 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy-Preserving Framework Using Remote Data Science for Inter-Institutional Student Retention Prediction
Jun 11, 2026This study explores privacy-preserving machine learning (PPML) techniques using the PySyft platform to enable collaborative prediction of student retention between institutions. We developed a remote data science (RDS) framework with a semi-air-gapped architecture consisting of high-side and low-side servers, allowing researchers from three universities to build predictive models on sensitive student data without direct data access. Using historical data from a small private university (N=720), we evaluated three synthetic data generation approaches and validated the framework through inter-institutional collaboration. The results demonstrate consistent classification performance across institutions (Macro F1: 0.690--0.695) while maintaining strict Family Educational Rights and Privacy Act (FERPA) compliance. We also propose Data-Type-Aware Templates, a novel synthetic data method that prioritizes privacy over distributional fidelity. Our findings confirm that RDS-based PPML is technically feasible for educational settings and offers a practical alternative to federated learning for small-scale inter-institutional collaborations. The code is available at https://github.com/jtfields/NAIRR240195-Privacy-Preserving-Machine-Learning.
Memento: Personalized RAG-Style Long-Retention Data Scaling for META Ads Recommendation
May 22, 2026Modeling of long history data suffers from long-context window attention dilution, system efficiency and catastrophic forgetting problems, where naive linear scaling approach like LastN would fail. We introduce Memento, a personalized retrieval-augmented framework that treats historical user engagements as a document corpus and ad requests as queries, retrieving relevant interactions via Maximal Marginal Relevance (MMR) to balance similarity with diversity. We identify two complementary applications: Representation Memento, which retrieves historical embeddings for feature augmentation, and Data Memento, which retrieves past training examples for multipass training. Through infrastructure co-design -- temporal chunking, INT8 quantization, and asynchronous serving -- Memento achieves 5-10$\times$ resource efficiency over linear scaling. Memento processes daily requests with sub-10ms latency, yielding 0.25-0.3% Normalized Entropy gain on both click-through and conversion prediction. In production, Memento delivers a 1% CTR lift on Facebook Feed and Reels and a 1.2% CVR lift, scaling personalization to 365+ days of history.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
A New Era: Intelligent Tutoring Systems Will Transform Online Learning for Millions
Mar 03, 2022
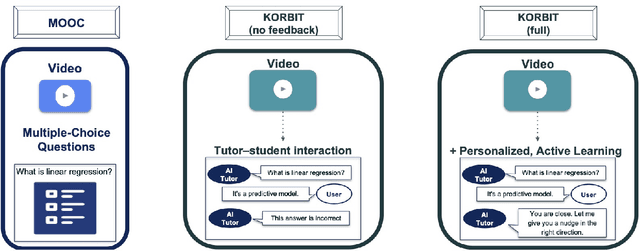
Despite artificial intelligence (AI) having transformed major aspects of our society, less than a fraction of its potential has been explored, let alone deployed, for education. AI-powered learning can provide millions of learners with a highly personalized, active and practical learning experience, which is key to successful learning. This is especially relevant in the context of online learning platforms. In this paper, we present the results of a comparative head-to-head study on learning outcomes for two popular online learning platforms (n=199 participants): A MOOC platform following a traditional model delivering content using lecture videos and multiple-choice quizzes, and the Korbit learning platform providing a highly personalized, active and practical learning experience. We observe a huge and statistically significant increase in the learning outcomes, with students on the Korbit platform providing full feedback resulting in higher course completion rates and achieving learning gains 2 to 2.5 times higher than both students on the MOOC platform and students in a control group who don't receive personalized feedback on the Korbit platform. The results demonstrate the tremendous impact that can be achieved with a personalized, active learning AI-powered system. Making this technology and learning experience available to millions of learners around the world will represent a significant leap forward towards the democratization of education.
Computer-assisted construct classification of organizational performance concerning different stakeholder groups
Jul 11, 2021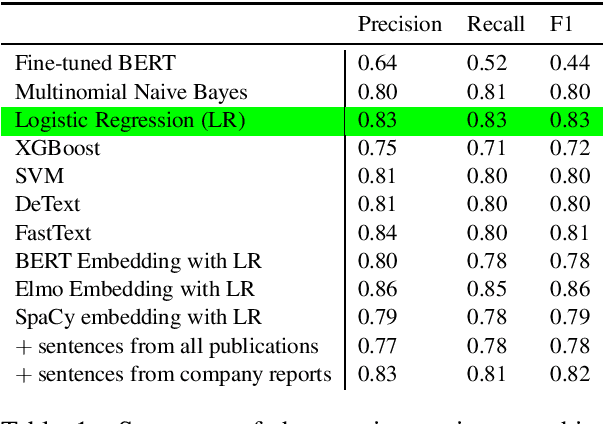
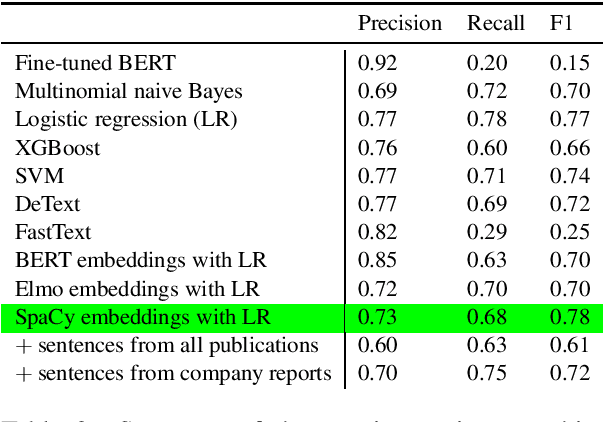
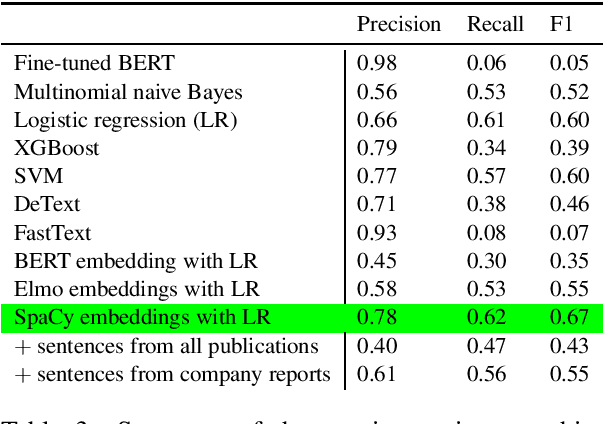
The number of research articles in business and management has dramatically increased along with terminology, constructs, and measures. Proper classification of organizational performance constructs from research articles plays an important role in categorizing the literature and understanding to whom its research implications may be relevant. In this work, we classify constructs (i.e., concepts and terminology used to capture different aspects of organizational performance) in research articles into a three-level categorization: (a) performance and non-performance categories (Level 0); (b) for performance constructs, stakeholder group-level of performance concerning investors, customers, employees, and the society (community and natural environment) (Level 1); and (c) for each stakeholder group-level, subcategories of different ways of measurement (Level 2). We observed that increasing contextual information with features extracted from surrounding sentences and external references improves classification of disaggregate-level labels, given limited training data. Our research has implications for computer-assisted construct identification and classification - an essential step for research synthesis.
My Team Will Go On: Differentiating High and Low Viability Teams through Team Interaction
Nov 03, 2020
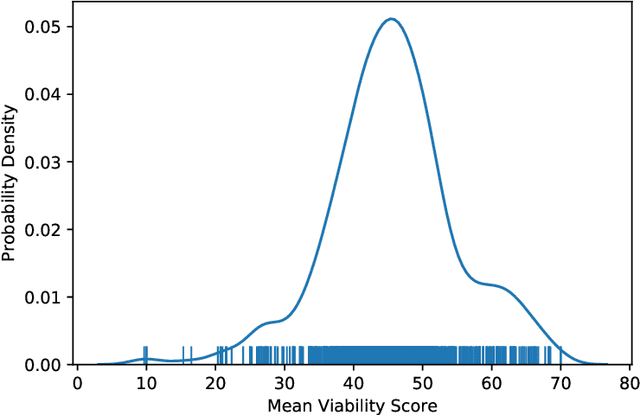
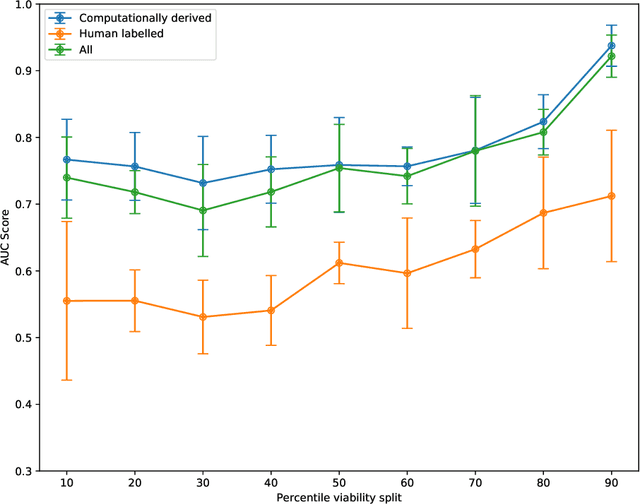
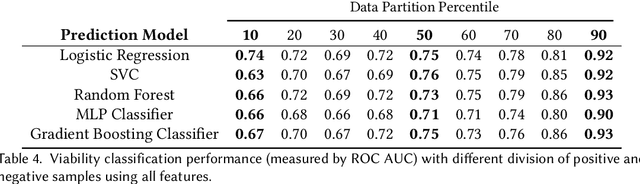
Understanding team viability -- a team's capacity for sustained and future success -- is essential for building effective teams. In this study, we aggregate features drawn from the organizational behavior literature to train a viability classification model over a dataset of 669 10-minute text conversations of online teams. We train classifiers to identify teams at the top decile (most viable teams), 50th percentile (above a median split), and bottom decile (least viable teams), then characterize the attributes of teams at each of these viability levels. We find that a lasso regression model achieves an accuracy of .74--.92 AUC ROC under different thresholds of classifying viability scores. From these models, we identify the use of exclusive language such as `but' and `except', and the use of second person pronouns, as the most predictive features for detecting the most viable teams, suggesting that active engagement with others' ideas is a crucial signal of a viable team. Only a small fraction of the 10-minute discussion, as little as 70 seconds, is required for predicting the viability of team interaction. This work suggests opportunities for teams to assess, track, and visualize their own viability in real time as they collaborate.
* CSCW 2020 Honorable Mention Award
Robust MCMC Sampling with Non-Gaussian and Hierarchical Priors in High Dimensions
Mar 09, 2018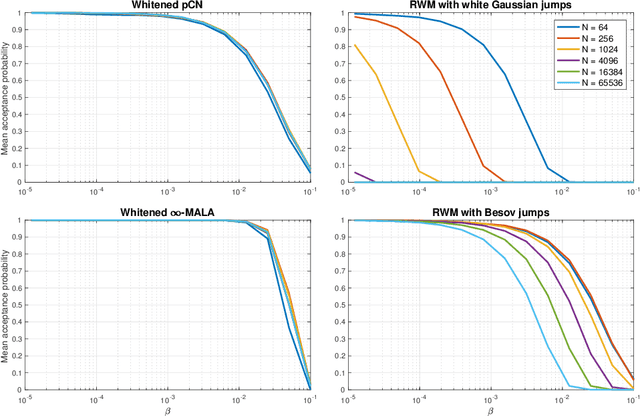
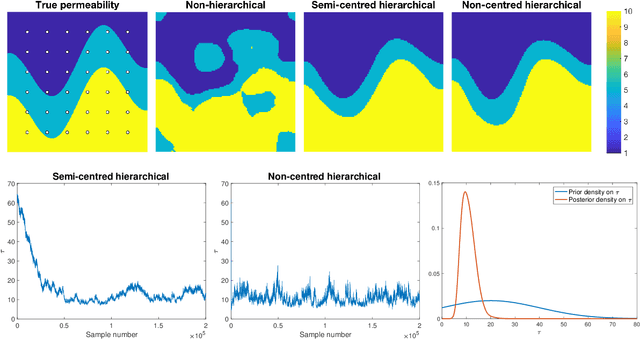
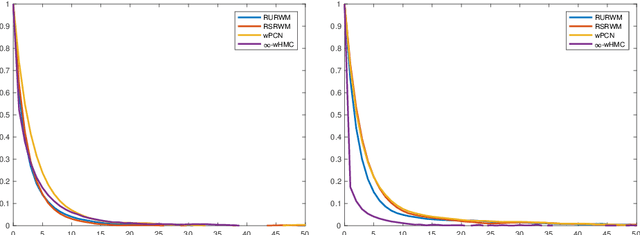
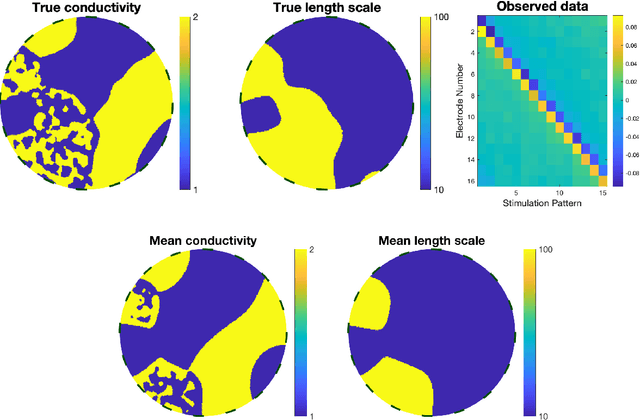
A key problem in inference for high dimensional unknowns is the design of sampling algorithms whose performance scales favourably with the dimension of the unknown. A typical setting in which these problems arise is the area of Bayesian inverse problems. In such problems, which include graph-based learning, nonparametric regression and PDE-based inversion, the unknown can be viewed as an infinite-dimensional parameter (such as a function) that has been discretised. This results in a high-dimensional space for inference. Here we study robustness of an MCMC algorithm for posterior inference; this refers to MCMC convergence rates that do not deteriorate as the discretisation becomes finer. When a Gaussian prior is employed there is a known methodology for the design of robust MCMC samplers. However, one often requires more flexibility than a Gaussian prior can provide: hierarchical models are used to enable inference of parameters underlying a Gaussian prior; or non-Gaussian priors, such as Besov, are employed to induce sparse MAP estimators; or deep Gaussian priors are used to represent other non-Gaussian phenomena; and piecewise constant functions, which are necessarily non-Gaussian, are required for classification problems. The purpose of this article is to show that the simulation technology available for Gaussian priors can be exported to such non-Gaussian priors. The underlying methodology is based on a white noise representation of the unknown. This is exploited both for robust posterior sampling and for joint inference of the function and parameters involved in the specification of its prior, in which case our framework borrows strength from the well-developed non-centred methodology for Bayesian hierarchical models. The desired robustness of the proposed sampling algorithms is supported by some theory and by extensive numerical evidence from several challenging problems.