 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating with Confidence: Uncertainty Quantification for Black-box Large Language Models
Paper and Code

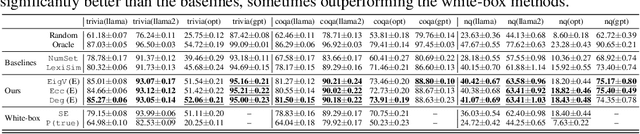
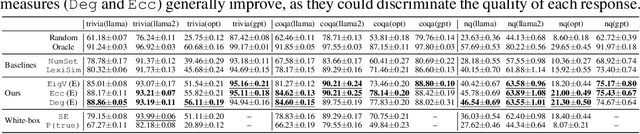
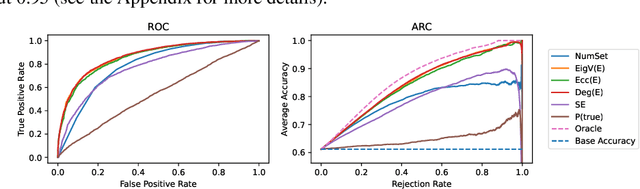
Large language models (LLMs) specializing in natural language generation (NLG) have recently started exhibiting promising capabilities across a variety of domains. However, gauging the trustworthiness of responses generated by LLMs remains an open challenge, with limited research on uncertainty quantification for NLG. Furthermore, existing literature typically assumes white-box access to language models, which is becoming unrealistic either due to the closed-source nature of the latest LLMs or due to computational constraints. In this work, we investigate uncertainty quantification in NLG for $\textit{black-box}$ LLMs. We first differentiate two closely-related notions: $\textit{uncertainty}$, which depends only on the input, and $\textit{confidence}$, which additionally depends on the generated response. We then propose and compare several confidence/uncertainty metrics, applying them to $\textit{selective NLG}$, where unreliable results could either be ignored or yielded for further assessment. Our findings on several popular LLMs and datasets reveal that a simple yet effective metric for the average semantic dispersion can be a reliable predictor of the quality of LLM responses. This study can provide valuable insights for practitioners on uncertainty management when adopting LLMs. The code to replicate all our experiments is available at https://github.com/zlin7/UQ-NLG.