 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality extraction from medical text using Large Language Models (LLMs)
Jul 13, 2024



This study explores the potential of natural language models, including large language models, to extract causal relations from medical texts, specifically from Clinical Practice Guidelines (CPGs). The outcomes causality extraction from Clinical Practice Guidelines for gestational diabetes are presented, marking a first in the field. We report on a set of experiments using variants of BERT (BioBERT, DistilBERT, and BERT) and using Large Language Models (LLMs), namely GPT-4 and LLAMA2. Our experiments show that BioBERT performed better than other models, including the Large Language Models, with an average F1-score of 0.72. GPT-4 and LLAMA2 results show similar performance but less consistency. We also release the code and an annotated a corpus of causal statements within the Clinical Practice Guidelines for gestational diabetes.
Computing Conceptual Distances between Breast Cancer Screening Guidelines: An Implementation of a Near-Peer Epistemic Model ofMedical Disagreement
Jul 01, 2020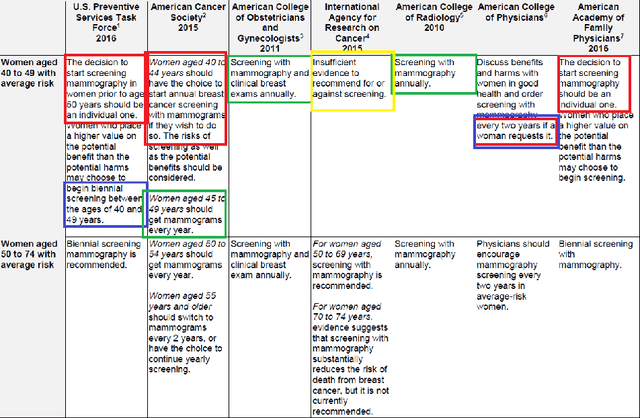
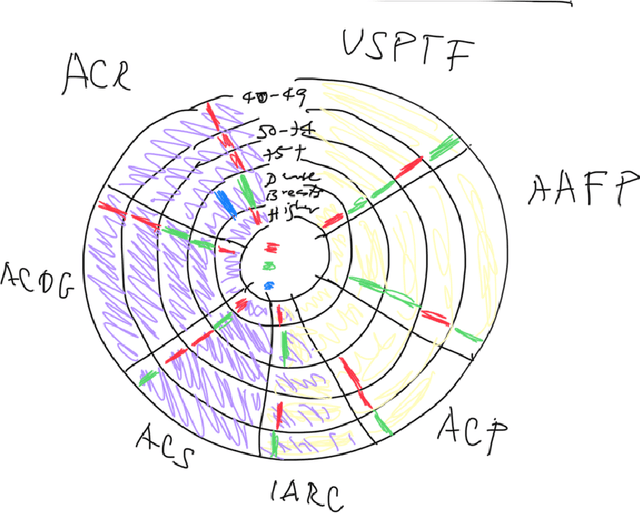
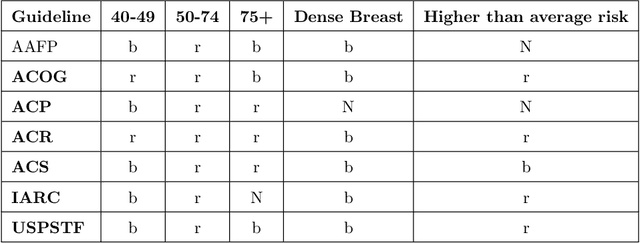
Using natural language processing tools, we investigate the differences of recommendations in medical guidelines for the same decision problem -- breast cancer screening. We show that these differences arise from knowledge brought to the problem by different medical societies, as reflected in the conceptual vocabularies used by the different groups of authors.The computational models we build and analyze agree with the near-peer epistemic model of expert disagreement proposed by Garbayo. Even though the article is a case study focused on one set of guidelines, the proposed methodology is broadly applicable. In addition to proposing a novel graph-based similarity model for comparing collections of documents, we perform an extensive analysis of the model performance. In a series of a few dozen experiments, in three broad categories, we show, at a very high statistical significance level of 3-4 standard deviations for our best models, that the high similarity between expert annotated model and our concept based, automatically created, computational models is not accidental. Our best model achieves roughly 70% similarity. We also describe possible extensions of this work.
A Sheaf Model of Contradictions and Disagreements. Preliminary Report and Discussion
Jan 27, 2018We introduce a new formal model -- based on the mathematical construct of sheaves -- for representing contradictory information in textual sources. This model has the advantage of letting us (a) identify the causes of the inconsistency; (b) measure how strong it is; (c) and do something about it, e.g. suggest ways to reconcile inconsistent advice. This model naturally represents the distinction between contradictions and disagreements. It is based on the idea of representing natural language sentences as formulas with parameters sitting on lattices, creating partial orders based on predicates shared by theories, and building sheaves on these partial orders with products of lattices as stalks. Degrees of disagreement are measured by the existence of global and local sections. Limitations of the sheaf approach and connections to recent work in natural language processing, as well as the topics of contextuality in physics, data fusion, topological data analysis and epistemology are also discussed.
Towards Semantic Modeling of Contradictions and Disagreements: A Case Study of Medical Guidelines
Aug 02, 2017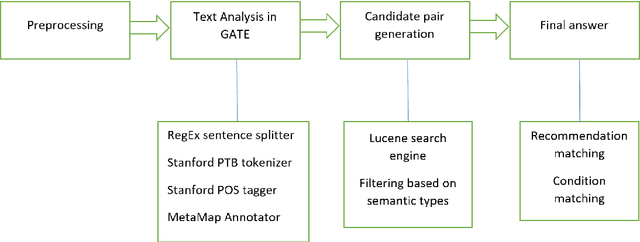
We introduce a formal distinction between contradictions and disagreements in natural language texts, motivated by the need to formally reason about contradictory medical guidelines. This is a novel and potentially very useful distinction, and has not been discussed so far in NLP and logic. We also describe a NLP system capable of automated finding contradictory medical guidelines; the system uses a combination of text analysis and information retrieval modules. We also report positive evaluation results on a small corpus of contradictory medical recommendations.