 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Scientific Table-to-Text Generation with Human-in-the-Loop under the Data Sparsity Constraint
May 24, 2022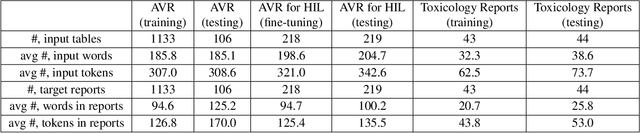
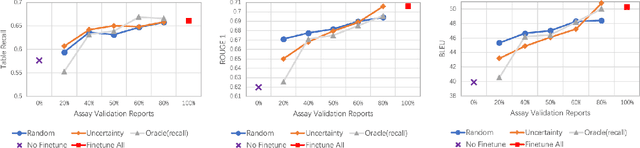
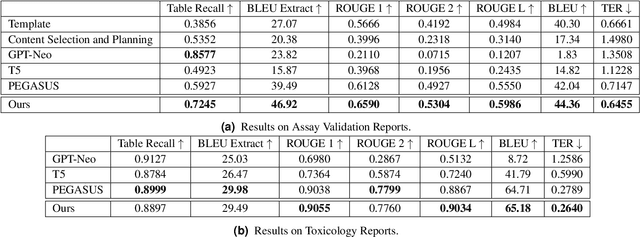
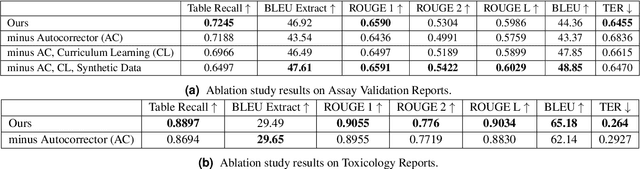
Structured (tabular) data in the preclinical and clinical domains contains valuable information about individuals and an efficient table-to-text summarization system can drastically reduce manual efforts to condense this data into reports. However, in practice, the problem is heavily impeded by the data paucity, data sparsity and inability of the state-of-the-art natural language generation models (including T5, PEGASUS and GPT-Neo) to produce accurate and reliable outputs. In this paper, we propose a novel table-to-text approach and tackle these problems with a novel two-step architecture which is enhanced by auto-correction, copy mechanism and synthetic data augmentation. The study shows that the proposed approach selects salient biomedical entities and values from structured data with improved precision (up to 0.13 absolute increase) of copying the tabular values to generate coherent and accurate text for assay validation reports and toxicology reports. Moreover, we also demonstrate a light-weight adaptation of the proposed system to new datasets by fine-tuning with as little as 40\% training examples. The outputs of our model are validated by human experts in the Human-in-the-Loop scenario.
Extraction of Pharmacokinetic Evidence of Drug-drug Interactions from the Literature
May 18, 2015Drug-drug interaction (DDI) is a major cause of morbidity and mortality and a subject of intense scientific interest. Biomedical literature mining can aid DDI research by extracting evidence for large numbers of potential interactions from published literature and clinical databases. Though DDI is investigated in domains ranging in scale from intracellular biochemistry to human populations, literature mining has not been used to extract specific types of experimental evidence, which are reported differently for distinct experimental goals. We focus on pharmacokinetic evidence for DDI, essential for identifying causal mechanisms of putative interactions and as input for further pharmacological and pharmaco-epidemiology investigations. We used manually curated corpora of PubMed abstracts and annotated sentences to evaluate the efficacy of literature mining on two tasks: first, identifying PubMed abstracts containing pharmacokinetic evidence of DDIs; second, extracting sentences containing such evidence from abstracts. We implemented a text mining pipeline and evaluated it using several linear classifiers and a variety of feature transforms. The most important textual features in the abstract and sentence classification tasks were analyzed. We also investigated the performance benefits of using features derived from PubMed metadata fields, various publicly available named entity recognizers, and pharmacokinetic dictionaries. Several classifiers performed very well in distinguishing relevant and irrelevant abstracts (reaching F1~=0.93, MCC~=0.74, iAUC~=0.99) and sentences (F1~=0.76, MCC~=0.65, iAUC~=0.83). We found that word bigram features were important for achieving optimal classifier performance and that features derived from Medical Subject Headings (MeSH) terms significantly improved abstract classification. ...