 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Knowledge Extraction from Scholarly Papers in Social Sciences
Paper and Code
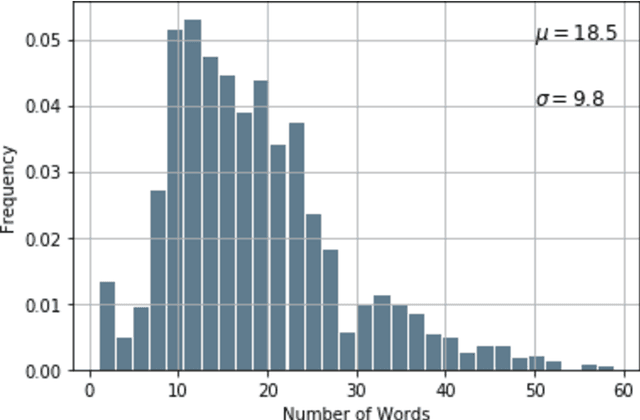
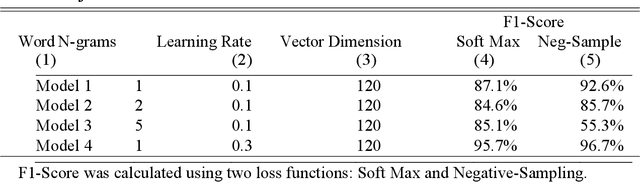


The scale and scope of scholarly articles today are overwhelming human researchers who seek to timely digest and synthesize knowledge. In this paper, we seek to develop natural language processing (NLP) models to accelerate the speed of extraction of relationships from scholarly papers in social sciences, identify hypotheses from these papers, and extract the cause-and-effect entities. Specifically, we develop models to 1) classify sentences in scholarly documents in business and management as hypotheses (hypothesis classification), 2) classify these hypotheses as causal relationships or not (causality classification), and, if they are causal, 3) extract the cause and effect entities from these hypotheses (entity extraction). We have achieved high performance for all the three tasks using different modeling techniques. Our approach may be generalizable to scholarly documents in a wide range of social sciences, as well as other types of textual materials.