 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Uncertainty Quantification in LLMs is Just Unsupervised Clustering
May 19, 2026Uncertainty Quantification (UQ) is widely regarded as the primary safeguard for deploying Large Language Models (LLMs) in high-stakes domains. However, we argue that the field suffers from a category error: mainstream UQ methods for LLMs are just unsupervised clustering algorithms. We demonstrate that most current approaches inherently quantify the internal consistency of the model's generations rather than their external correctness. Consequently, current methods are fundamentally blind to factual reality and fail to detect ``confident hallucinations,'' where models exhibit high confidence in stable but incorrect answers. Therefore, the current UQ methods may create a deceptive sense of safety when deploying the models with uncertainty. In detail, we identify three critical pathologies resulting from this dependence on internal state: a hyperparameter sensitivity crisis that renders deployment unsafe, an internal evaluation cycle that conflates stability with truth, and a fundamental lack of ground truth that forces reliance on unstable proxy metrics to evaluate uncertainty. To resolve this impasse, we advocate for a paradigm shift to UQ and outline a roadmap for the research community to adopt better evaluation metrics and settings, implement mechanism changes for native uncertainty, and anchor verification in objective truth, ensuring that model confidence serves as a reliable proxy for reality.
ShadeBench: A Benchmark Dataset for Building Shade Simulation in Sustainable Society
May 19, 2026Urban heat exposure is becoming an increasingly critical challenge due to the intensifying urban heat island effect. Fine-grained shade patterns, especially those induced by urban buildings, strongly influence pedestrians' thermal exposure and outdoor activity planning. However, accurately modeling and analyzing urban shade at scale remains difficult because of the lack of large-scale datasets and systematic evaluation frameworks. To address this challenge, we present ShadeBench, a comprehensive dataset and benchmark for urban shade understanding. ShadeBench contains geographically diverse urban scenes with temporally varying simulated shade maps and textual descriptions, together with aligned satellite imagery, building skeleton representations, and 3D building meshes. Built upon this multimodal dataset, ShadeBench supports a range of downstream tasks, including shade generation, shade segmentation, and 3D building reconstruction. We further establish standardized evaluation protocols and baseline methods for these tasks. By enabling scalable and fine-grained shade analysis, ShadeBench provides a foundation for data-driven urban climate research and supports future studies in heat-resilient urban planning and decision-making. The code and dataset are publicly available at https://darl-genai.github.io/shadebench/.
LangMARL: Natural Language Multi-Agent Reinforcement Learning
Apr 01, 2026Large language model (LLM) agents struggle to autonomously evolve coordination strategies in dynamic environments, largely because coarse global outcomes obscure the causal signals needed for local policy refinement. We identify this bottleneck as a multi-agent credit assignment problem, which has long been studied in classical multi-agent reinforcement learning (MARL) but remains underaddressed in LLM-based systems. Building on this observation, we propose LangMARL, a framework that brings credit assignment and policy gradient evolution from cooperative MARL into the language space. LangMARL introduces agent-level language credit assignment, pioneers gradient evolution in language space for policy improvement, and summarizes task-relevant causal relations from replayed trajectories to provide dense feedback and improve convergence under sparse rewards. Extensive experiments across diverse cooperative multi-agent tasks demonstrate improved sample efficiency, interpretability, and strong generalization.
Measuring What Matters: Scenario-Driven Evaluation for Trajectory Predictors in Autonomous Driving
Dec 13, 2025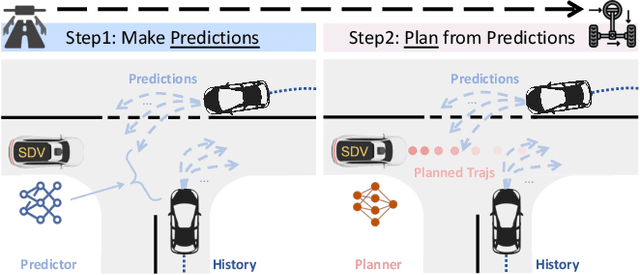
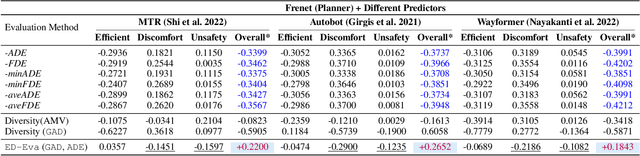
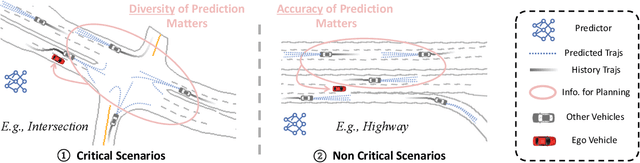
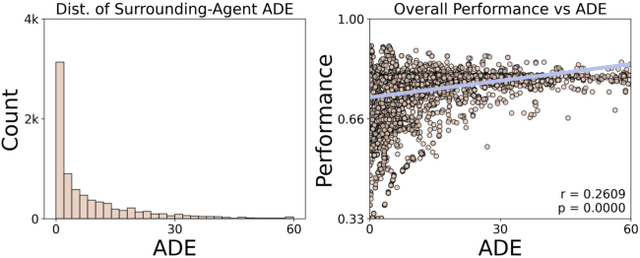
Being able to anticipate the motion of surrounding agents is essential for the safe operation of autonomous driving systems in dynamic situations. While various methods have been proposed for trajectory prediction, the current evaluation practices still rely on error-based metrics (e.g., ADE, FDE), which reveal the accuracy from a post-hoc view but ignore the actual effect the predictor brings to the self-driving vehicles (SDVs), especially in complex interactive scenarios: a high-quality predictor not only chases accuracy, but should also captures all possible directions a neighbor agent might move, to support the SDVs' cautious decision-making. Given that the existing metrics hardly account for this standard, in our work, we propose a comprehensive pipeline that adaptively evaluates the predictor's performance by two dimensions: accuracy and diversity. Based on the criticality of the driving scenario, these two dimensions are dynamically combined and result in a final score for the predictor's performance. Extensive experiments on a closed-loop benchmark using real-world datasets show that our pipeline yields a more reasonable evaluation than traditional metrics by better reflecting the correlation of the predictors' evaluation with the autonomous vehicles' driving performance. This evaluation pipeline shows a robust way to select a predictor that potentially contributes most to the SDV's driving performance.
DeepShade: Enable Shade Simulation by Text-conditioned Image Generation
Jul 16, 2025Heatwaves pose a significant threat to public health, especially as global warming intensifies. However, current routing systems (e.g., online maps) fail to incorporate shade information due to the difficulty of estimating shades directly from noisy satellite imagery and the limited availability of training data for generative models. In this paper, we address these challenges through two main contributions. First, we build an extensive dataset covering diverse longitude-latitude regions, varying levels of building density, and different urban layouts. Leveraging Blender-based 3D simulations alongside building outlines, we capture building shadows under various solar zenith angles throughout the year and at different times of day. These simulated shadows are aligned with satellite images, providing a rich resource for learning shade patterns. Second, we propose the DeepShade, a diffusion-based model designed to learn and synthesize shade variations over time. It emphasizes the nuance of edge features by jointly considering RGB with the Canny edge layer, and incorporates contrastive learning to capture the temporal change rules of shade. Then, by conditioning on textual descriptions of known conditions (e.g., time of day, solar angles), our framework provides improved performance in generating shade images. We demonstrate the utility of our approach by using our shade predictions to calculate shade ratios for real-world route planning in Tempe, Arizona. We believe this work will benefit society by providing a reference for urban planning in extreme heat weather and its potential practical applications in the environment.
GE-Chat: A Graph Enhanced RAG Framework for Evidential Response Generation of LLMs
May 15, 2025Large Language Models are now key assistants in human decision-making processes. However, a common note always seems to follow: "LLMs can make mistakes. Be careful with important info." This points to the reality that not all outputs from LLMs are dependable, and users must evaluate them manually. The challenge deepens as hallucinated responses, often presented with seemingly plausible explanations, create complications and raise trust issues among users. To tackle such issue, this paper proposes GE-Chat, a knowledge Graph enhanced retrieval-augmented generation framework to provide Evidence-based response generation. Specifically, when the user uploads a material document, a knowledge graph will be created, which helps construct a retrieval-augmented agent, enhancing the agent's responses with additional knowledge beyond its training corpus. Then we leverage Chain-of-Thought (CoT) logic generation, n-hop sub-graph searching, and entailment-based sentence generation to realize accurate evidence retrieval. We demonstrate that our method improves the existing models' performance in terms of identifying the exact evidence in a free-form context, providing a reliable way to examine the resources of LLM's conclusion and help with the judgment of the trustworthiness.
Uncertainty Quantification and Confidence Calibration in Large Language Models: A Survey
Mar 20, 2025Large Language Models (LLMs) excel in text generation, reasoning, and decision-making, enabling their adoption in high-stakes domains such as healthcare, law, and transportation. However, their reliability is a major concern, as they often produce plausible but incorrect responses. Uncertainty quantification (UQ) enhances trustworthiness by estimating confidence in outputs, enabling risk mitigation and selective prediction. However, traditional UQ methods struggle with LLMs due to computational constraints and decoding inconsistencies. Moreover, LLMs introduce unique uncertainty sources, such as input ambiguity, reasoning path divergence, and decoding stochasticity, that extend beyond classical aleatoric and epistemic uncertainty. To address this, we introduce a new taxonomy that categorizes UQ methods based on computational efficiency and uncertainty dimensions (input, reasoning, parameter, and prediction uncertainty). We evaluate existing techniques, assess their real-world applicability, and identify open challenges, emphasizing the need for scalable, interpretable, and robust UQ approaches to enhance LLM reliability.
Generative AI in Transportation Planning: A Survey
Mar 10, 2025

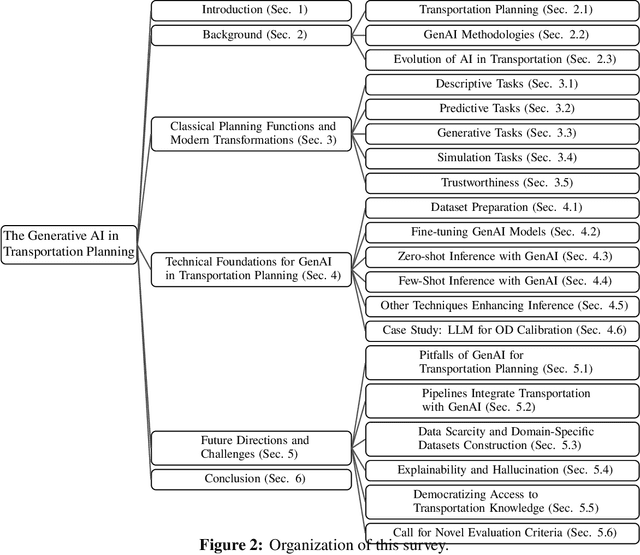
The integration of generative artificial intelligence (GenAI) into transportation planning has the potential to revolutionize tasks such as demand forecasting, infrastructure design, policy evaluation, and traffic simulation. However, there is a critical need for a systematic framework to guide the adoption of GenAI in this interdisciplinary domain. In this survey, we, a multidisciplinary team of researchers spanning computer science and transportation engineering, present the first comprehensive framework for leveraging GenAI in transportation planning. Specifically, we introduce a new taxonomy that categorizes existing applications and methodologies into two perspectives: transportation planning tasks and computational techniques. From the transportation planning perspective, we examine the role of GenAI in automating descriptive, predictive, generative, simulation, and explainable tasks to enhance mobility systems. From the computational perspective, we detail advancements in data preparation, domain-specific fine-tuning, and inference strategies, such as retrieval-augmented generation and zero-shot learning tailored to transportation applications. Additionally, we address critical challenges, including data scarcity, explainability, bias mitigation, and the development of domain-specific evaluation frameworks that align with transportation goals like sustainability, equity, and system efficiency. This survey aims to bridge the gap between traditional transportation planning methodologies and modern AI techniques, fostering collaboration and innovation. By addressing these challenges and opportunities, we seek to inspire future research that ensures ethical, equitable, and impactful use of generative AI in transportation planning.
Uncertainty Quantification of Large Language Models through Multi-Dimensional Responses
Feb 25, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks due to large training datasets and powerful transformer architecture. However, the reliability of responses from LLMs remains a question. Uncertainty quantification (UQ) of LLMs is crucial for ensuring their reliability, especially in areas such as healthcare, finance, and decision-making. Existing UQ methods primarily focus on semantic similarity, overlooking the deeper knowledge dimensions embedded in responses. We introduce a multi-dimensional UQ framework that integrates semantic and knowledge-aware similarity analysis. By generating multiple responses and leveraging auxiliary LLMs to extract implicit knowledge, we construct separate similarity matrices and apply tensor decomposition to derive a comprehensive uncertainty representation. This approach disentangles overlapping information from both semantic and knowledge dimensions, capturing both semantic variations and factual consistency, leading to more accurate UQ. Our empirical evaluations demonstrate that our method outperforms existing techniques in identifying uncertain responses, offering a more robust framework for enhancing LLM reliability in high-stakes applications.
Understanding the Uncertainty of LLM Explanations: A Perspective Based on Reasoning Topology
Feb 24, 2025Understanding the uncertainty in large language model (LLM) explanations is important for evaluating their faithfulness and reasoning consistency, and thus provides insights into the reliability of LLM's output regarding a question. In this work, we propose a novel framework that quantifies uncertainty in LLM explanations through a reasoning topology perspective. By designing a structural elicitation strategy, we guide the LLMs to frame the explanations of an answer into a graph topology. This process decomposes the explanations into the knowledge related sub-questions and topology-based reasoning structures, which allows us to quantify uncertainty not only at the semantic level but also from the reasoning path. It further brings convenience to assess knowledge redundancy and provide interpretable insights into the reasoning process. Our method offers a systematic way to interpret the LLM reasoning, analyze limitations, and provide guidance for enhancing robustness and faithfulness. This work pioneers the use of graph-structured uncertainty measurement in LLM explanations and demonstrates the potential of topology-based quantification.