 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCQA-Eval: Efficient Confidence Evaluation in NLG with Gold-Standard Correctness Labels
Paper and Code
Feb 20, 2025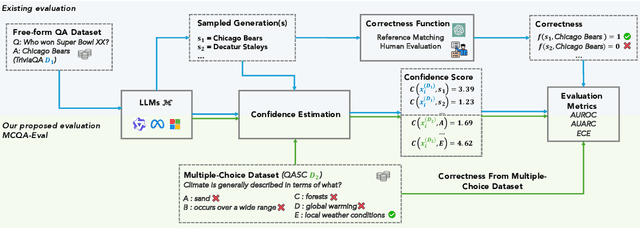

Large Language Models (LLMs) require robust confidence estimation, particularly in critical domains like healthcare and law where unreliable outputs can lead to significant consequences. Despite much recent work in confidence estimation, current evaluation frameworks rely on correctness functions -- various heuristics that are often noisy, expensive, and possibly introduce systematic biases. These methodological weaknesses tend to distort evaluation metrics and thus the comparative ranking of confidence measures. We introduce MCQA-Eval, an evaluation framework for assessing confidence measures in Natural Language Generation (NLG) that eliminates dependence on an explicit correctness function by leveraging gold-standard correctness labels from multiple-choice datasets. MCQA-Eval enables systematic comparison of both internal state-based white-box (e.g. logit-based) and consistency-based black-box confidence measures, providing a unified evaluation methodology across different approaches. Through extensive experiments on multiple LLMs and widely used QA datasets, we report that MCQA-Eval provides efficient and more reliable assessments of confidence estimation methods than existing approaches.