 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Persona Identification and New Service Adaptation Recommendation
Nov 15, 2023Providing a personalized user experience on information dense webpages helps users in reaching their end-goals sooner. We explore an automated approach to identifying user personas by leveraging high dimensional trajectory information from user sessions on webpages. While neural collaborative filtering (NCF) approaches pay little attention to token semantics, our method introduces SessionBERT, a Transformer-backed language model trained from scratch on the masked language modeling (mlm) objective for user trajectories (pages, metadata, billing in a session) aiming to capture semantics within them. Our results show that representations learned through SessionBERT are able to consistently outperform a BERT-base model providing a 3% and 1% relative improvement in F1-score for predicting page links and next services. We leverage SessionBERT and extend it to provide recommendations (top-5) for the next most-relevant services that a user would be likely to use. We achieve a HIT@5 of 58% from our recommendation model.
Contextual Dynamic Prompting for Response Generation in Task-oriented Dialog Systems
Feb 10, 2023



Response generation is one of the critical components in task-oriented dialog systems. Existing studies have shown that large pre-trained language models can be adapted to this task. The typical paradigm of adapting such extremely large language models would be by fine-tuning on the downstream tasks which is not only time-consuming but also involves significant resources and access to fine-tuning data. Prompting (Schick and Sch\"utze, 2020) has been an alternative to fine-tuning in many NLP tasks. In our work, we explore the idea of using prompting for response generation in task-oriented dialog systems. Specifically, we propose an approach that performs contextual dynamic prompting where the prompts are learnt from dialog contexts. We aim to distill useful prompting signals from the dialog context. On experiments with MultiWOZ 2.2 dataset (Zang et al., 2020), we show that contextual dynamic prompts improve response generation in terms of combined score (Mehri et al., 2019) by 3 absolute points, and a massive 20 points when dialog states are incorporated. Furthermore, human annotation on these conversations found that agents which incorporate context were preferred over agents with vanilla prefix-tuning.
Medical Scientific Table-to-Text Generation with Human-in-the-Loop under the Data Sparsity Constraint
May 24, 2022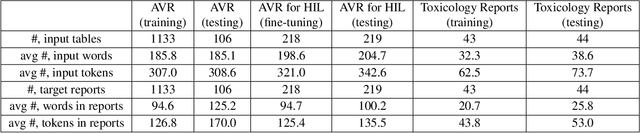
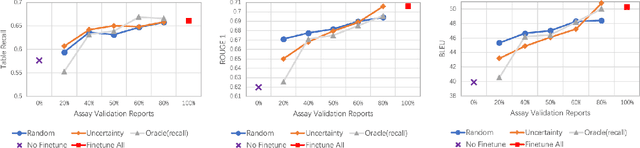
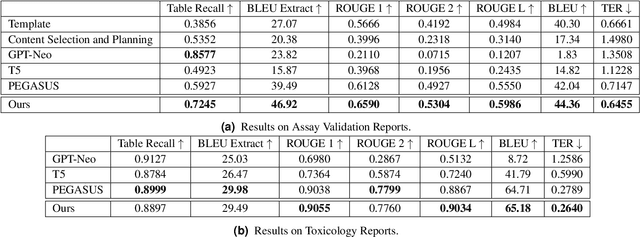
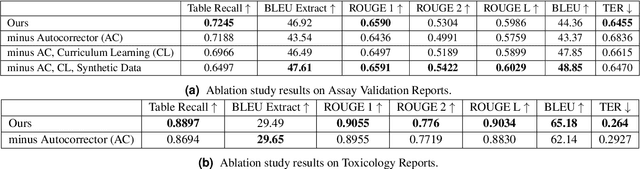
Structured (tabular) data in the preclinical and clinical domains contains valuable information about individuals and an efficient table-to-text summarization system can drastically reduce manual efforts to condense this data into reports. However, in practice, the problem is heavily impeded by the data paucity, data sparsity and inability of the state-of-the-art natural language generation models (including T5, PEGASUS and GPT-Neo) to produce accurate and reliable outputs. In this paper, we propose a novel table-to-text approach and tackle these problems with a novel two-step architecture which is enhanced by auto-correction, copy mechanism and synthetic data augmentation. The study shows that the proposed approach selects salient biomedical entities and values from structured data with improved precision (up to 0.13 absolute increase) of copying the tabular values to generate coherent and accurate text for assay validation reports and toxicology reports. Moreover, we also demonstrate a light-weight adaptation of the proposed system to new datasets by fine-tuning with as little as 40\% training examples. The outputs of our model are validated by human experts in the Human-in-the-Loop scenario.
Emotion Detection in Text: Focusing on Latent Representation
Jul 22, 2019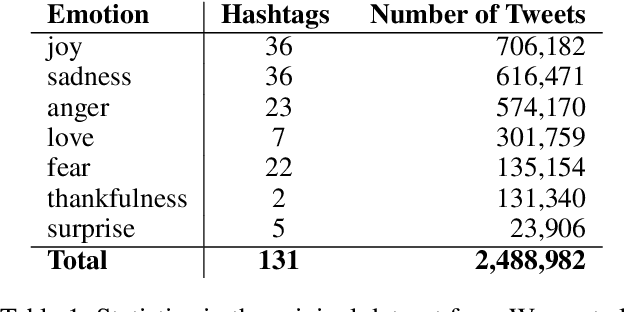
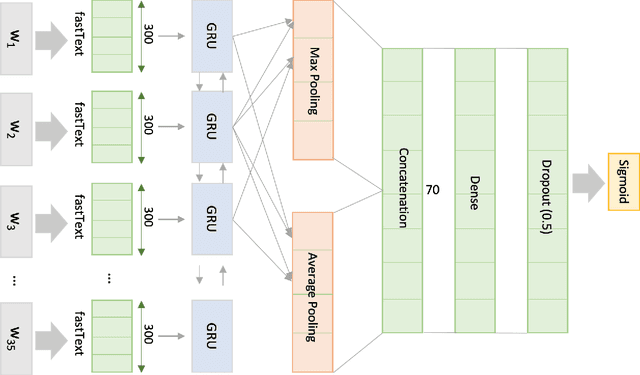

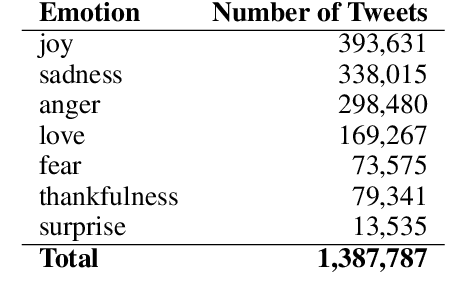
In recent years, emotion detection in text has become more popular due to its vast potential applications in marketing, political science, psychology, human-computer interaction, artificial intelligence, etc. In this work, we argue that current methods which are based on conventional machine learning models cannot grasp the intricacy of emotional language by ignoring the sequential nature of the text, and the context. These methods, therefore, are not sufficient to create an applicable and generalizable emotion detection methodology. Understanding these limitations, we present a new network based on a bidirectional GRU model to show that capturing more meaningful information from text can significantly improve the performance of these models. The results show significant improvement with an average of 26.8 point increase in F-measure on our test data and 38.6 increase on the totally new dataset.
Emotional Embeddings: Refining Word Embeddings to Capture Emotional Content of Words
May 31, 2019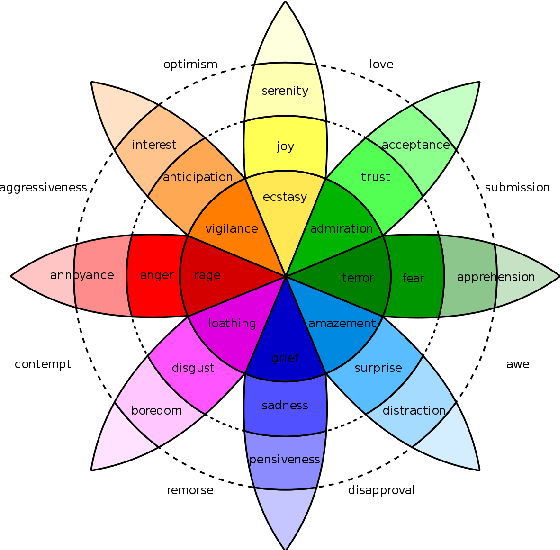
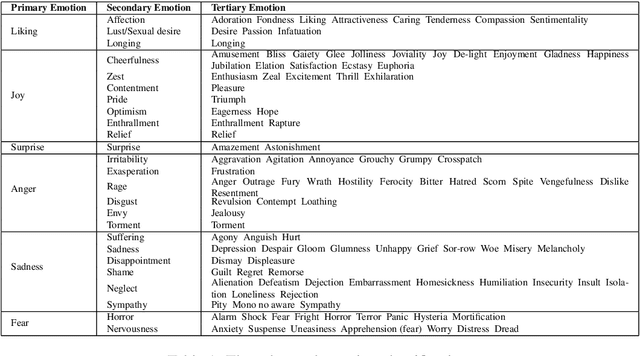

Word embeddings are one of the most useful tools in any modern natural language processing expert's toolkit. They contain various types of information about each word which makes them the best way to represent the terms in any NLP task. But there are some types of information that cannot be learned by these models. Emotional information of words are one of those. In this paper, we present an approach to incorporate emotional information of words into these models. We accomplish this by adding a secondary training stage which uses an emotional lexicon and a psychological model of basic emotions. We show that fitting an emotional model into pre-trained word vectors can increase the performance of these models in emotional similarity metrics. Retrained models perform better than their original counterparts from 13% improvement for Word2Vec model, to 29% for GloVe vectors. This is the first such model presented in the literature, and although preliminary, these emotion sensitive models can open the way to increase performance in variety of emotion detection techniques.
Emotion Detection in Text: a Review
Jun 02, 2018In recent years, emotion detection in text has become more popular due to its vast potential applications in marketing, political science, psychology, human-computer interaction, artificial intelligence, etc. Access to a huge amount of textual data, especially opinionated and self-expression text also played a special role to bring attention to this field. In this paper, we review the work that has been done in identifying emotion expressions in text and argue that although many techniques, methodologies, and models have been created to detect emotion in text, there are various reasons that make these methods insufficient. Although, there is an essential need to improve the design and architecture of current systems, factors such as the complexity of human emotions, and the use of implicit and metaphorical language in expressing it, lead us to think that just re-purposing standard methodologies will not be enough to capture these complexities, and it is important to pay attention to the linguistic intricacies of emotion expression.