first large-scale benchmark for generating scientific illustrations from long-form scientific texts. It contains 3,300 high-quality scientific text-figure pairs, covering diverse text-to-illustration tasks from scientific papers, surveys, blogs, and textbooks. Moreover, we propose AutoFigure, the first agentic framework that automatically generates high-quality scientific illustrations based on long-form scientific text. Specifically, before rendering the final result, AutoFigure engages in extensive thinking, recombination, and validation to produce a layout that is both structurally sound and aesthetically refined, outputting a scientific illustration that achieves both structural completeness and aesthetic appeal. Leveraging the high-quality data from FigureBench, we conduct extensive experiments to test the performance of AutoFigure against various baseline methods. The results demonstrate that AutoFigure consistently surpasses all baseline methods, producing publication-ready scientific illustrations. The code, dataset and huggingface space are released in https://github.com/ResearAI/AutoFigure.
DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively
Sep 30, 2025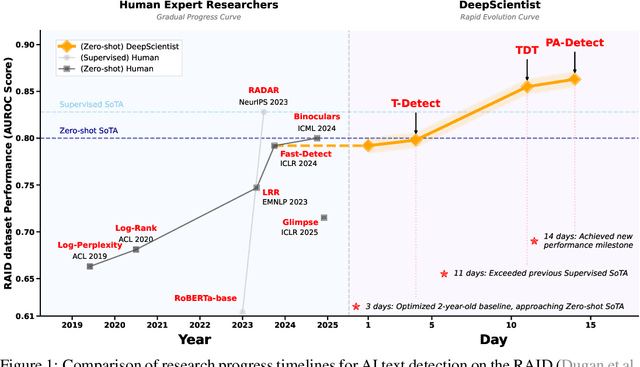

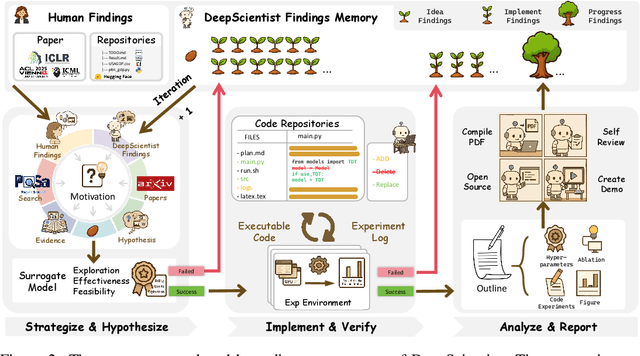
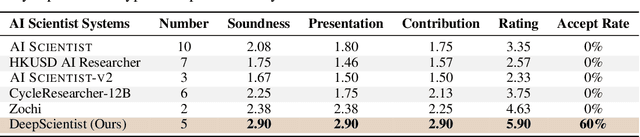
While previous AI Scientist systems can generate novel findings, they often lack the focus to produce scientifically valuable contributions that address pressing human-defined challenges. We introduce DeepScientist, a system designed to overcome this by conducting goal-oriented, fully autonomous scientific discovery over month-long timelines. It formalizes discovery as a Bayesian Optimization problem, operationalized through a hierarchical evaluation process consisting of "hypothesize, verify, and analyze". Leveraging a cumulative Findings Memory, this loop intelligently balances the exploration of novel hypotheses with exploitation, selectively promoting the most promising findings to higher-fidelity levels of validation. Consuming over 20,000 GPU hours, the system generated about 5,000 unique scientific ideas and experimentally validated approximately 1100 of them, ultimately surpassing human-designed state-of-the-art (SOTA) methods on three frontier AI tasks by 183.7\%, 1.9\%, and 7.9\%. This work provides the first large-scale evidence of an AI achieving discoveries that progressively surpass human SOTA on scientific tasks, producing valuable findings that genuinely push the frontier of scientific discovery. To facilitate further research into this process, we will open-source all experimental logs and system code at https://github.com/ResearAI/DeepScientist/.
MICACL: Multi-Instance Category-Aware Contrastive Learning for Long-Tailed Dynamic Facial Expression Recognition
Sep 04, 2025



Dynamic facial expression recognition (DFER) faces significant challenges due to long-tailed category distributions and complexity of spatio-temporal feature modeling. While existing deep learning-based methods have improved DFER performance, they often fail to address these issues, resulting in severe model induction bias. To overcome these limitations, we propose a novel multi-instance learning framework called MICACL, which integrates spatio-temporal dependency modeling and long-tailed contrastive learning optimization. Specifically, we design the Graph-Enhanced Instance Interaction Module (GEIIM) to capture intricate spatio-temporal between adjacent instances relationships through adaptive adjacency matrices and multiscale convolutions. To enhance instance-level feature aggregation, we develop the Weighted Instance Aggregation Network (WIAN), which dynamically assigns weights based on instance importance. Furthermore, we introduce a Multiscale Category-aware Contrastive Learning (MCCL) strategy to balance training between major and minor categories. Extensive experiments on in-the-wild datasets (i.e., DFEW and FERV39k) demonstrate that MICACL achieves state-of-the-art performance with superior robustness and generalization.
Nonhuman Primate Brain Tissue Segmentation Using a Transfer Learning Approach
Apr 01, 2025Non-human primates (NHPs) serve as critical models for understanding human brain function and neurological disorders due to their close evolutionary relationship with humans. Accurate brain tissue segmentation in NHPs is critical for understanding neurological disorders, but challenging due to the scarcity of annotated NHP brain MRI datasets, the small size of the NHP brain, the limited resolution of available imaging data and the anatomical differences between human and NHP brains. To address these challenges, we propose a novel approach utilizing STU-Net with transfer learning to leverage knowledge transferred from human brain MRI data to enhance segmentation accuracy in the NHP brain MRI, particularly when training data is limited. The combination of STU-Net and transfer learning effectively delineates complex tissue boundaries and captures fine anatomical details specific to NHP brains. Notably, our method demonstrated improvement in segmenting small subcortical structures such as putamen and thalamus that are challenging to resolve with limited spatial resolution and tissue contrast, and achieved DSC of over 0.88, IoU over 0.8 and HD95 under 7. This study introduces a robust method for multi-class brain tissue segmentation in NHPs, potentially accelerating research in evolutionary neuroscience and preclinical studies of neurological disorders relevant to human health.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.
MCQA-Eval: Efficient Confidence Evaluation in NLG with Gold-Standard Correctness Labels
Feb 20, 2025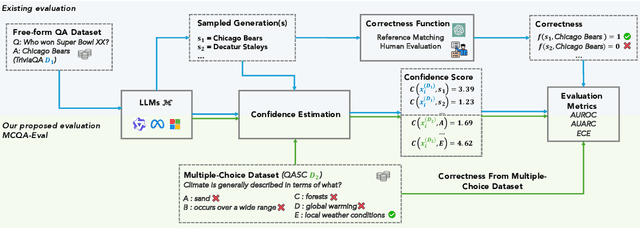
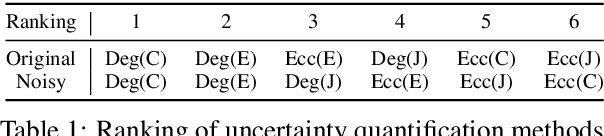
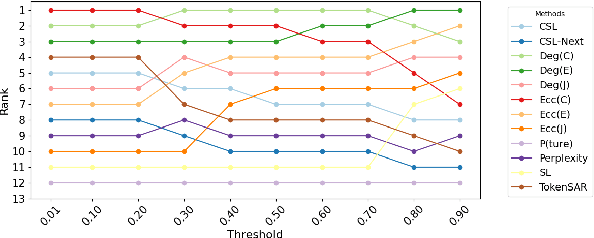

Large Language Models (LLMs) require robust confidence estimation, particularly in critical domains like healthcare and law where unreliable outputs can lead to significant consequences. Despite much recent work in confidence estimation, current evaluation frameworks rely on correctness functions -- various heuristics that are often noisy, expensive, and possibly introduce systematic biases. These methodological weaknesses tend to distort evaluation metrics and thus the comparative ranking of confidence measures. We introduce MCQA-Eval, an evaluation framework for assessing confidence measures in Natural Language Generation (NLG) that eliminates dependence on an explicit correctness function by leveraging gold-standard correctness labels from multiple-choice datasets. MCQA-Eval enables systematic comparison of both internal state-based white-box (e.g. logit-based) and consistency-based black-box confidence measures, providing a unified evaluation methodology across different approaches. Through extensive experiments on multiple LLMs and widely used QA datasets, we report that MCQA-Eval provides efficient and more reliable assessments of confidence estimation methods than existing approaches.
Certifiably Byzantine-Robust Federated Conformal Prediction
Jun 04, 2024



Conformal prediction has shown impressive capacity in constructing statistically rigorous prediction sets for machine learning models with exchangeable data samples. The siloed datasets, coupled with the escalating privacy concerns related to local data sharing, have inspired recent innovations extending conformal prediction into federated environments with distributed data samples. However, this framework for distributed uncertainty quantification is susceptible to Byzantine failures. A minor subset of malicious clients can significantly compromise the practicality of coverage guarantees. To address this vulnerability, we introduce a novel framework Rob-FCP, which executes robust federated conformal prediction, effectively countering malicious clients capable of reporting arbitrary statistics with the conformal calibration process. We theoretically provide the conformal coverage bound of Rob-FCP in the Byzantine setting and show that the coverage of Rob-FCP is asymptotically close to the desired coverage level. We also propose a malicious client number estimator to tackle a more challenging setting where the number of malicious clients is unknown to the defender and theoretically shows its effectiveness. We empirically demonstrate the robustness of Rob-FCP against diverse proportions of malicious clients under a variety of Byzantine attacks on five standard benchmark and real-world healthcare datasets.
Contextualized Sequence Likelihood: Enhanced Confidence Scores for Natural Language Generation
Jun 03, 2024


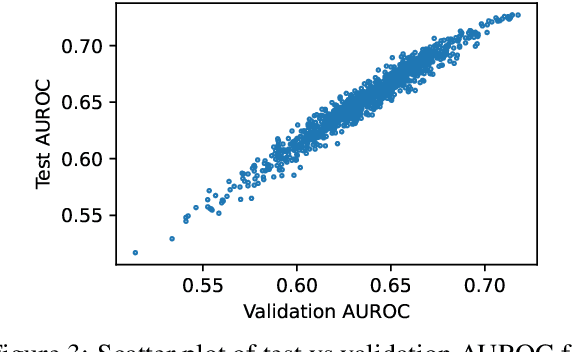
The advent of large language models (LLMs) has dramatically advanced the state-of-the-art in numerous natural language generation tasks. For LLMs to be applied reliably, it is essential to have an accurate measure of their confidence. Currently, the most commonly used confidence score function is the likelihood of the generated sequence, which, however, conflates semantic and syntactic components. For instance, in question-answering (QA) tasks, an awkward phrasing of the correct answer might result in a lower probability prediction. Additionally, different tokens should be weighted differently depending on the context. In this work, we propose enhancing the predicted sequence probability by assigning different weights to various tokens using attention values elicited from the base LLM. By employing a validation set, we can identify the relevant attention heads, thereby significantly improving the reliability of the vanilla sequence probability confidence measure. We refer to this new score as the Contextualized Sequence Likelihood (CSL). CSL is easy to implement, fast to compute, and offers considerable potential for further improvement with task-specific prompts. Across several QA datasets and a diverse array of LLMs, CSL has demonstrated significantly higher reliability than state-of-the-art baselines in predicting generation quality, as measured by the AUROC or AUARC.
Cross-Table Pretraining towards a Universal Function Space for Heterogeneous Tabular Data
Jun 01, 2024


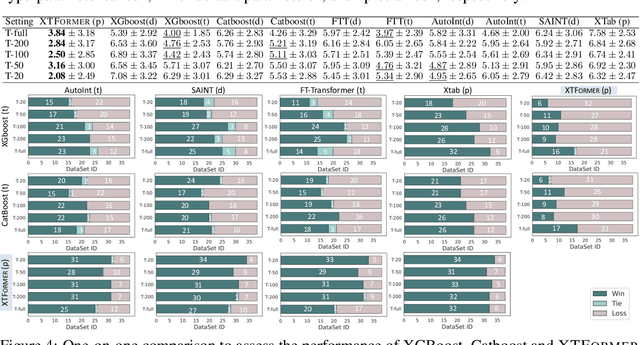
Tabular data from different tables exhibit significant diversity due to varied definitions and types of features, as well as complex inter-feature and feature-target relationships. Cross-dataset pretraining, which learns reusable patterns from upstream data to support downstream tasks, have shown notable success in various fields. Yet, when applied to tabular data prediction, this paradigm faces challenges due to the limited reusable patterns among diverse tabular datasets (tables) and the general scarcity of tabular data available for fine-tuning. In this study, we fill this gap by introducing a cross-table pretrained Transformer, XTFormer, for versatile downstream tabular prediction tasks. Our methodology insight is pretraining XTFormer to establish a "meta-function" space that encompasses all potential feature-target mappings. In pre-training, a variety of potential mappings are extracted from pre-training tabular datasets and are embedded into the "meta-function" space, and suited mappings are extracted from the "meta-function" space for downstream tasks by a specified coordinate positioning approach. Experiments show that, in 190 downstream tabular prediction tasks, our cross-table pretrained XTFormer wins both XGBoost and Catboost on 137 (72%) tasks, and surpasses representative deep learning models FT-Transformer and the tabular pre-training approach XTab on 144 (76%) and 162 (85%) tasks.
Conformal Drug Property Prediction with Density Estimation under Covariate Shift
Oct 18, 2023In drug discovery, it is vital to confirm the predictions of pharmaceutical properties from computational models using costly wet-lab experiments. Hence, obtaining reliable uncertainty estimates is crucial for prioritizing drug molecules for subsequent experimental validation. Conformal Prediction (CP) is a promising tool for creating such prediction sets for molecular properties with a coverage guarantee. However, the exchangeability assumption of CP is often challenged with covariate shift in drug discovery tasks: Most datasets contain limited labeled data, which may not be representative of the vast chemical space from which molecules are drawn. To address this limitation, we propose a method called CoDrug that employs an energy-based model leveraging both training data and unlabelled data, and Kernel Density Estimation (KDE) to assess the densities of a molecule set. The estimated densities are then used to weigh the molecule samples while building prediction sets and rectifying for distribution shift. In extensive experiments involving realistic distribution drifts in various small-molecule drug discovery tasks, we demonstrate the ability of CoDrug to provide valid prediction sets and its utility in addressing the distribution shift arising from de novo drug design models. On average, using CoDrug can reduce the coverage gap by over 35% when compared to conformal prediction sets not adjusted for covariate shift.