 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoherent and Multi-modality Image Inpainting via Latent Space Optimization
Jul 10, 2024
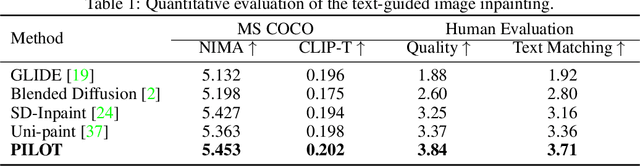
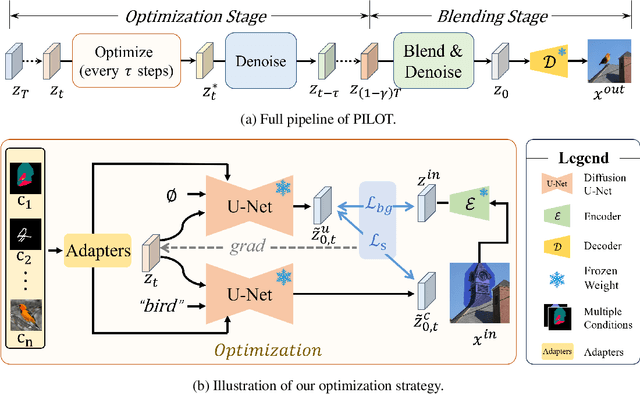

With the advancements in denoising diffusion probabilistic models (DDPMs), image inpainting has significantly evolved from merely filling information based on nearby regions to generating content conditioned on various prompts such as text, exemplar images, and sketches. However, existing methods, such as model fine-tuning and simple concatenation of latent vectors, often result in generation failures due to overfitting and inconsistency between the inpainted region and the background. In this paper, we argue that the current large diffusion models are sufficiently powerful to generate realistic images without further tuning. Hence, we introduce PILOT (in\textbf{P}ainting v\textbf{I}a \textbf{L}atent \textbf{O}p\textbf{T}imization), an optimization approach grounded on a novel \textit{semantic centralization} and \textit{background preservation loss}. Our method searches latent spaces capable of generating inpainted regions that exhibit high fidelity to user-provided prompts while maintaining coherence with the background. Furthermore, we propose a strategy to balance optimization expense and image quality, significantly enhancing generation efficiency. Our method seamlessly integrates with any pre-trained model, including ControlNet and DreamBooth, making it suitable for deployment in multi-modal editing tools. Our qualitative and quantitative evaluations demonstrate that PILOT outperforms existing approaches by generating more coherent, diverse, and faithful inpainted regions in response to provided prompts.
Medical Scientific Table-to-Text Generation with Human-in-the-Loop under the Data Sparsity Constraint
May 24, 2022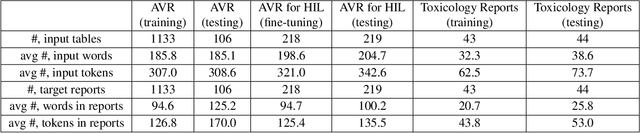
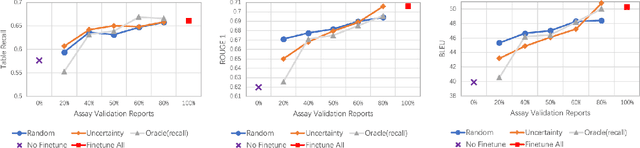
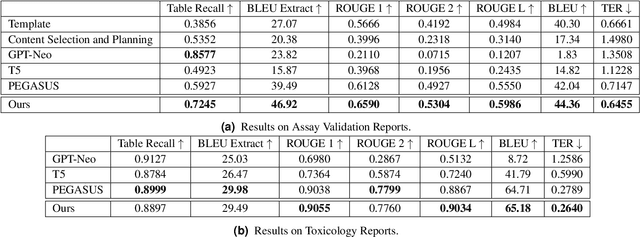
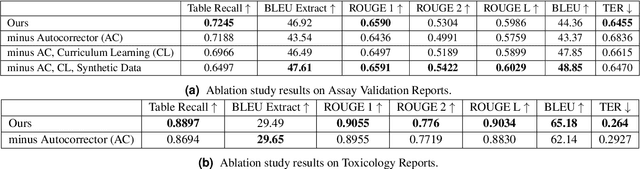
Structured (tabular) data in the preclinical and clinical domains contains valuable information about individuals and an efficient table-to-text summarization system can drastically reduce manual efforts to condense this data into reports. However, in practice, the problem is heavily impeded by the data paucity, data sparsity and inability of the state-of-the-art natural language generation models (including T5, PEGASUS and GPT-Neo) to produce accurate and reliable outputs. In this paper, we propose a novel table-to-text approach and tackle these problems with a novel two-step architecture which is enhanced by auto-correction, copy mechanism and synthetic data augmentation. The study shows that the proposed approach selects salient biomedical entities and values from structured data with improved precision (up to 0.13 absolute increase) of copying the tabular values to generate coherent and accurate text for assay validation reports and toxicology reports. Moreover, we also demonstrate a light-weight adaptation of the proposed system to new datasets by fine-tuning with as little as 40\% training examples. The outputs of our model are validated by human experts in the Human-in-the-Loop scenario.