 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Reading of Hypotheses for Organizational Research Reviews and Pre-trained Models via R Shiny App for Non-Programmers
Jul 11, 2021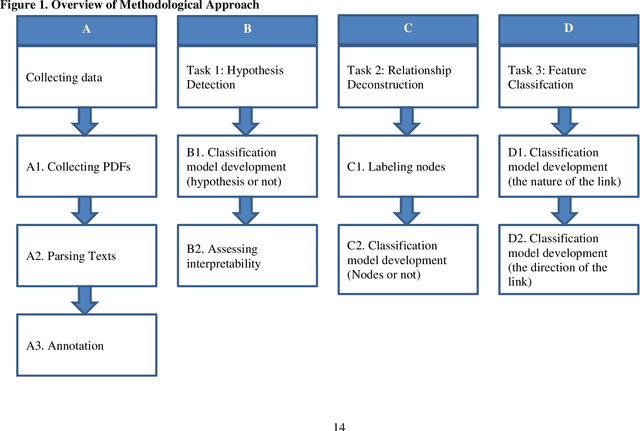


The volume of scientific publications in organizational research becomes exceedingly overwhelming for human researchers who seek to timely extract and review knowledge. This paper introduces natural language processing (NLP) models to accelerate the discovery, extraction, and organization of theoretical developments (i.e., hypotheses) from social science publications. We illustrate and evaluate NLP models in the context of a systematic review of stakeholder value constructs and hypotheses. Specifically, we develop NLP models to automatically 1) detect sentences in scholarly documents as hypotheses or not (Hypothesis Detection), 2) deconstruct the hypotheses into nodes (constructs) and links (causal/associative relationships) (Relationship Deconstruction ), and 3) classify the features of links in terms causality (versus association) and direction (positive, negative, versus nonlinear) (Feature Classification). Our models have reported high performance metrics for all three tasks. While our models are built in Python, we have made the pre-trained models fully accessible for non-programmers. We have provided instructions on installing and using our pre-trained models via an R Shiny app graphic user interface (GUI). Finally, we suggest the next paths to extend our methodology for computer-assisted knowledge synthesis.