 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Method of Extracting Topological Features from Word Embeddings
Apr 19, 2020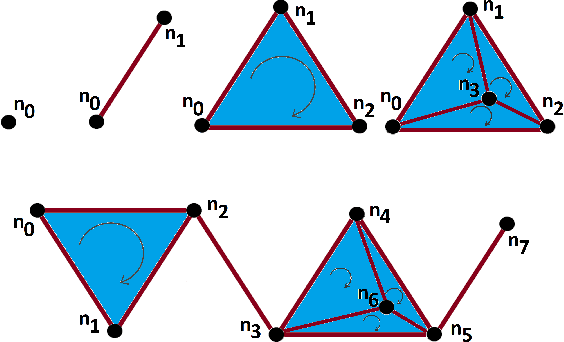

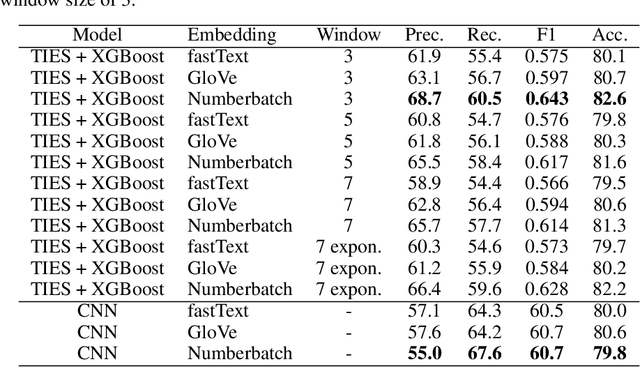
In recent years, topological data analysis has been utilized for a wide range of problems to deal with high dimensional noisy data. While text representations are often high dimensional and noisy, there are only a few work on the application of topological data analysis in natural language processing. In this paper, we introduce a novel algorithm to extract topological features from word embedding representation of text that can be used for text classification. Working on word embeddings, topological data analysis can interpret the embedding high-dimensional space and discover the relations among different embedding dimensions. We will use persistent homology, the most commonly tool from topological data analysis, for our experiment. Examining our topological algorithm on long textual documents, we will show our defined topological features may outperform conventional text mining features.
Topological Data Analysis in Text Classification: Extracting Features with Additive Information
Mar 29, 2020
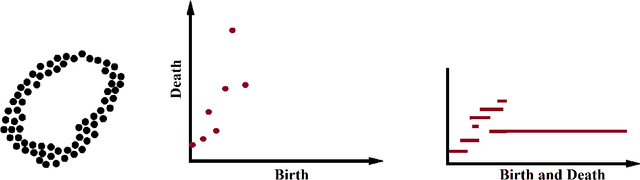

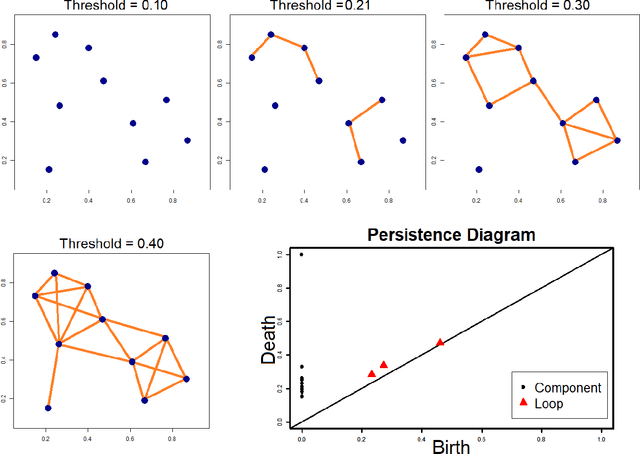
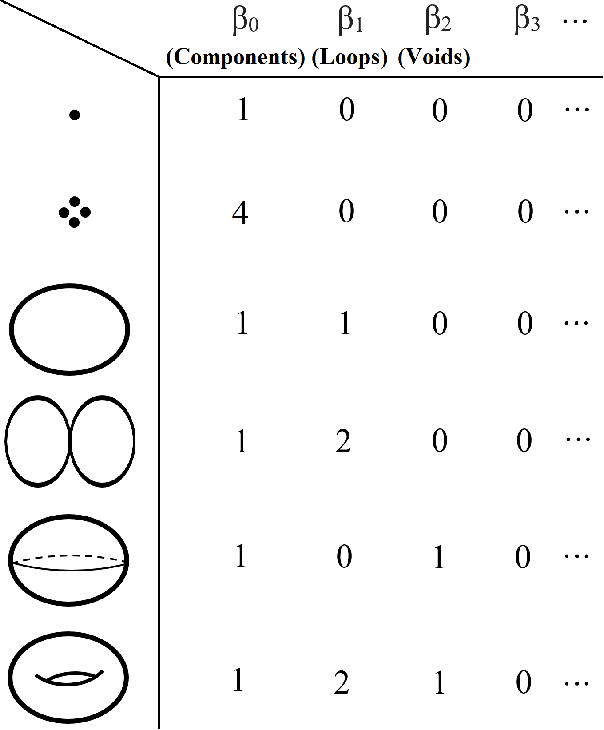
While the strength of Topological Data Analysis has been explored in many studies on high dimensional numeric data, it is still a challenging task to apply it to text. As the primary goal in topological data analysis is to define and quantify the shapes in numeric data, defining shapes in the text is much more challenging, even though the geometries of vector spaces and conceptual spaces are clearly relevant for information retrieval and semantics. In this paper, we examine two different methods of extraction of topological features from text, using as the underlying representations of words the two most popular methods, namely word embeddings and TF-IDF vectors. To extract topological features from the word embedding space, we interpret the embedding of a text document as high dimensional time series, and we analyze the topology of the underlying graph where the vertices correspond to different embedding dimensions. For topological data analysis with the TF-IDF representations, we analyze the topology of the graph whose vertices come from the TF-IDF vectors of different blocks in the textual document. In both cases, we apply homological persistence to reveal the geometric structures under different distance resolutions. Our results show that these topological features carry some exclusive information that is not captured by conventional text mining methods. In our experiments we observe adding topological features to the conventional features in ensemble models improves the classification results (up to 5\%). On the other hand, as expected, topological features by themselves may be not sufficient for effective classification. It is an open problem to see whether TDA features from word embeddings might be sufficient, as they seem to perform within a range of few points from top results obtained with a linear support vector classifier.
Emotion Detection in Text: Focusing on Latent Representation
Jul 22, 2019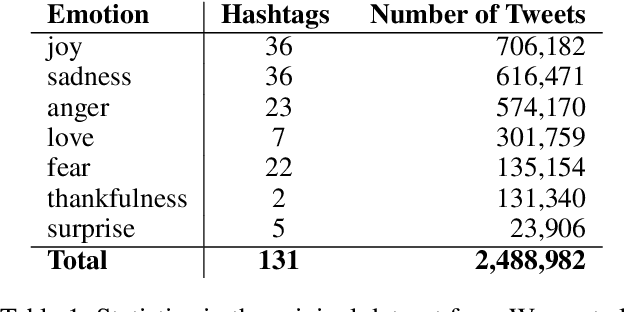
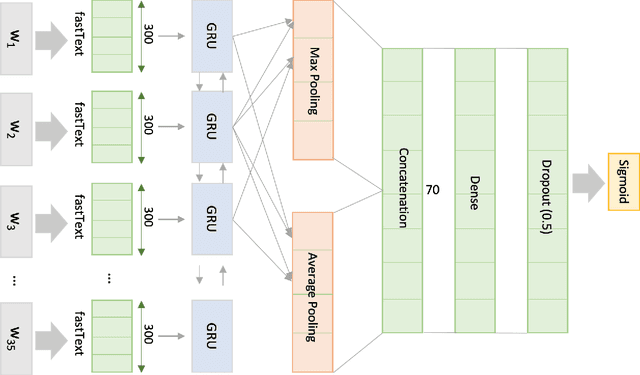

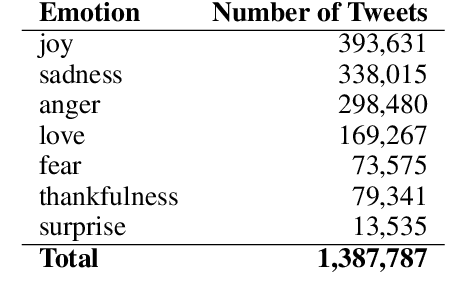
In recent years, emotion detection in text has become more popular due to its vast potential applications in marketing, political science, psychology, human-computer interaction, artificial intelligence, etc. In this work, we argue that current methods which are based on conventional machine learning models cannot grasp the intricacy of emotional language by ignoring the sequential nature of the text, and the context. These methods, therefore, are not sufficient to create an applicable and generalizable emotion detection methodology. Understanding these limitations, we present a new network based on a bidirectional GRU model to show that capturing more meaningful information from text can significantly improve the performance of these models. The results show significant improvement with an average of 26.8 point increase in F-measure on our test data and 38.6 increase on the totally new dataset.
Emotional Embeddings: Refining Word Embeddings to Capture Emotional Content of Words
May 31, 2019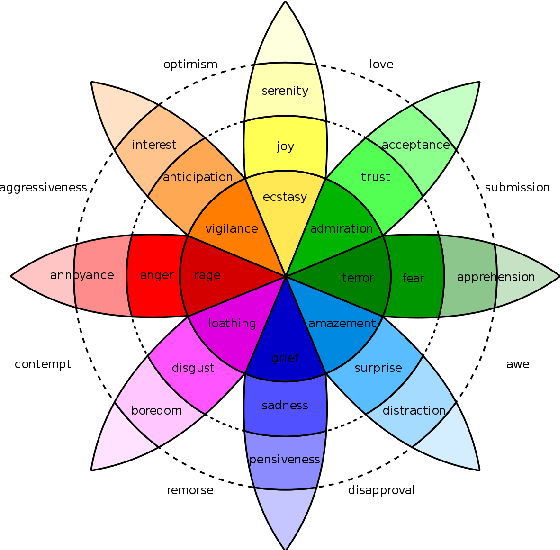
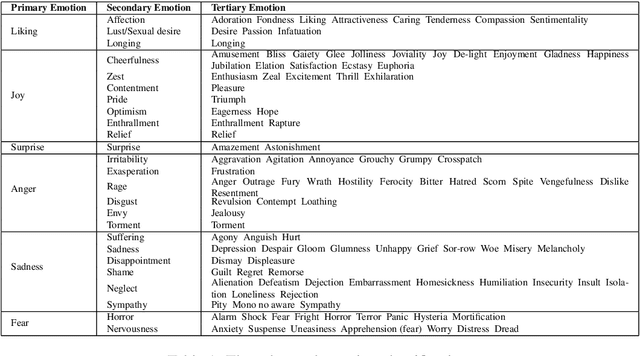

Word embeddings are one of the most useful tools in any modern natural language processing expert's toolkit. They contain various types of information about each word which makes them the best way to represent the terms in any NLP task. But there are some types of information that cannot be learned by these models. Emotional information of words are one of those. In this paper, we present an approach to incorporate emotional information of words into these models. We accomplish this by adding a secondary training stage which uses an emotional lexicon and a psychological model of basic emotions. We show that fitting an emotional model into pre-trained word vectors can increase the performance of these models in emotional similarity metrics. Retrained models perform better than their original counterparts from 13% improvement for Word2Vec model, to 29% for GloVe vectors. This is the first such model presented in the literature, and although preliminary, these emotion sensitive models can open the way to increase performance in variety of emotion detection techniques.
Emotion Detection in Text: a Review
Jun 02, 2018In recent years, emotion detection in text has become more popular due to its vast potential applications in marketing, political science, psychology, human-computer interaction, artificial intelligence, etc. Access to a huge amount of textual data, especially opinionated and self-expression text also played a special role to bring attention to this field. In this paper, we review the work that has been done in identifying emotion expressions in text and argue that although many techniques, methodologies, and models have been created to detect emotion in text, there are various reasons that make these methods insufficient. Although, there is an essential need to improve the design and architecture of current systems, factors such as the complexity of human emotions, and the use of implicit and metaphorical language in expressing it, lead us to think that just re-purposing standard methodologies will not be enough to capture these complexities, and it is important to pay attention to the linguistic intricacies of emotion expression.