 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality extraction from medical text using Large Language Models (LLMs)
Jul 13, 2024



This study explores the potential of natural language models, including large language models, to extract causal relations from medical texts, specifically from Clinical Practice Guidelines (CPGs). The outcomes causality extraction from Clinical Practice Guidelines for gestational diabetes are presented, marking a first in the field. We report on a set of experiments using variants of BERT (BioBERT, DistilBERT, and BERT) and using Large Language Models (LLMs), namely GPT-4 and LLAMA2. Our experiments show that BioBERT performed better than other models, including the Large Language Models, with an average F1-score of 0.72. GPT-4 and LLAMA2 results show similar performance but less consistency. We also release the code and an annotated a corpus of causal statements within the Clinical Practice Guidelines for gestational diabetes.
Computer-assisted construct classification of organizational performance concerning different stakeholder groups
Jul 11, 2021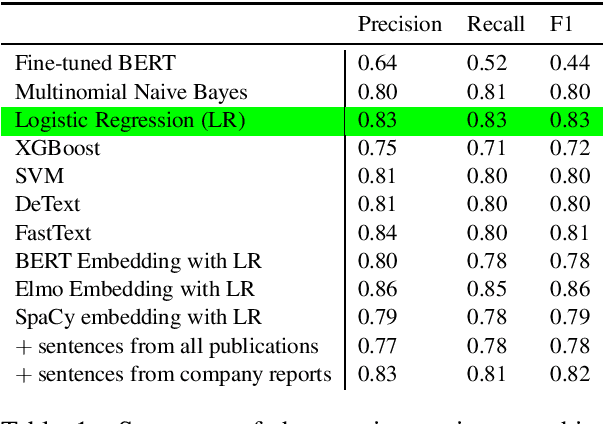
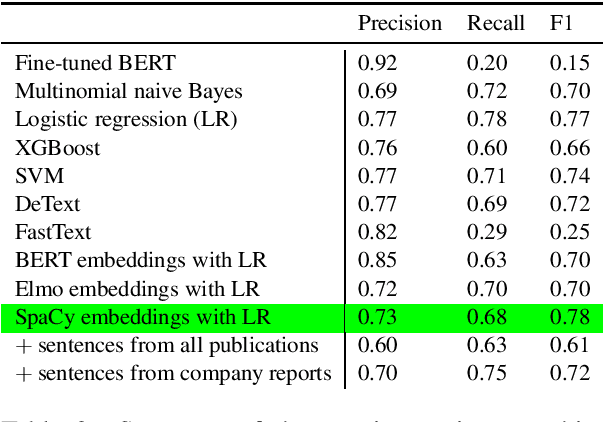
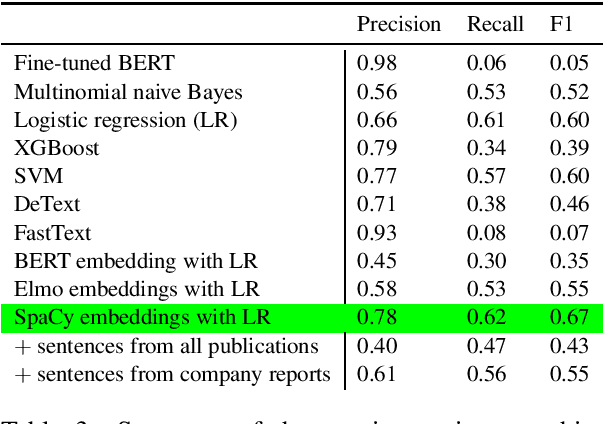
The number of research articles in business and management has dramatically increased along with terminology, constructs, and measures. Proper classification of organizational performance constructs from research articles plays an important role in categorizing the literature and understanding to whom its research implications may be relevant. In this work, we classify constructs (i.e., concepts and terminology used to capture different aspects of organizational performance) in research articles into a three-level categorization: (a) performance and non-performance categories (Level 0); (b) for performance constructs, stakeholder group-level of performance concerning investors, customers, employees, and the society (community and natural environment) (Level 1); and (c) for each stakeholder group-level, subcategories of different ways of measurement (Level 2). We observed that increasing contextual information with features extracted from surrounding sentences and external references improves classification of disaggregate-level labels, given limited training data. Our research has implications for computer-assisted construct identification and classification - an essential step for research synthesis.
Computing Conceptual Distances between Breast Cancer Screening Guidelines: An Implementation of a Near-Peer Epistemic Model ofMedical Disagreement
Jul 01, 2020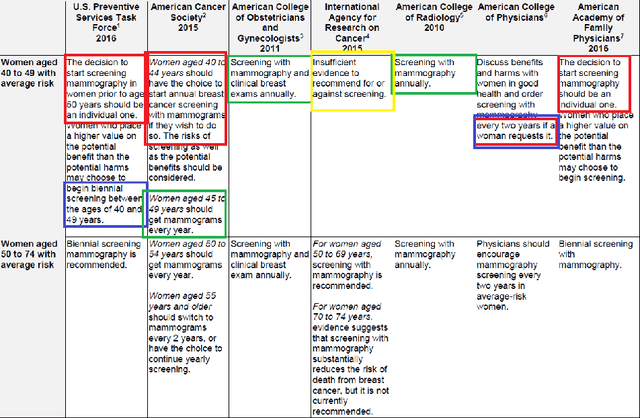
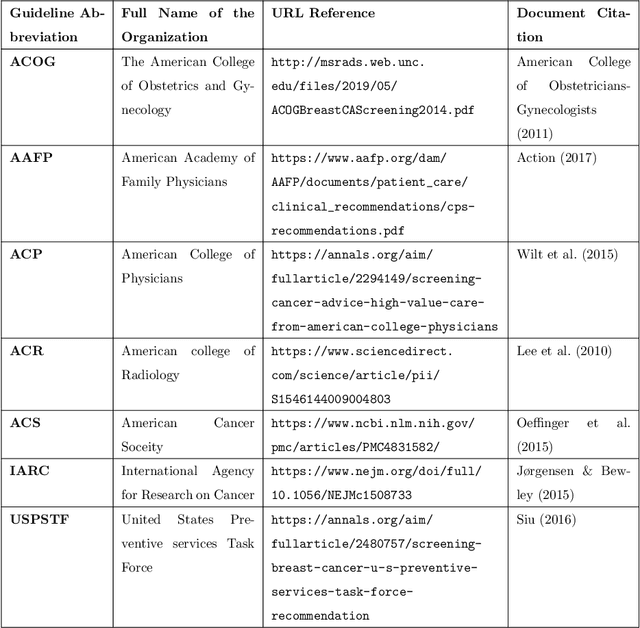
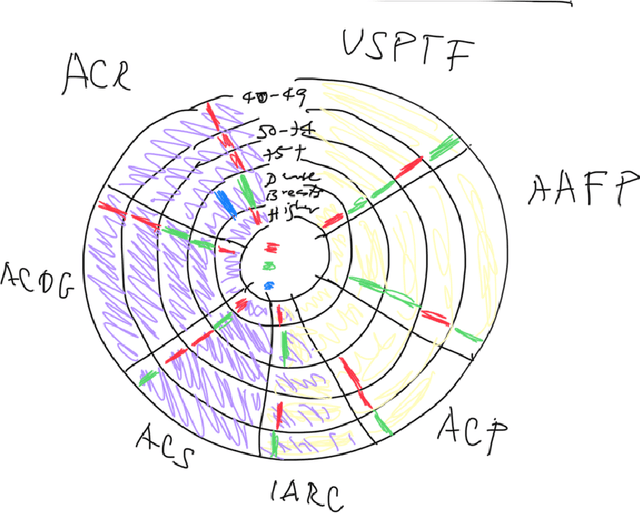
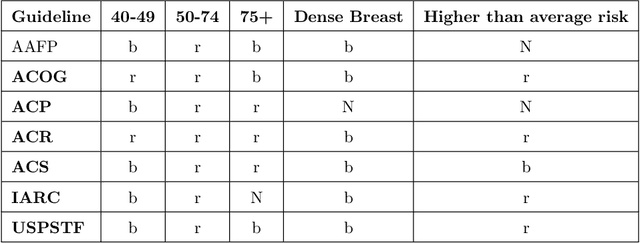
Using natural language processing tools, we investigate the differences of recommendations in medical guidelines for the same decision problem -- breast cancer screening. We show that these differences arise from knowledge brought to the problem by different medical societies, as reflected in the conceptual vocabularies used by the different groups of authors.The computational models we build and analyze agree with the near-peer epistemic model of expert disagreement proposed by Garbayo. Even though the article is a case study focused on one set of guidelines, the proposed methodology is broadly applicable. In addition to proposing a novel graph-based similarity model for comparing collections of documents, we perform an extensive analysis of the model performance. In a series of a few dozen experiments, in three broad categories, we show, at a very high statistical significance level of 3-4 standard deviations for our best models, that the high similarity between expert annotated model and our concept based, automatically created, computational models is not accidental. Our best model achieves roughly 70% similarity. We also describe possible extensions of this work.