 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing Conceptual Distances between Breast Cancer Screening Guidelines: An Implementation of a Near-Peer Epistemic Model ofMedical Disagreement
Paper and Code
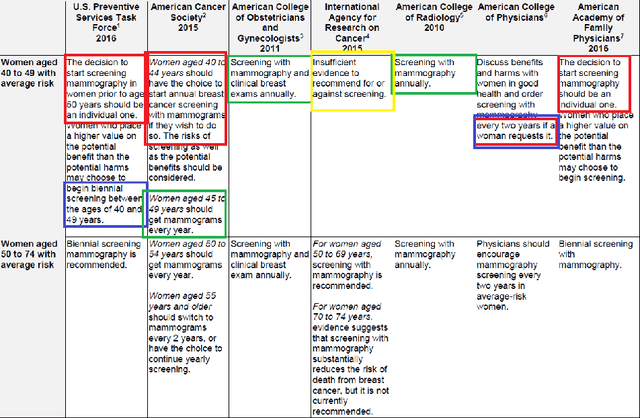
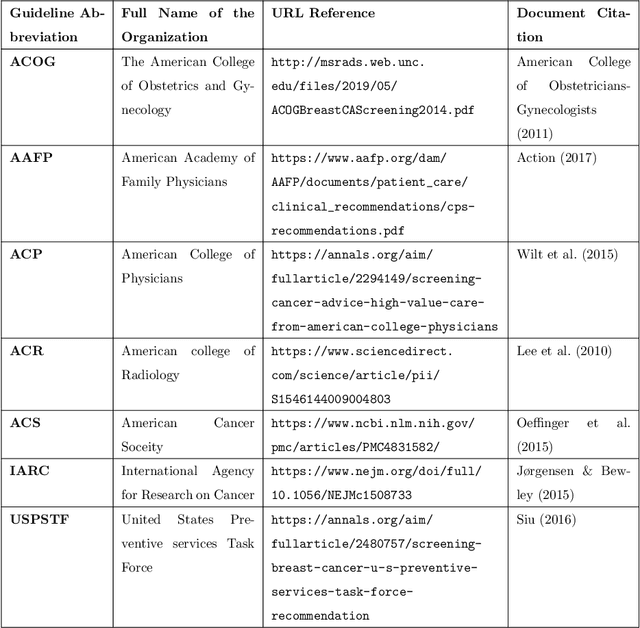
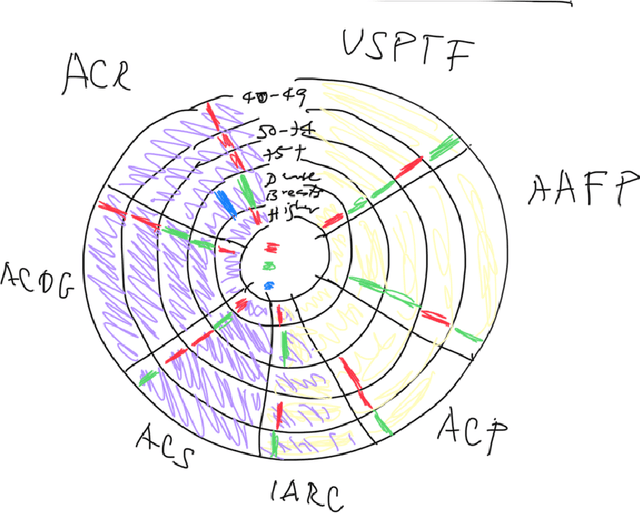
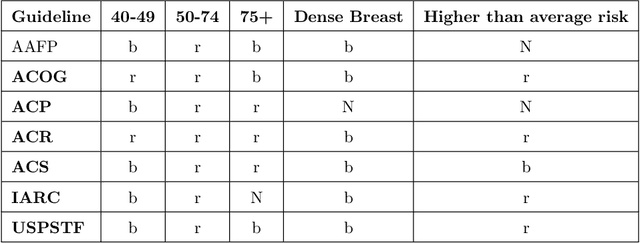
Using natural language processing tools, we investigate the differences of recommendations in medical guidelines for the same decision problem -- breast cancer screening. We show that these differences arise from knowledge brought to the problem by different medical societies, as reflected in the conceptual vocabularies used by the different groups of authors.The computational models we build and analyze agree with the near-peer epistemic model of expert disagreement proposed by Garbayo. Even though the article is a case study focused on one set of guidelines, the proposed methodology is broadly applicable. In addition to proposing a novel graph-based similarity model for comparing collections of documents, we perform an extensive analysis of the model performance. In a series of a few dozen experiments, in three broad categories, we show, at a very high statistical significance level of 3-4 standard deviations for our best models, that the high similarity between expert annotated model and our concept based, automatically created, computational models is not accidental. Our best model achieves roughly 70% similarity. We also describe possible extensions of this work.