 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-based Session Recommendation with Adaptive Propagation
Feb 17, 2024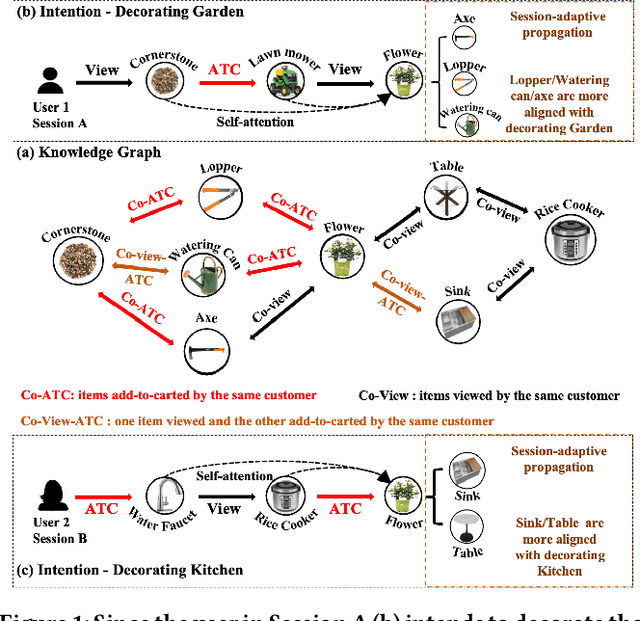
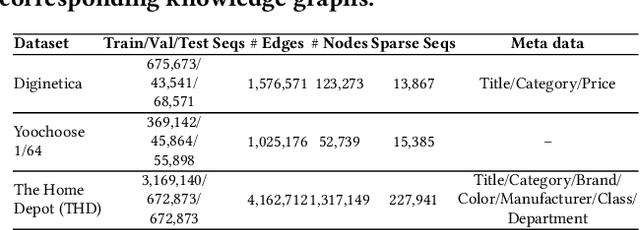

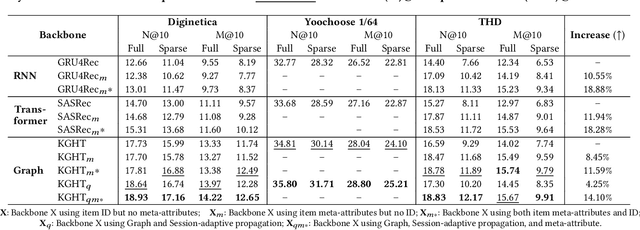
Session-based recommender systems (SBRSs) predict users' next interacted items based on their historical activities. While most SBRSs capture purchasing intentions locally within each session, capturing items' global information across different sessions is crucial in characterizing their general properties. Previous works capture this cross-session information by constructing graphs and incorporating neighbor information. However, this incorporation cannot vary adaptively according to the unique intention of each session, and the constructed graphs consist of only one type of user-item interaction. To address these limitations, we propose knowledge graph-based session recommendation with session-adaptive propagation. Specifically, we build a knowledge graph by connecting items with multi-typed edges to characterize various user-item interactions. Then, we adaptively aggregate items' neighbor information considering user intention within the learned session. Experimental results demonstrate that equipping our constructed knowledge graph and session-adaptive propagation enhances session recommendation backbones by 10%-20%. Moreover, we provide an industrial case study showing our proposed framework achieves 2% performance boost over an existing well-deployed model at The Home Depot e-platform.
Hierarchical Multi-Task Learning Framework for Session-based Recommendations
Sep 12, 2023
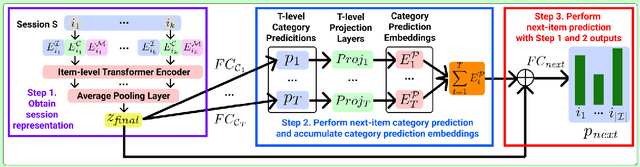

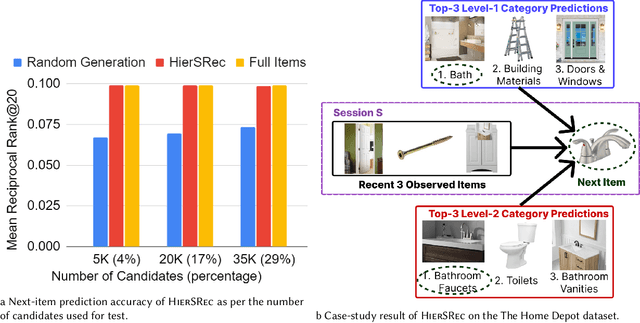
While session-based recommender systems (SBRSs) have shown superior recommendation performance, multi-task learning (MTL) has been adopted by SBRSs to enhance their prediction accuracy and generalizability further. Hierarchical MTL (H-MTL) sets a hierarchical structure between prediction tasks and feeds outputs from auxiliary tasks to main tasks. This hierarchy leads to richer input features for main tasks and higher interpretability of predictions, compared to existing MTL frameworks. However, the H-MTL framework has not been investigated in SBRSs yet. In this paper, we propose HierSRec which incorporates the H-MTL architecture into SBRSs. HierSRec encodes a given session with a metadata-aware Transformer and performs next-category prediction (i.e., auxiliary task) with the session encoding. Next, HierSRec conducts next-item prediction (i.e., main task) with the category prediction result and session encoding. For scalable inference, HierSRec creates a compact set of candidate items (e.g., 4% of total items) per test example using the category prediction. Experiments show that HierSRec outperforms existing SBRSs as per next-item prediction accuracy on two session-based recommendation datasets. The accuracy of HierSRec measured with the carefully-curated candidate items aligns with the accuracy of HierSRec calculated with all items, which validates the usefulness of our candidate generation scheme via H-MTL.
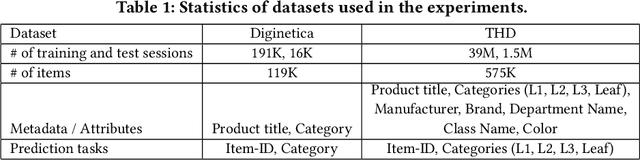
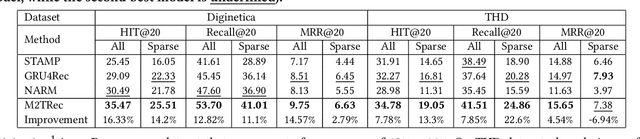
M2TRec: Metadata-aware Multi-task Transformer for Large-scale and Cold-start free Session-based Recommendations
Sep 23, 2022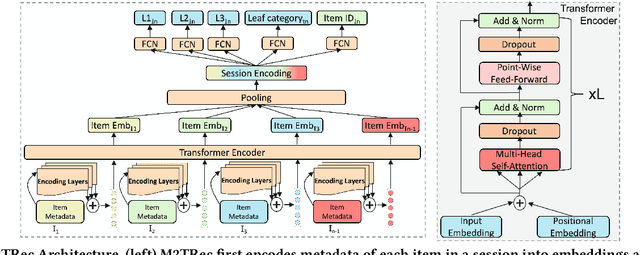
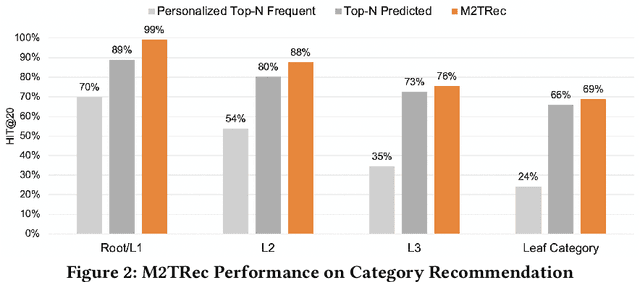
Session-based recommender systems (SBRSs) have shown superior performance over conventional methods. However, they show limited scalability on large-scale industrial datasets since most models learn one embedding per item. This leads to a large memory requirement (of storing one vector per item) and poor performance on sparse sessions with cold-start or unpopular items. Using one public and one large industrial dataset, we experimentally show that state-of-the-art SBRSs have low performance on sparse sessions with sparse items. We propose M2TRec, a Metadata-aware Multi-task Transformer model for session-based recommendations. Our proposed method learns a transformation function from item metadata to embeddings, and is thus, item-ID free (i.e., does not need to learn one embedding per item). It integrates item metadata to learn shared representations of diverse item attributes. During inference, new or unpopular items will be assigned identical representations for the attributes they share with items previously observed during training, and thus will have similar representations with those items, enabling recommendations of even cold-start and sparse items. Additionally, M2TRec is trained in a multi-task setting to predict the next item in the session along with its primary category and subcategories. Our multi-task strategy makes the model converge faster and significantly improves the overall performance. Experimental results show significant performance gains using our proposed approach on sparse items on the two datasets.
* Accepted at the 16th ACM Conference on Recommender Systems (RecSys '22)
Building chatbots from large scale domain-specific knowledge bases: challenges and opportunities
Dec 31, 2019



Popular conversational agents frameworks such as Alexa Skills Kit (ASK) and Google Actions (gActions) offer unprecedented opportunities for facilitating the development and deployment of voice-enabled AI solutions in various verticals. Nevertheless, understanding user utterances with high accuracy remains a challenging task with these frameworks. Particularly, when building chatbots with large volume of domain-specific entities. In this paper, we describe the challenges and lessons learned from building a large scale virtual assistant for understanding and responding to equipment-related complaints. In the process, we describe an alternative scalable framework for: 1) extracting the knowledge about equipment components and their associated problem entities from short texts, and 2) learning to identify such entities in user utterances. We show through evaluation on a real dataset that the proposed framework, compared to off-the-shelf popular ones, scales better with large volume of entities being up to 30% more accurate, and is more effective in understanding user utterances with domain-specific entities.
Beyond Word Embeddings: Learning Entity and Concept Representations from Large Scale Knowledge Bases
Aug 30, 2018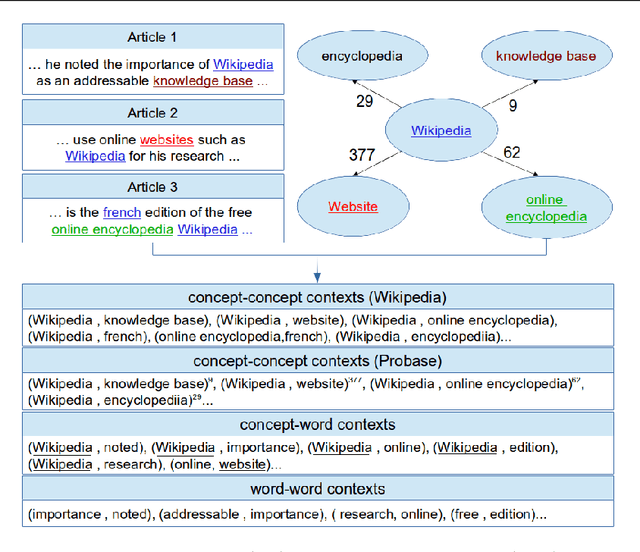
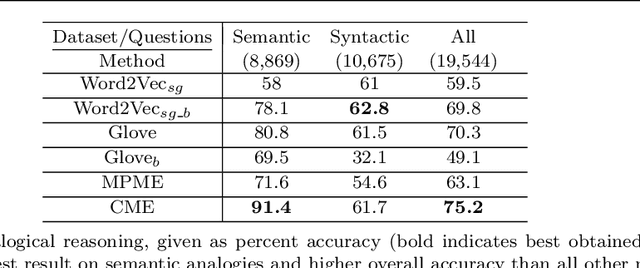
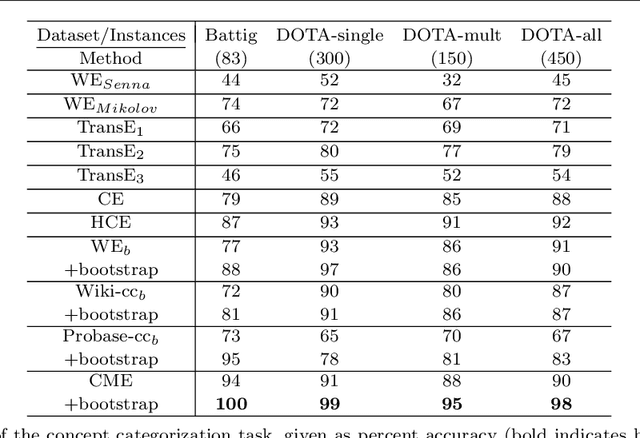

Text representations using neural word embeddings have proven effective in many NLP applications. Recent researches adapt the traditional word embedding models to learn vectors of multiword expressions (concepts/entities). However, these methods are limited to textual knowledge bases (e.g., Wikipedia). In this paper, we propose a novel and simple technique for integrating the knowledge about concepts from two large scale knowledge bases of different structure (Wikipedia and Probase) in order to learn concept representations. We adapt the efficient skip-gram model to seamlessly learn from the knowledge in Wikipedia text and Probase concept graph. We evaluate our concept embedding models on two tasks: (1) analogical reasoning, where we achieve a state-of-the-art performance of 91% on semantic analogies, (2) concept categorization, where we achieve a state-of-the-art performance on two benchmark datasets achieving categorization accuracy of 100% on one and 98% on the other. Additionally, we present a case study to evaluate our model on unsupervised argument type identification for neural semantic parsing. We demonstrate the competitive accuracy of our unsupervised method and its ability to better generalize to out of vocabulary entity mentions compared to the tedious and error prone methods which depend on gazetteers and regular expressions.
Mined Semantic Analysis: A New Concept Space Model for Semantic Representation of Textual Data
Dec 31, 2017
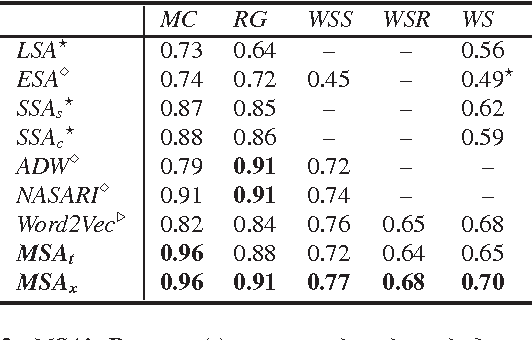

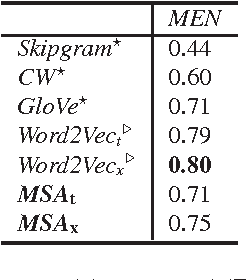
Mined Semantic Analysis (MSA) is a novel concept space model which employs unsupervised learning to generate semantic representations of text. MSA represents textual structures (terms, phrases, documents) as a Bag of Concepts (BoC) where concepts are derived from concept rich encyclopedic corpora. Traditional concept space models exploit only target corpus content to construct the concept space. MSA, alternatively, uncovers implicit relations between concepts by mining for their associations (e.g., mining Wikipedia's "See also" link graph). We evaluate MSA's performance on benchmark datasets for measuring semantic relatedness of words and sentences. Empirical results show competitive performance of MSA compared to prior state-of-the-art methods. Additionally, we introduce the first analytical study to examine statistical significance of results reported by different semantic relatedness methods. Our study shows that, the nuances of results across top performing methods could be statistically insignificant. The study positions MSA as one of state-of-the-art methods for measuring semantic relatedness, besides the inherent interpretability and simplicity of the generated semantic representation.
Solving Cold-Start Problem in Large-scale Recommendation Engines: A Deep Learning Approach
Nov 16, 2016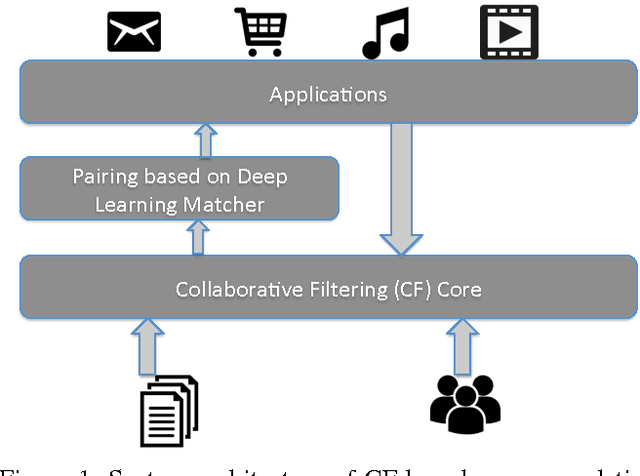
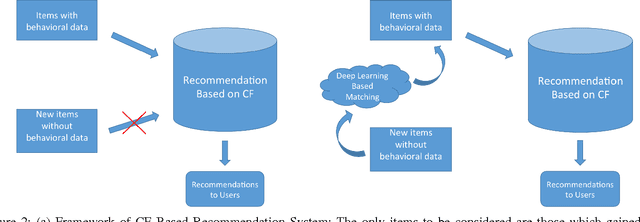
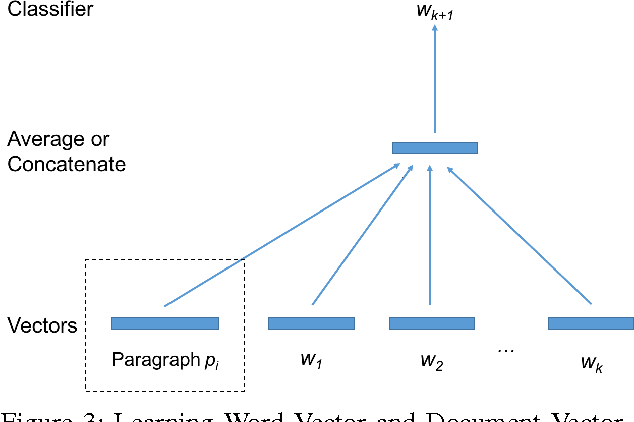
Collaborative Filtering (CF) is widely used in large-scale recommendation engines because of its efficiency, accuracy and scalability. However, in practice, the fact that recommendation engines based on CF require interactions between users and items before making recommendations, make it inappropriate for new items which haven't been exposed to the end users to interact with. This is known as the cold-start problem. In this paper we introduce a novel approach which employs deep learning to tackle this problem in any CF based recommendation engine. One of the most important features of the proposed technique is the fact that it can be applied on top of any existing CF based recommendation engine without changing the CF core. We successfully applied this technique to overcome the item cold-start problem in Careerbuilder's CF based recommendation engine. Our experiments show that the proposed technique is very efficient to resolve the cold-start problem while maintaining high accuracy of the CF recommendations.
Entity Type Recognition using an Ensemble of Distributional Semantic Models to Enhance Query Understanding
Apr 04, 2016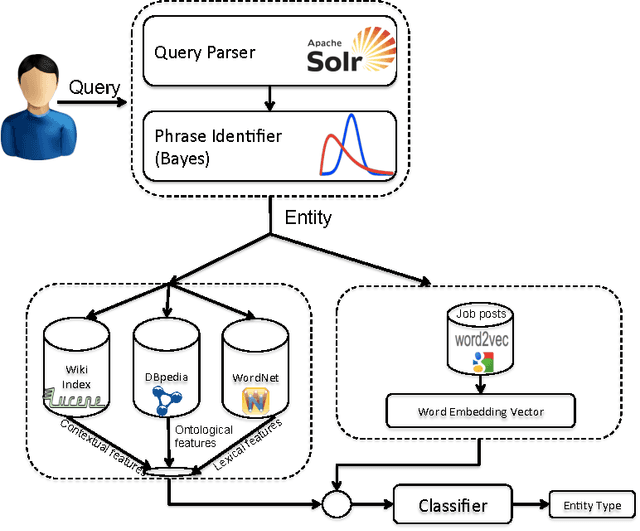
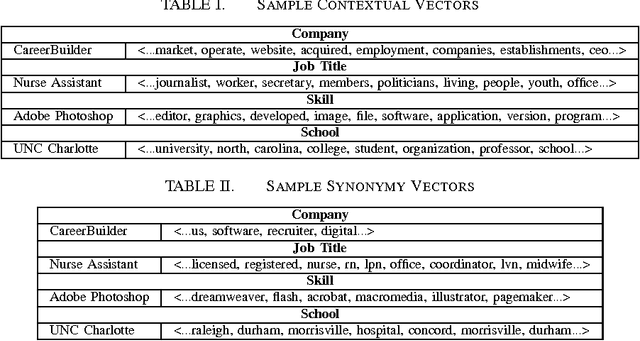
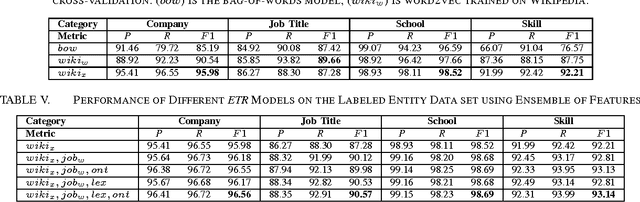
We present an ensemble approach for categorizing search query entities in the recruitment domain. Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. Our approach instead combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using word2vec. Additionally, our approach utilizes both entity linguistic properties obtained from WordNet and ontological properties extracted from DBpedia. We evaluate our approach on a data set created at CareerBuilder; the largest job board in the US. The data set contains entities extracted from millions of job seekers/recruiters search queries, job postings, and resume documents. After constructing the distributional vectors of search entities, we use supervised machine learning to infer search entity types. Empirical results show that our approach outperforms the state-of-the-art word2vec distributional semantics model trained on Wikipedia. Moreover, we achieve micro-averaged F 1 score of 97% using the proposed distributional representations ensemble.
Watsonsim: Overview of a Question Answering Engine
Dec 02, 2014The objective of the project is to design and run a system similar to Watson, designed to answer Jeopardy questions. In the course of a semester, we developed an open source question answering system using the Indri, Lucene, Bing and Google search engines, Apache UIMA, Open- and CoreNLP, and Weka among additional modules. By the end of the semester, we achieved 18% accuracy on Jeopardy questions, and work has not stopped since then.