 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Tensor Logic: Unifying Datalog and Neural Reasoning via Tensor Contraction
Jan 23, 2026The unification of symbolic reasoning and neural networks remains a central challenge in artificial intelligence. Symbolic systems offer reliability and interpretability but lack scalability, while neural networks provide learning capabilities but sacrifice transparency. Tensor Logic, proposed by Domingos, suggests that logical rules and Einstein summation are mathematically equivalent, offering a principled path toward unification. This paper provides empirical validation of this framework through three experiments. First, we demonstrate the equivalence between recursive Datalog rules and iterative tensor contractions by computing the transitive closure of a biblical genealogy graph containing 1,972 individuals and 1,727 parent-child relationships, converging in 74 iterations to discover 33,945 ancestor relationships. Second, we implement reasoning in embedding space by training a neural network with learnable transformation matrices, demonstrating successful zero-shot compositional inference on held-out queries. Third, we validate the Tensor Logic superposition construction on FB15k-237, a large-scale knowledge graph with 14,541 entities and 237 relations. Using Domingos's relation matrix formulation $R_r = E^\top A_r E$, we achieve MRR of 0.3068 on standard link prediction and MRR of 0.3346 on a compositional reasoning benchmark where direct edges are removed during training, demonstrating that matrix composition enables multi-hop inference without direct training examples.
Causality extraction from medical text using Large Language Models (LLMs)
Jul 13, 2024



This study explores the potential of natural language models, including large language models, to extract causal relations from medical texts, specifically from Clinical Practice Guidelines (CPGs). The outcomes causality extraction from Clinical Practice Guidelines for gestational diabetes are presented, marking a first in the field. We report on a set of experiments using variants of BERT (BioBERT, DistilBERT, and BERT) and using Large Language Models (LLMs), namely GPT-4 and LLAMA2. Our experiments show that BioBERT performed better than other models, including the Large Language Models, with an average F1-score of 0.72. GPT-4 and LLAMA2 results show similar performance but less consistency. We also release the code and an annotated a corpus of causal statements within the Clinical Practice Guidelines for gestational diabetes.
Machine Reading of Hypotheses for Organizational Research Reviews and Pre-trained Models via R Shiny App for Non-Programmers
Jul 11, 2021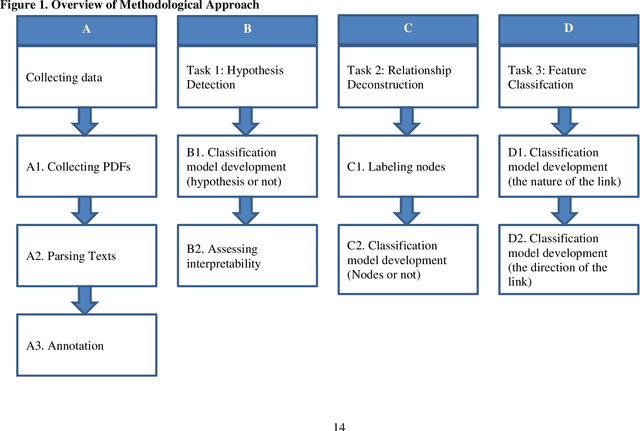


The volume of scientific publications in organizational research becomes exceedingly overwhelming for human researchers who seek to timely extract and review knowledge. This paper introduces natural language processing (NLP) models to accelerate the discovery, extraction, and organization of theoretical developments (i.e., hypotheses) from social science publications. We illustrate and evaluate NLP models in the context of a systematic review of stakeholder value constructs and hypotheses. Specifically, we develop NLP models to automatically 1) detect sentences in scholarly documents as hypotheses or not (Hypothesis Detection), 2) deconstruct the hypotheses into nodes (constructs) and links (causal/associative relationships) (Relationship Deconstruction ), and 3) classify the features of links in terms causality (versus association) and direction (positive, negative, versus nonlinear) (Feature Classification). Our models have reported high performance metrics for all three tasks. While our models are built in Python, we have made the pre-trained models fully accessible for non-programmers. We have provided instructions on installing and using our pre-trained models via an R Shiny app graphic user interface (GUI). Finally, we suggest the next paths to extend our methodology for computer-assisted knowledge synthesis.
Computing Conceptual Distances between Breast Cancer Screening Guidelines: An Implementation of a Near-Peer Epistemic Model ofMedical Disagreement
Jul 01, 2020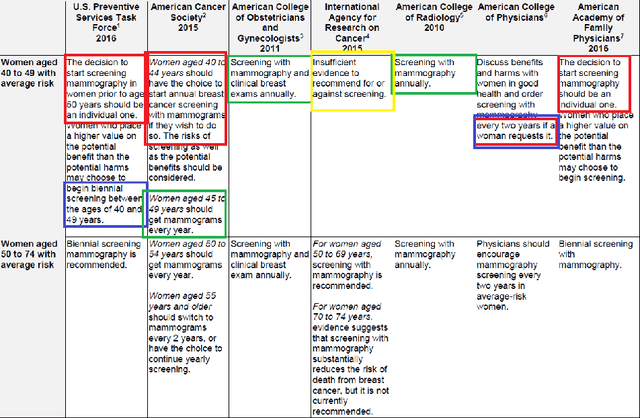
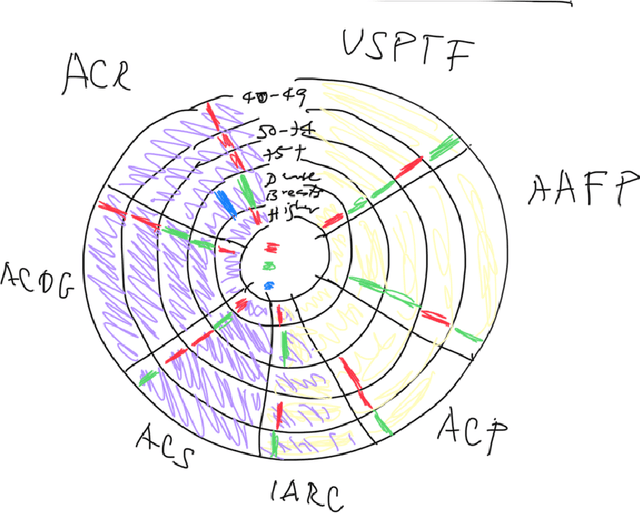
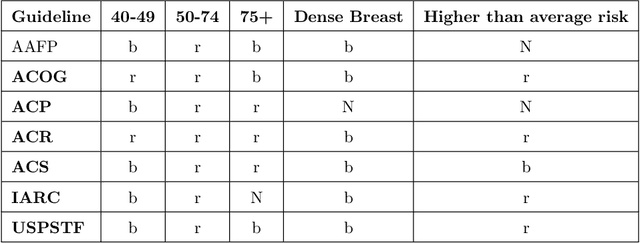
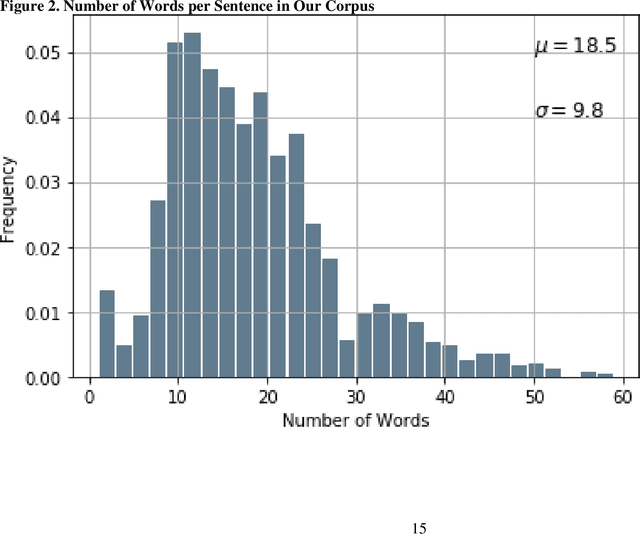
Using natural language processing tools, we investigate the differences of recommendations in medical guidelines for the same decision problem -- breast cancer screening. We show that these differences arise from knowledge brought to the problem by different medical societies, as reflected in the conceptual vocabularies used by the different groups of authors.The computational models we build and analyze agree with the near-peer epistemic model of expert disagreement proposed by Garbayo. Even though the article is a case study focused on one set of guidelines, the proposed methodology is broadly applicable. In addition to proposing a novel graph-based similarity model for comparing collections of documents, we perform an extensive analysis of the model performance. In a series of a few dozen experiments, in three broad categories, we show, at a very high statistical significance level of 3-4 standard deviations for our best models, that the high similarity between expert annotated model and our concept based, automatically created, computational models is not accidental. Our best model achieves roughly 70% similarity. We also describe possible extensions of this work.
Causal Knowledge Extraction from Scholarly Papers in Social Sciences
Jun 16, 2020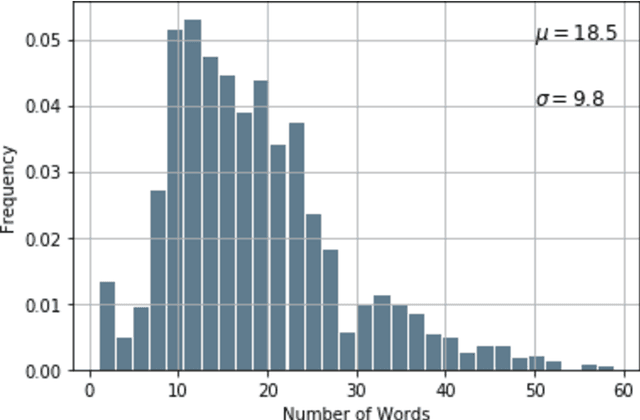
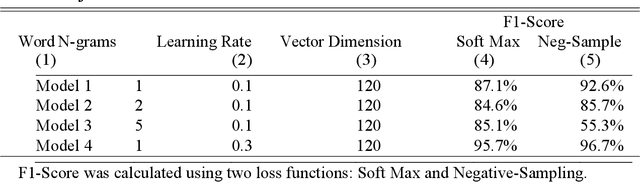


The scale and scope of scholarly articles today are overwhelming human researchers who seek to timely digest and synthesize knowledge. In this paper, we seek to develop natural language processing (NLP) models to accelerate the speed of extraction of relationships from scholarly papers in social sciences, identify hypotheses from these papers, and extract the cause-and-effect entities. Specifically, we develop models to 1) classify sentences in scholarly documents in business and management as hypotheses (hypothesis classification), 2) classify these hypotheses as causal relationships or not (causality classification), and, if they are causal, 3) extract the cause and effect entities from these hypotheses (entity extraction). We have achieved high performance for all the three tasks using different modeling techniques. Our approach may be generalizable to scholarly documents in a wide range of social sciences, as well as other types of textual materials.
A Novel Method of Extracting Topological Features from Word Embeddings
Apr 19, 2020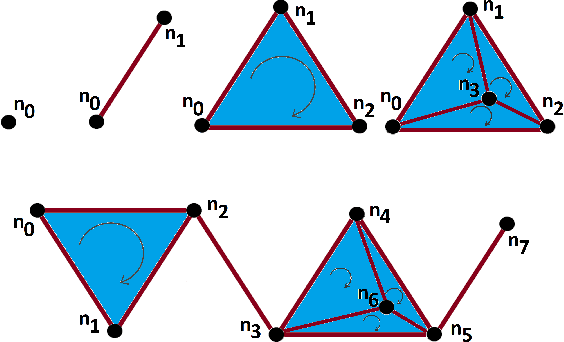

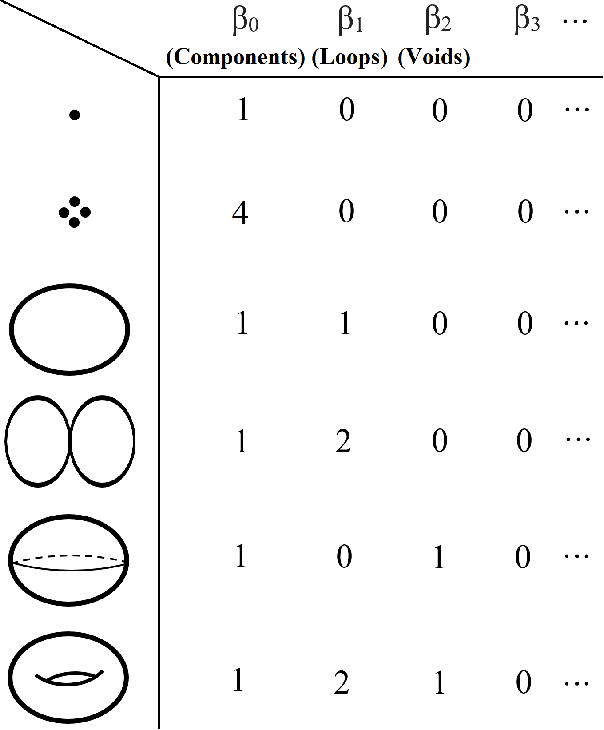
In recent years, topological data analysis has been utilized for a wide range of problems to deal with high dimensional noisy data. While text representations are often high dimensional and noisy, there are only a few work on the application of topological data analysis in natural language processing. In this paper, we introduce a novel algorithm to extract topological features from word embedding representation of text that can be used for text classification. Working on word embeddings, topological data analysis can interpret the embedding high-dimensional space and discover the relations among different embedding dimensions. We will use persistent homology, the most commonly tool from topological data analysis, for our experiment. Examining our topological algorithm on long textual documents, we will show our defined topological features may outperform conventional text mining features.
Topological Data Analysis in Text Classification: Extracting Features with Additive Information
Mar 29, 2020
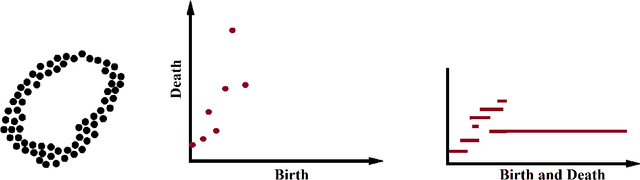

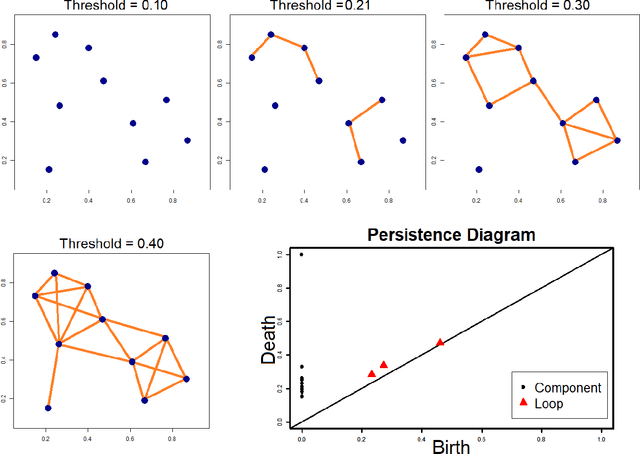
While the strength of Topological Data Analysis has been explored in many studies on high dimensional numeric data, it is still a challenging task to apply it to text. As the primary goal in topological data analysis is to define and quantify the shapes in numeric data, defining shapes in the text is much more challenging, even though the geometries of vector spaces and conceptual spaces are clearly relevant for information retrieval and semantics. In this paper, we examine two different methods of extraction of topological features from text, using as the underlying representations of words the two most popular methods, namely word embeddings and TF-IDF vectors. To extract topological features from the word embedding space, we interpret the embedding of a text document as high dimensional time series, and we analyze the topology of the underlying graph where the vertices correspond to different embedding dimensions. For topological data analysis with the TF-IDF representations, we analyze the topology of the graph whose vertices come from the TF-IDF vectors of different blocks in the textual document. In both cases, we apply homological persistence to reveal the geometric structures under different distance resolutions. Our results show that these topological features carry some exclusive information that is not captured by conventional text mining methods. In our experiments we observe adding topological features to the conventional features in ensemble models improves the classification results (up to 5\%). On the other hand, as expected, topological features by themselves may be not sufficient for effective classification. It is an open problem to see whether TDA features from word embeddings might be sufficient, as they seem to perform within a range of few points from top results obtained with a linear support vector classifier.
UNCC Biomedical Semantic Question Answering Systems. BioASQ: Task-7B, Phase-B
Feb 05, 2020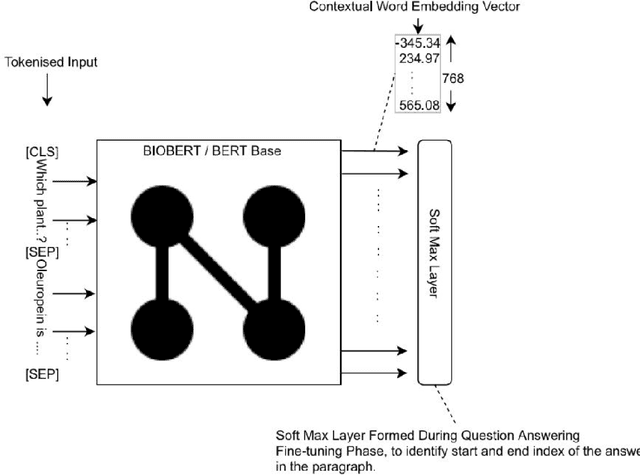
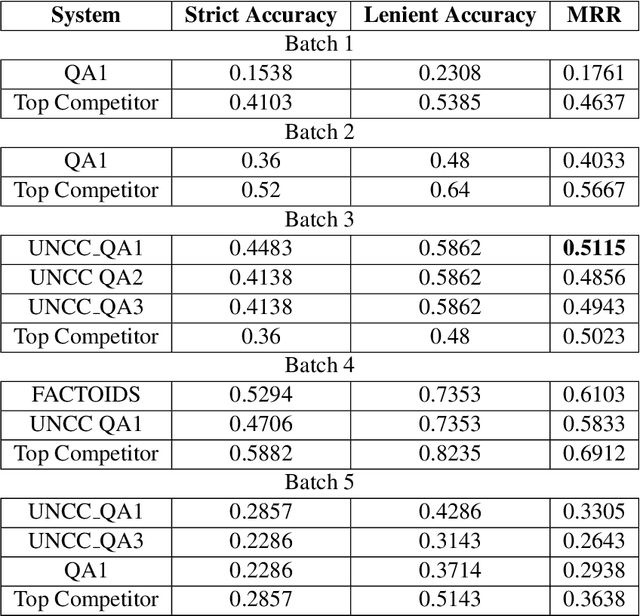
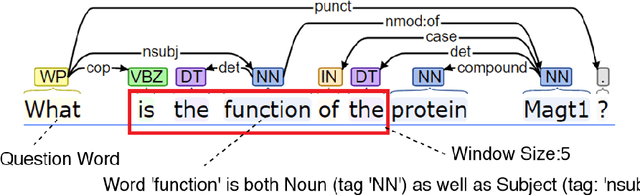
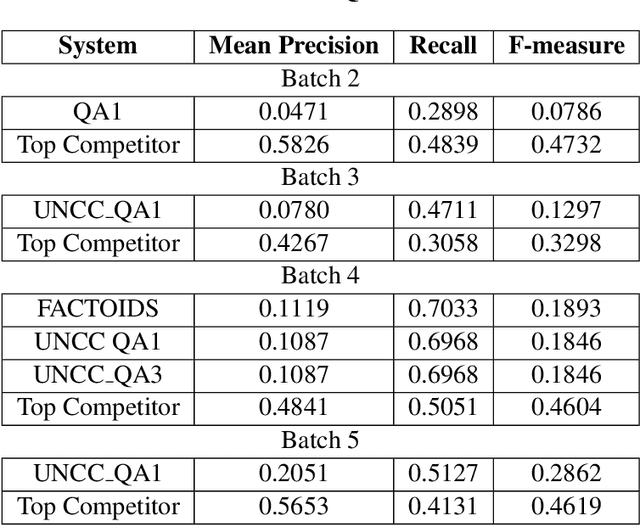
In this paper, we detail our submission to the 2019, 7th year, BioASQ competition. We present our approach for Task-7b, Phase B, Exact Answering Task. These Question Answering (QA) tasks include Factoid, Yes/No, List Type Question answering. Our system is based on a contextual word embedding model. We have used a Bidirectional Encoder Representations from Transformers(BERT) based system, fined tuned for biomedical question answering task using BioBERT. In the third test batch set, our system achieved the highest MRR score for Factoid Question Answering task. Also, for List type question answering task our system achieved the highest recall score in the fourth test batch set. Along with our detailed approach, we present the results for our submissions, and also highlight identified downsides for our current approach and ways to improve them in our future experiments.
Emotion Detection in Text: Focusing on Latent Representation
Jul 22, 2019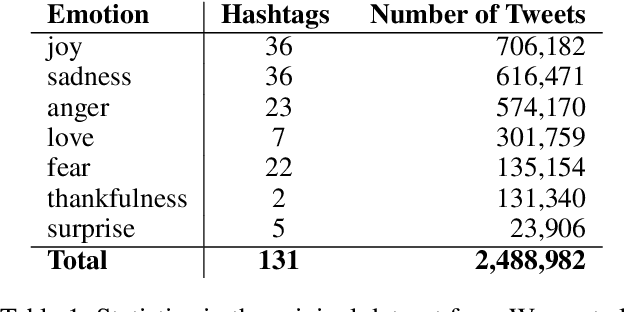
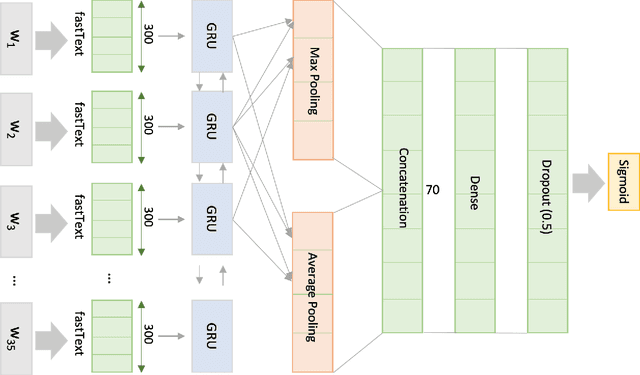

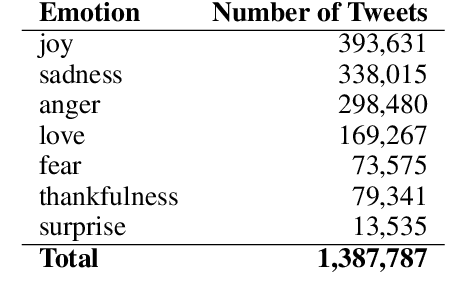
In recent years, emotion detection in text has become more popular due to its vast potential applications in marketing, political science, psychology, human-computer interaction, artificial intelligence, etc. In this work, we argue that current methods which are based on conventional machine learning models cannot grasp the intricacy of emotional language by ignoring the sequential nature of the text, and the context. These methods, therefore, are not sufficient to create an applicable and generalizable emotion detection methodology. Understanding these limitations, we present a new network based on a bidirectional GRU model to show that capturing more meaningful information from text can significantly improve the performance of these models. The results show significant improvement with an average of 26.8 point increase in F-measure on our test data and 38.6 increase on the totally new dataset.
Emotional Embeddings: Refining Word Embeddings to Capture Emotional Content of Words
May 31, 2019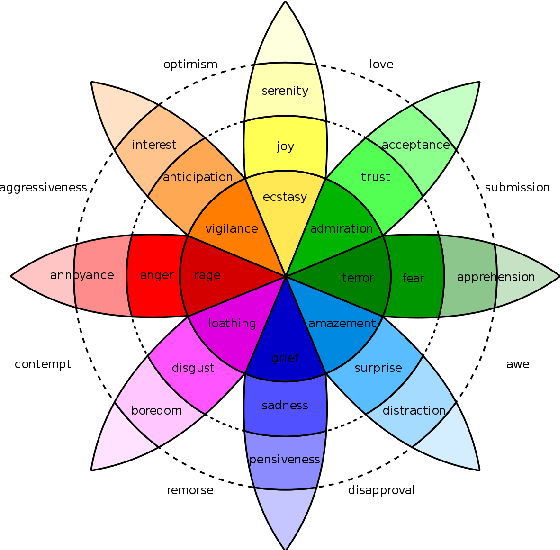
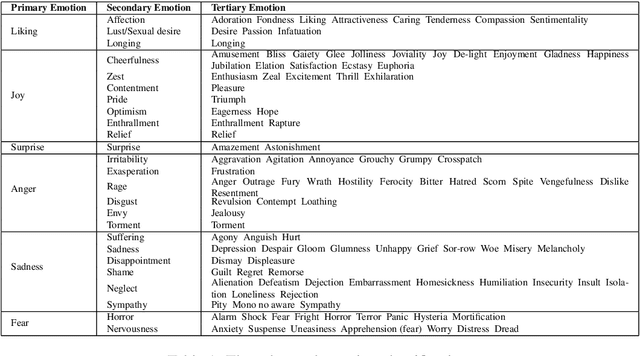

Word embeddings are one of the most useful tools in any modern natural language processing expert's toolkit. They contain various types of information about each word which makes them the best way to represent the terms in any NLP task. But there are some types of information that cannot be learned by these models. Emotional information of words are one of those. In this paper, we present an approach to incorporate emotional information of words into these models. We accomplish this by adding a secondary training stage which uses an emotional lexicon and a psychological model of basic emotions. We show that fitting an emotional model into pre-trained word vectors can increase the performance of these models in emotional similarity metrics. Retrained models perform better than their original counterparts from 13% improvement for Word2Vec model, to 29% for GloVe vectors. This is the first such model presented in the literature, and although preliminary, these emotion sensitive models can open the way to increase performance in variety of emotion detection techniques.