 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: A Clinically-Grounded Tabular Framework for Radiology Report Evaluation
May 22, 2025



Existing metrics often lack the granularity and interpretability to capture nuanced clinical differences between candidate and ground-truth radiology reports, resulting in suboptimal evaluation. We introduce a Clinically-grounded tabular framework with Expert-curated labels and Attribute-level comparison for Radiology report evaluation (CLEAR). CLEAR not only examines whether a report can accurately identify the presence or absence of medical conditions, but also assesses whether it can precisely describe each positively identified condition across five key attributes: first occurrence, change, severity, descriptive location, and recommendation. Compared to prior works, CLEAR's multi-dimensional, attribute-level outputs enable a more comprehensive and clinically interpretable evaluation of report quality. Additionally, to measure the clinical alignment of CLEAR, we collaborate with five board-certified radiologists to develop CLEAR-Bench, a dataset of 100 chest X-ray reports from MIMIC-CXR, annotated across 6 curated attributes and 13 CheXpert conditions. Our experiments show that CLEAR achieves high accuracy in extracting clinical attributes and provides automated metrics that are strongly aligned with clinical judgment.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.
MCQA-Eval: Efficient Confidence Evaluation in NLG with Gold-Standard Correctness Labels
Feb 20, 2025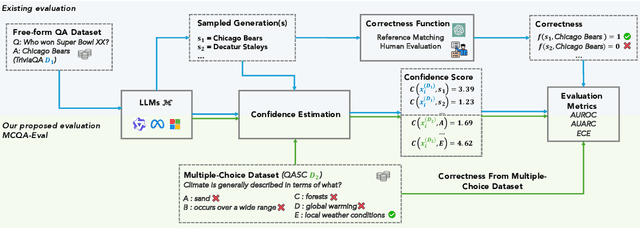
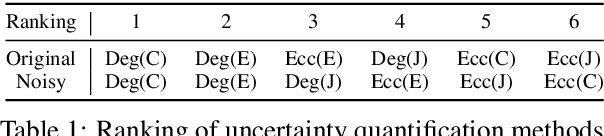
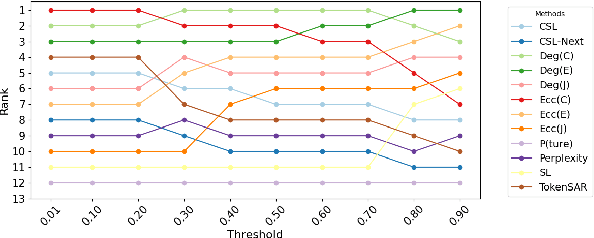

Large Language Models (LLMs) require robust confidence estimation, particularly in critical domains like healthcare and law where unreliable outputs can lead to significant consequences. Despite much recent work in confidence estimation, current evaluation frameworks rely on correctness functions -- various heuristics that are often noisy, expensive, and possibly introduce systematic biases. These methodological weaknesses tend to distort evaluation metrics and thus the comparative ranking of confidence measures. We introduce MCQA-Eval, an evaluation framework for assessing confidence measures in Natural Language Generation (NLG) that eliminates dependence on an explicit correctness function by leveraging gold-standard correctness labels from multiple-choice datasets. MCQA-Eval enables systematic comparison of both internal state-based white-box (e.g. logit-based) and consistency-based black-box confidence measures, providing a unified evaluation methodology across different approaches. Through extensive experiments on multiple LLMs and widely used QA datasets, we report that MCQA-Eval provides efficient and more reliable assessments of confidence estimation methods than existing approaches.
GPT-4V Cannot Generate Radiology Reports Yet
Jul 16, 2024



GPT-4V's purported strong multimodal abilities raise interests in using it to automate radiology report writing, but there lacks thorough evaluations. In this work, we perform a systematic evaluation of GPT-4V in generating radiology reports on two chest X-ray report datasets: MIMIC-CXR and IU X-Ray. We attempt to directly generate reports using GPT-4V through different prompting strategies and find that it fails terribly in both lexical metrics and clinical efficacy metrics. To understand the low performance, we decompose the task into two steps: 1) the medical image reasoning step of predicting medical condition labels from images; and 2) the report synthesis step of generating reports from (groundtruth) conditions. We show that GPT-4V's performance in image reasoning is consistently low across different prompts. In fact, the distributions of model-predicted labels remain constant regardless of which groundtruth conditions are present on the image, suggesting that the model is not interpreting chest X-rays meaningfully. Even when given groundtruth conditions in report synthesis, its generated reports are less correct and less natural-sounding than a finetuned LLaMA-2. Altogether, our findings cast doubt on the viability of using GPT-4V in a radiology workflow.
Pragmatic Radiology Report Generation
Nov 28, 2023



When pneumonia is not found on a chest X-ray, should the report describe this negative observation or omit it? We argue that this question cannot be answered from the X-ray alone and requires a pragmatic perspective, which captures the communicative goal that radiology reports serve between radiologists and patients. However, the standard image-to-text formulation for radiology report generation fails to incorporate such pragmatic intents. Following this pragmatic perspective, we demonstrate that the indication, which describes why a patient comes for an X-ray, drives the mentions of negative observations and introduce indications as additional input to report generation. With respect to the output, we develop a framework to identify uninferable information from the image as a source of model hallucinations, and limit them by cleaning groundtruth reports. Finally, we use indications and cleaned groundtruth reports to develop pragmatic models, and show that they outperform existing methods not only in new pragmatics-inspired metrics (+4.3 Negative F1) but also in standard metrics (+6.3 Positive F1 and +11.0 BLEU-2).
Learning Human-Compatible Representations for Case-Based Decision Support
Mar 06, 2023
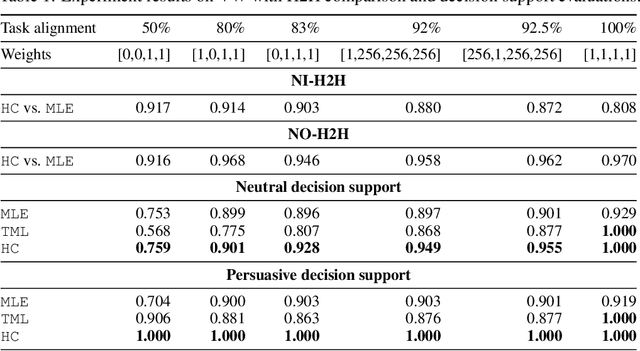


Algorithmic case-based decision support provides examples to help human make sense of predicted labels and aid human in decision-making tasks. Despite the promising performance of supervised learning, representations learned by supervised models may not align well with human intuitions: what models consider as similar examples can be perceived as distinct by humans. As a result, they have limited effectiveness in case-based decision support. In this work, we incorporate ideas from metric learning with supervised learning to examine the importance of alignment for effective decision support. In addition to instance-level labels, we use human-provided triplet judgments to learn human-compatible decision-focused representations. Using both synthetic data and human subject experiments in multiple classification tasks, we demonstrate that such representation is better aligned with human perception than representation solely optimized for classification. Human-compatible representations identify nearest neighbors that are perceived as more similar by humans and allow humans to make more accurate predictions, leading to substantial improvements in human decision accuracies (17.8% in butterfly vs. moth classification and 13.2% in pneumonia classification).
Contextual Dynamic Prompting for Response Generation in Task-oriented Dialog Systems
Feb 10, 2023



Response generation is one of the critical components in task-oriented dialog systems. Existing studies have shown that large pre-trained language models can be adapted to this task. The typical paradigm of adapting such extremely large language models would be by fine-tuning on the downstream tasks which is not only time-consuming but also involves significant resources and access to fine-tuning data. Prompting (Schick and Sch\"utze, 2020) has been an alternative to fine-tuning in many NLP tasks. In our work, we explore the idea of using prompting for response generation in task-oriented dialog systems. Specifically, we propose an approach that performs contextual dynamic prompting where the prompts are learnt from dialog contexts. We aim to distill useful prompting signals from the dialog context. On experiments with MultiWOZ 2.2 dataset (Zang et al., 2020), we show that contextual dynamic prompts improve response generation in terms of combined score (Mehri et al., 2019) by 3 absolute points, and a massive 20 points when dialog states are incorporated. Furthermore, human annotation on these conversations found that agents which incorporate context were preferred over agents with vanilla prefix-tuning.
Selective Explanations: Leveraging Human Input to Align Explainable AI
Jan 23, 2023



While a vast collection of explainable AI (XAI) algorithms have been developed in recent years, they are often criticized for significant gaps with how humans produce and consume explanations. As a result, current XAI techniques are often found to be hard to use and lack effectiveness. In this work, we attempt to close these gaps by making AI explanations selective -- a fundamental property of human explanations -- by selectively presenting a subset from a large set of model reasons based on what aligns with the recipient's preferences. We propose a general framework for generating selective explanations by leveraging human input on a small sample. This framework opens up a rich design space that accounts for different selectivity goals, types of input, and more. As a showcase, we use a decision-support task to explore selective explanations based on what the decision-maker would consider relevant to the decision task. We conducted two experimental studies to examine three out of a broader possible set of paradigms based on our proposed framework: in Study 1, we ask the participants to provide their own input to generate selective explanations, with either open-ended or critique-based input. In Study 2, we show participants selective explanations based on input from a panel of similar users (annotators). Our experiments demonstrate the promise of selective explanations in reducing over-reliance on AI and improving decision outcomes and subjective perceptions of the AI, but also paint a nuanced picture that attributes some of these positive effects to the opportunity to provide one's own input to augment AI explanations. Overall, our work proposes a novel XAI framework inspired by human communication behaviors and demonstrates its potentials to encourage future work to better align AI explanations with human production and consumption of explanations.
Machine Explanations and Human Understanding
Feb 08, 2022

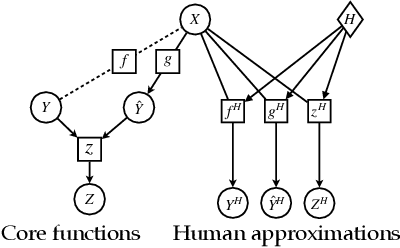

Explanations are hypothesized to improve human understanding of machine learning models and achieve a variety of desirable outcomes, ranging from model debugging to enhancing human decision making. However, empirical studies have found mixed and even negative results. An open question, therefore, is under what conditions explanations can improve human understanding and in what way. Using adapted causal diagrams, we provide a formal characterization of the interplay between machine explanations and human understanding, and show how human intuitions play a central role in enabling human understanding. Specifically, we identify three core concepts of interest that cover all existing quantitative measures of understanding in the context of human-AI decision making: task decision boundary, model decision boundary, and model error. Our key result is that without assumptions about task-specific intuitions, explanations may potentially improve human understanding of model decision boundary, but they cannot improve human understanding of task decision boundary or model error. To achieve complementary human-AI performance, we articulate possible ways on how explanations need to work with human intuitions. For instance, human intuitions about the relevance of features (e.g., education is more important than age in predicting a person's income) can be critical in detecting model error. We validate the importance of human intuitions in shaping the outcome of machine explanations with empirical human-subject studies. Overall, our work provides a general framework along with actionable implications for future algorithmic development and empirical experiments of machine explanations.
Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies
Dec 21, 2021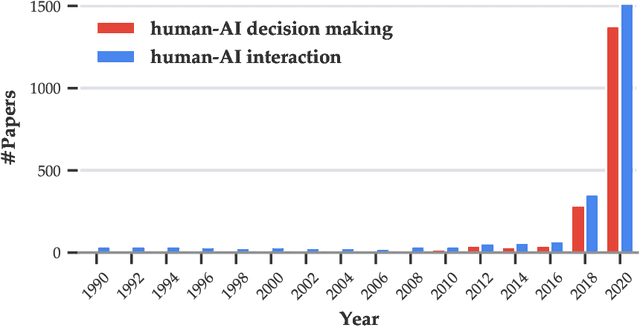
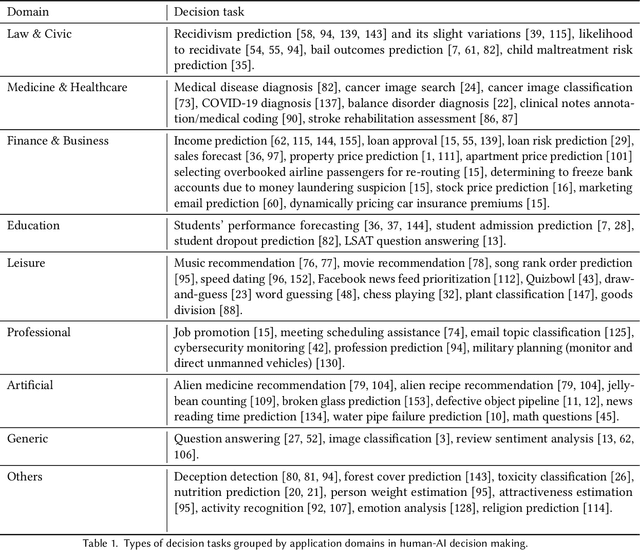
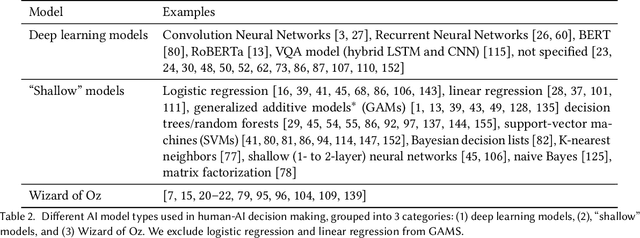
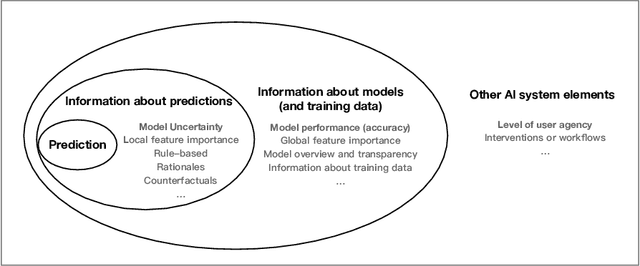
As AI systems demonstrate increasingly strong predictive performance, their adoption has grown in numerous domains. However, in high-stakes domains such as criminal justice and healthcare, full automation is often not desirable due to safety, ethical, and legal concerns, yet fully manual approaches can be inaccurate and time consuming. As a result, there is growing interest in the research community to augment human decision making with AI assistance. Besides developing AI technologies for this purpose, the emerging field of human-AI decision making must embrace empirical approaches to form a foundational understanding of how humans interact and work with AI to make decisions. To invite and help structure research efforts towards a science of understanding and improving human-AI decision making, we survey recent literature of empirical human-subject studies on this topic. We summarize the study design choices made in over 100 papers in three important aspects: (1) decision tasks, (2) AI models and AI assistance elements, and (3) evaluation metrics. For each aspect, we summarize current trends, discuss gaps in current practices of the field, and make a list of recommendations for future research. Our survey highlights the need to develop common frameworks to account for the design and research spaces of human-AI decision making, so that researchers can make rigorous choices in study design, and the research community can build on each other's work and produce generalizable scientific knowledge. We also hope this survey will serve as a bridge for HCI and AI communities to work together to mutually shape the empirical science and computational technologies for human-AI decision making.