 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Stakeholder-Material Information from 10-K Reports using Fine-Tuned BERT and LSTM Models
Aug 15, 2023All public companies are required by federal securities law to disclose their business and financial activities in their annual 10-K reports. Each report typically spans hundreds of pages, making it difficult for human readers to identify and extract the material information efficiently. To solve the problem, I have fine-tuned BERT models and RNN models with LSTM layers to identify stakeholder-material information, defined as statements that carry information about a company's influence on its stakeholders, including customers, employees, investors, and the community and natural environment. The existing practice uses keyword search to identify such information, which is my baseline model. Using business expert-labeled training data of nearly 6,000 sentences from 62 10-K reports published in 2022, the best model has achieved an accuracy of 0.904 and an F1 score of 0.899 in test data, significantly above the baseline model's 0.781 and 0.749 respectively. Furthermore, the same work was replicated on more granular taxonomies, based on which four distinct groups of stakeholders (i.e., customers, investors, employees, and the community and natural environment) are tested separately. Similarly, fined-tuned BERT models outperformed LSTM and the baseline. The implications for industry application and ideas for future extensions are discussed.
Machine Reading of Hypotheses for Organizational Research Reviews and Pre-trained Models via R Shiny App for Non-Programmers
Jul 11, 2021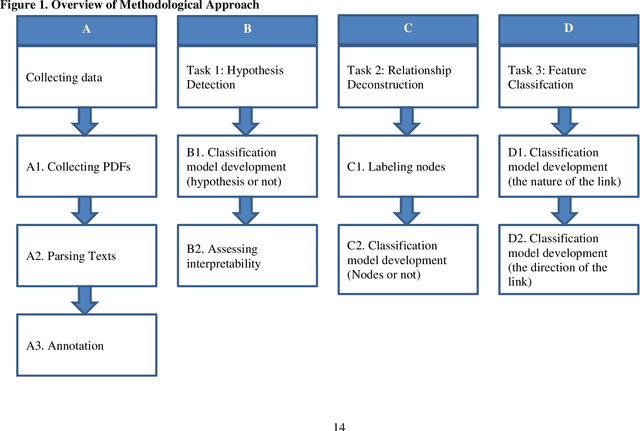

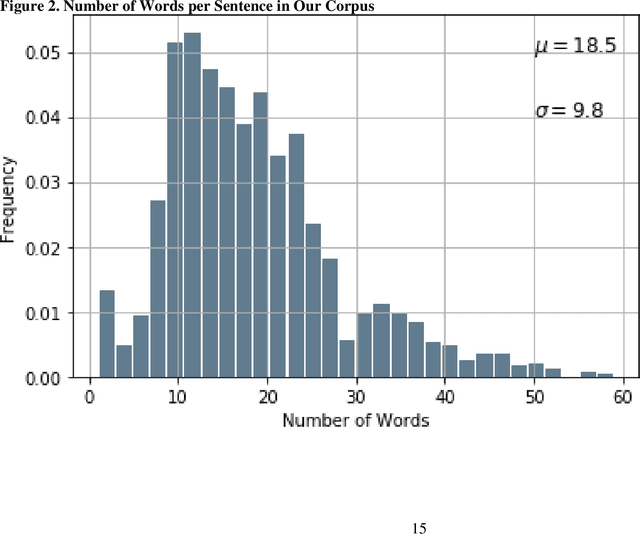

The volume of scientific publications in organizational research becomes exceedingly overwhelming for human researchers who seek to timely extract and review knowledge. This paper introduces natural language processing (NLP) models to accelerate the discovery, extraction, and organization of theoretical developments (i.e., hypotheses) from social science publications. We illustrate and evaluate NLP models in the context of a systematic review of stakeholder value constructs and hypotheses. Specifically, we develop NLP models to automatically 1) detect sentences in scholarly documents as hypotheses or not (Hypothesis Detection), 2) deconstruct the hypotheses into nodes (constructs) and links (causal/associative relationships) (Relationship Deconstruction ), and 3) classify the features of links in terms causality (versus association) and direction (positive, negative, versus nonlinear) (Feature Classification). Our models have reported high performance metrics for all three tasks. While our models are built in Python, we have made the pre-trained models fully accessible for non-programmers. We have provided instructions on installing and using our pre-trained models via an R Shiny app graphic user interface (GUI). Finally, we suggest the next paths to extend our methodology for computer-assisted knowledge synthesis.
Causal Knowledge Extraction from Scholarly Papers in Social Sciences
Jun 16, 2020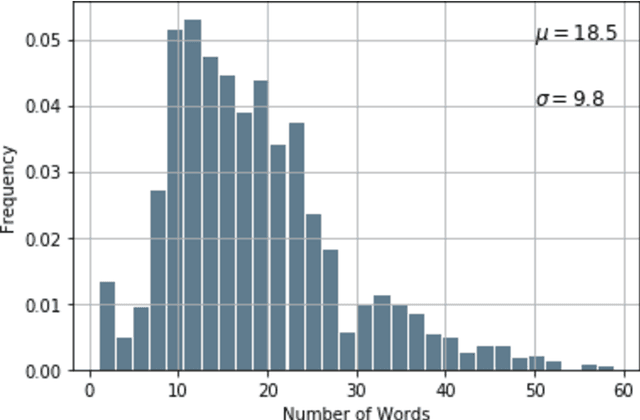


The scale and scope of scholarly articles today are overwhelming human researchers who seek to timely digest and synthesize knowledge. In this paper, we seek to develop natural language processing (NLP) models to accelerate the speed of extraction of relationships from scholarly papers in social sciences, identify hypotheses from these papers, and extract the cause-and-effect entities. Specifically, we develop models to 1) classify sentences in scholarly documents in business and management as hypotheses (hypothesis classification), 2) classify these hypotheses as causal relationships or not (causality classification), and, if they are causal, 3) extract the cause and effect entities from these hypotheses (entity extraction). We have achieved high performance for all the three tasks using different modeling techniques. Our approach may be generalizable to scholarly documents in a wide range of social sciences, as well as other types of textual materials.