 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjugate gradient methods for high-dimensional GLMMs
Nov 07, 2024Generalized linear mixed models (GLMMs) are a widely used tool in statistical analysis. The main bottleneck of many computational approaches lies in the inversion of the high dimensional precision matrices associated with the random effects. Such matrices are typically sparse; however, the sparsity pattern resembles a multi partite random graph, which does not lend itself well to default sparse linear algebra techniques. Notably, we show that, for typical GLMMs, the Cholesky factor is dense even when the original precision is sparse. We thus turn to approximate iterative techniques, in particular to the conjugate gradient (CG) method. We combine a detailed analysis of the spectrum of said precision matrices with results from random graph theory to show that CG-based methods applied to high-dimensional GLMMs typically achieve a fixed approximation error with a total cost that scales linearly with the number of parameters and observations. Numerical illustrations with both real and simulated data confirm the theoretical findings, while at the same time illustrating situations, such as nested structures, where CG-based methods struggle.
Partially factorized variational inference for high-dimensional mixed models
Dec 20, 2023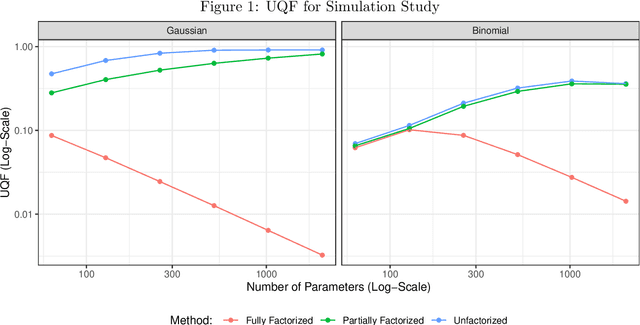

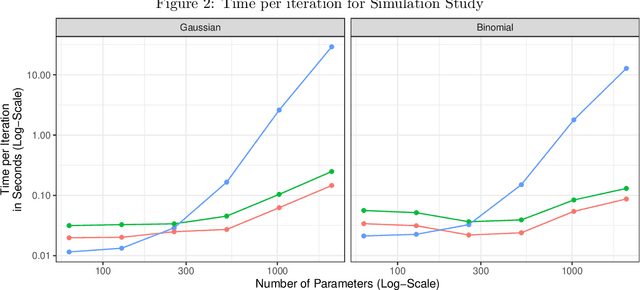
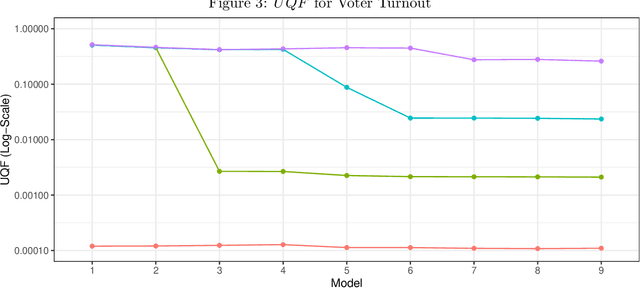
While generalized linear mixed models (GLMMs) are a fundamental tool in applied statistics, many specifications -- such as those involving categorical factors with many levels or interaction terms -- can be computationally challenging to estimate due to the need to compute or approximate high-dimensional integrals. Variational inference (VI) methods are a popular way to perform such computations, especially in the Bayesian context. However, naive VI methods can provide unreliable uncertainty quantification. We show that this is indeed the case in the GLMM context, proving that standard VI (i.e. mean-field) dramatically underestimates posterior uncertainty in high-dimensions. We then show how appropriately relaxing the mean-field assumption leads to VI methods whose uncertainty quantification does not deteriorate in high-dimensions, and whose total computational cost scales linearly with the number of parameters and observations. Our theoretical and numerical results focus on GLMMs with Gaussian or binomial likelihoods, and rely on connections to random graph theory to obtain sharp high-dimensional asymptotic analysis. We also provide generic results, which are of independent interest, relating the accuracy of variational inference to the convergence rate of the corresponding coordinate ascent variational inference (CAVI) algorithm for Gaussian targets. Our proposed partially-factorized VI (PF-VI) methodology for GLMMs is implemented in the R package vglmer, see https://github.com/mgoplerud/vglmer . Numerical results with simulated and real data examples illustrate the favourable computation cost versus accuracy trade-off of PF-VI.
Scalable inference for crossed random effects models
Mar 26, 2018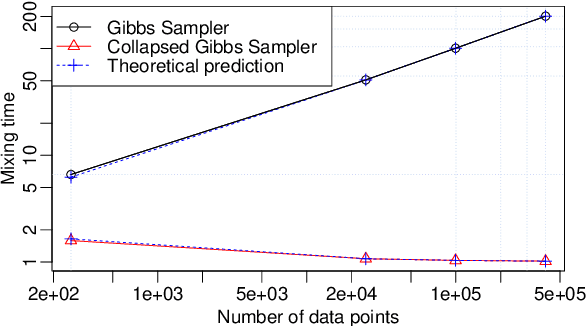
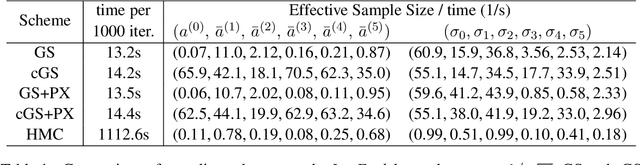
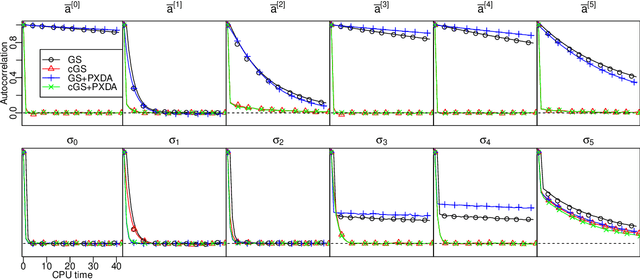
We analyze the complexity of Gibbs samplers for inference in crossed random effect models used in modern analysis of variance. We demonstrate that for certain designs the plain vanilla Gibbs sampler is not scalable, in the sense that its complexity is worse than proportional to the number of parameters and data. We thus propose a simple modification leading to a collapsed Gibbs sampler that is provably scalable. Although our theory requires some balancedness assumptions on the data designs, we demonstrate in simulated and real datasets that the rates it predicts match remarkably the correct rates in cases where the assumptions are violated. We also show that the collapsed Gibbs sampler, extended to sample further unknown hyperparameters, outperforms significantly alternative state of the art algorithms.
Robust MCMC Sampling with Non-Gaussian and Hierarchical Priors in High Dimensions
Mar 09, 2018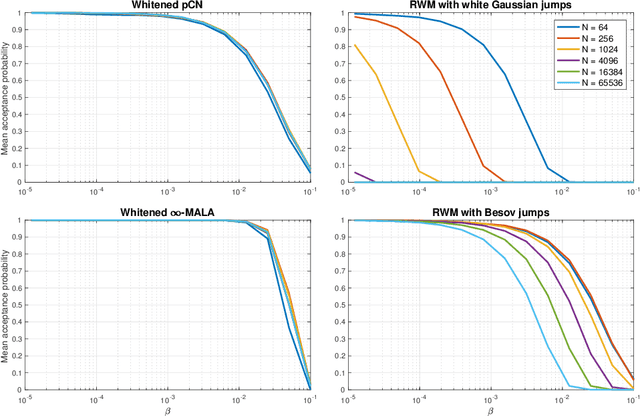
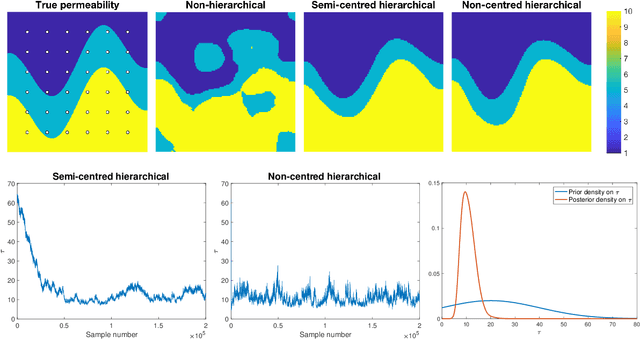
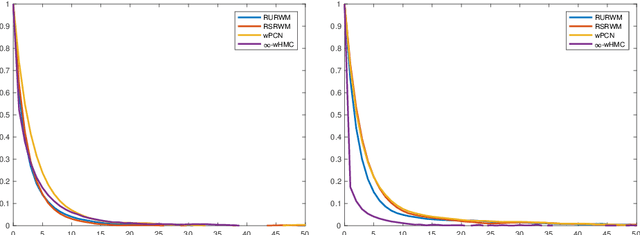
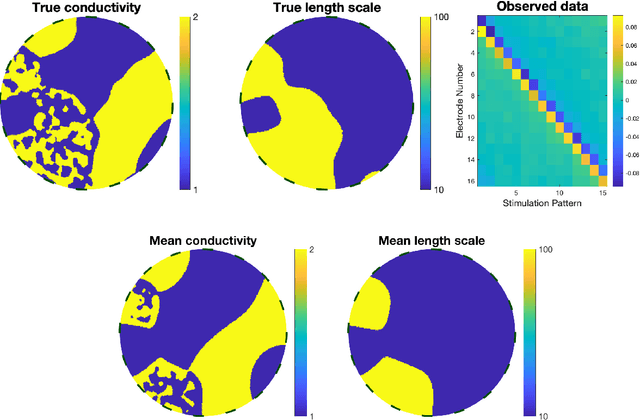
A key problem in inference for high dimensional unknowns is the design of sampling algorithms whose performance scales favourably with the dimension of the unknown. A typical setting in which these problems arise is the area of Bayesian inverse problems. In such problems, which include graph-based learning, nonparametric regression and PDE-based inversion, the unknown can be viewed as an infinite-dimensional parameter (such as a function) that has been discretised. This results in a high-dimensional space for inference. Here we study robustness of an MCMC algorithm for posterior inference; this refers to MCMC convergence rates that do not deteriorate as the discretisation becomes finer. When a Gaussian prior is employed there is a known methodology for the design of robust MCMC samplers. However, one often requires more flexibility than a Gaussian prior can provide: hierarchical models are used to enable inference of parameters underlying a Gaussian prior; or non-Gaussian priors, such as Besov, are employed to induce sparse MAP estimators; or deep Gaussian priors are used to represent other non-Gaussian phenomena; and piecewise constant functions, which are necessarily non-Gaussian, are required for classification problems. The purpose of this article is to show that the simulation technology available for Gaussian priors can be exported to such non-Gaussian priors. The underlying methodology is based on a white noise representation of the unknown. This is exploited both for robust posterior sampling and for joint inference of the function and parameters involved in the specification of its prior, in which case our framework borrows strength from the well-developed non-centred methodology for Bayesian hierarchical models. The desired robustness of the proposed sampling algorithms is supported by some theory and by extensive numerical evidence from several challenging problems.
Auxiliary gradient-based sampling algorithms
Jan 25, 2018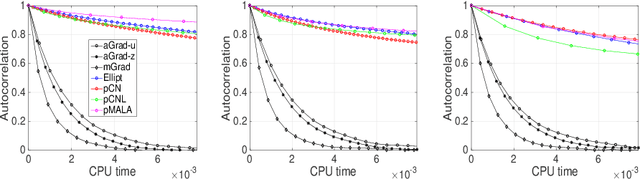
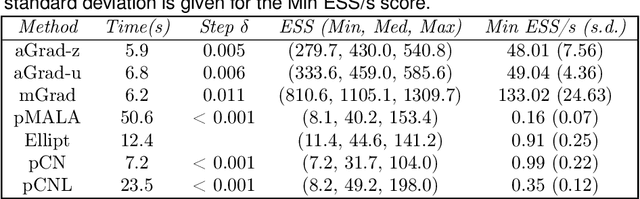

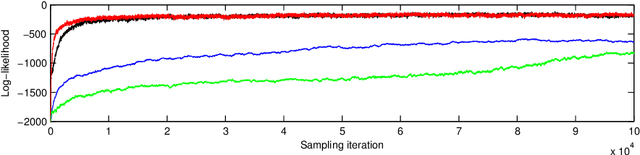
We introduce a new family of MCMC samplers that combine auxiliary variables, Gibbs sampling and Taylor expansions of the target density. Our approach permits the marginalisation over the auxiliary variables yielding marginal samplers, or the augmentation of the auxiliary variables, yielding auxiliary samplers. The well-known Metropolis-adjusted Langevin algorithm (MALA) and preconditioned Crank-Nicolson Langevin (pCNL) algorithm are shown to be special cases. We prove that marginal samplers are superior in terms of asymptotic variance and demonstrate cases where they are slower in computing time compared to auxiliary samplers. In the context of latent Gaussian models we propose new auxiliary and marginal samplers whose implementation requires a single tuning parameter, which can be found automatically during the transient phase. Extensive experimentation shows that the increase in efficiency (measured as effective sample size per unit of computing time) relative to (optimised implementations of) pCNL, elliptical slice sampling and MALA ranges from 10-fold in binary classification problems to 25-fold in log-Gaussian Cox processes to 100-fold in Gaussian process regression, and it is on par with Riemann manifold Hamiltonian Monte Carlo in an example where the latter has the same complexity as the aforementioned algorithms. We explain this remarkable improvement in terms of the way alternative samplers try to approximate the eigenvalues of the target. We introduce a novel MCMC sampling scheme for hyperparameter learning that builds upon the auxiliary samplers. The MATLAB code for reproducing the experiments in the article is publicly available and a Supplement to this article contains additional experiments and implementation details.
Online Multi-task Learning with Hard Constraints
Mar 27, 2009We discuss multi-task online learning when a decision maker has to deal simultaneously with M tasks. The tasks are related, which is modeled by imposing that the M-tuple of actions taken by the decision maker needs to satisfy certain constraints. We give natural examples of such restrictions and then discuss a general class of tractable constraints, for which we introduce computationally efficient ways of selecting actions, essentially by reducing to an on-line shortest path problem. We briefly discuss "tracking" and "bandit" versions of the problem and extend the model in various ways, including non-additive global losses and uncountably infinite sets of tasks.