 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-Biased Modelling of Search Click Behavior with Reinforcement Learning
May 21, 2021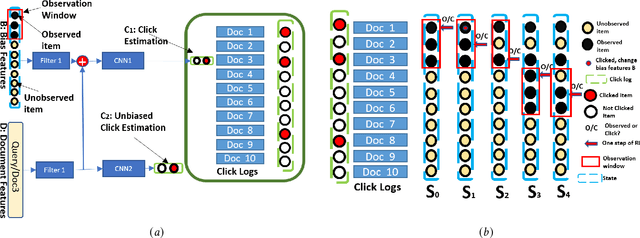

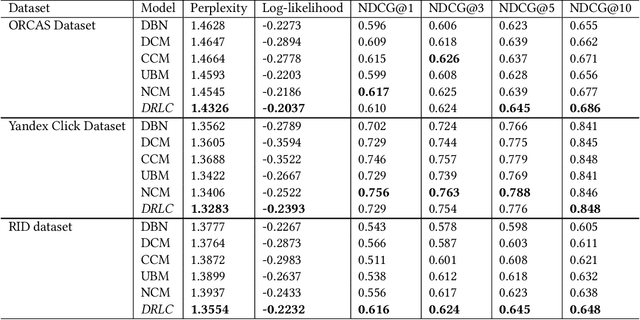
Users' clicks on Web search results are one of the key signals for evaluating and improving web search quality and have been widely used as part of current state-of-the-art Learning-To-Rank(LTR) models. With a large volume of search logs available for major search engines, effective models of searcher click behavior have emerged to evaluate and train LTR models. However, when modeling the users' click behavior, considering the bias of the behavior is imperative. In particular, when a search result is not clicked, it is not necessarily chosen as not relevant by the user, but instead could have been simply missed, especially for lower-ranked results. These kinds of biases in the click log data can be incorporated into the click models, propagating the errors to the resulting LTR ranking models or evaluation metrics. In this paper, we propose the De-biased Reinforcement Learning Click model (DRLC). The DRLC model relaxes previously made assumptions about the users' examination behavior and resulting latent states. To implement the DRLC model, convolutional neural networks are used as the value networks for reinforcement learning, trained to learn a policy to reduce bias in the click logs. To demonstrate the effectiveness of the DRLC model, we first compare performance with the previous state-of-art approaches using established click prediction metrics, including log-likelihood and perplexity. We further show that DRLC also leads to improvements in ranking performance. Our experiments demonstrate the effectiveness of the DRLC model in learning to reduce bias in click logs, leading to improved modeling performance and showing the potential for using DRLC for improving Web search quality.
Online Product Feature Recommendations with Interpretable Machine Learning
Apr 28, 2021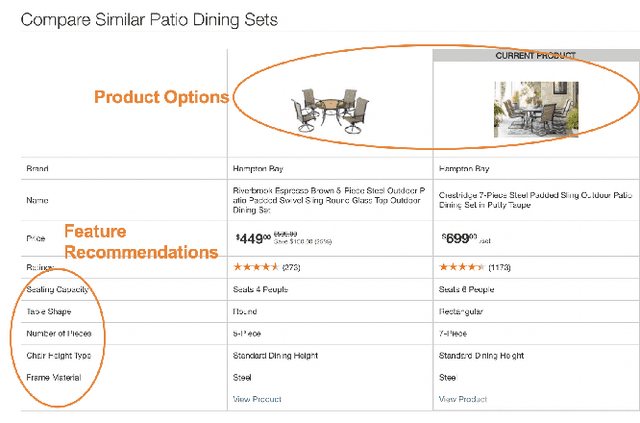
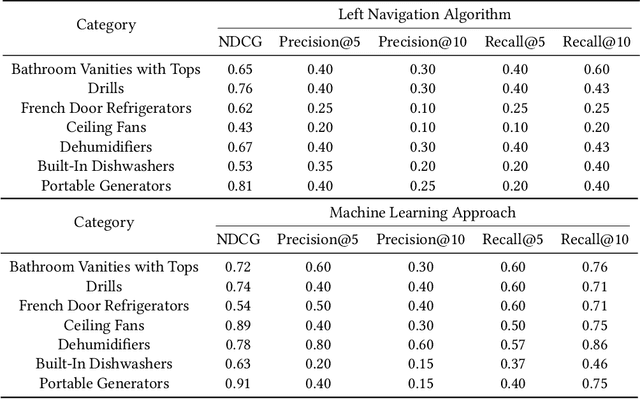
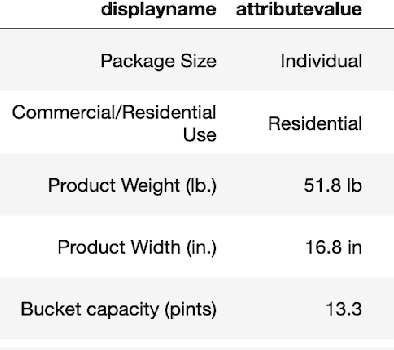

Product feature recommendations are critical for online customers to purchase the right products based on the right features. For a customer, selecting the product that has the best trade-off between price and functionality is a time-consuming step in an online shopping experience, and customers can be overwhelmed by the available choices. However, determining the set of product features that most differentiate a particular product is still an open question in online recommender systems. In this paper, we focus on using interpretable machine learning methods to tackle this problem. First, we identify this unique product feature recommendation problem from a business perspective on a major US e-commerce site. Second, we formulate the problem into a price-driven supervised learning problem to discover the product features that could best explain the price of a product in a given product category. We build machine learning models with a model-agnostic method Shapley Values to understand the importance of each feature, rank and recommend the most essential features. Third, we leverage human experts to evaluate its relevancy. The results show that our method is superior to a strong baseline method based on customer behavior and significantly boosts the coverage by 45%. Finally, our proposed method shows comparable conversion rate against the baseline in online A/B tests.
Deep Learning-based Online Alternative Product Recommendations at Scale
Apr 15, 2021
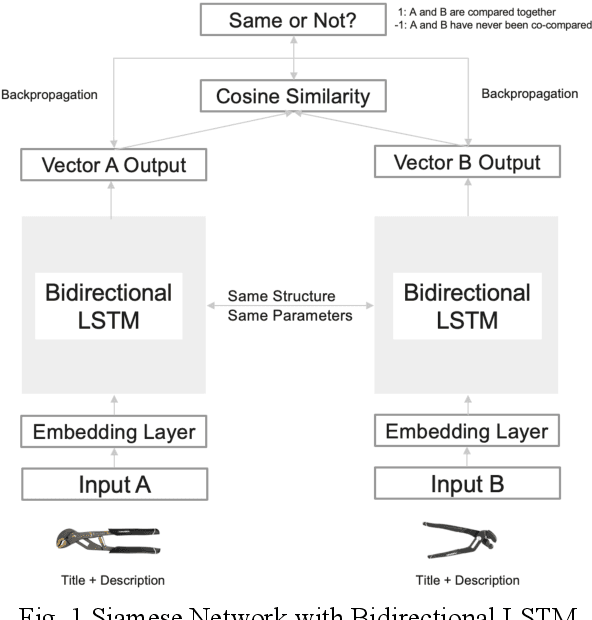

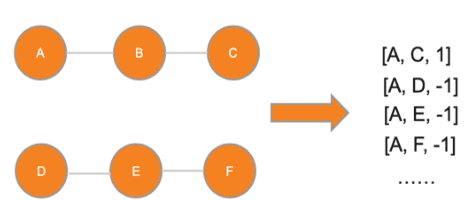
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
Interpretable Methods for Identifying Product Variants
Apr 12, 2021

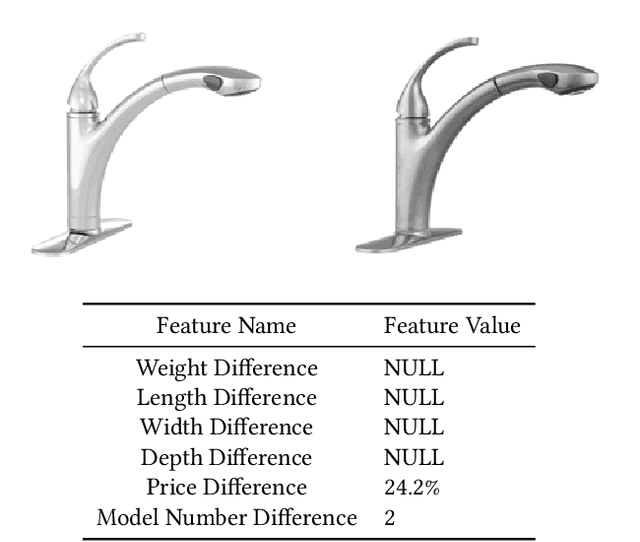

For e-commerce companies with large product selections, the organization and grouping of products in meaningful ways is important for creating great customer shopping experiences and cultivating an authoritative brand image. One important way of grouping products is to identify a family of product variants, where the variants are mostly the same with slight and yet distinct differences (e.g. color or pack size). In this paper, we introduce a novel approach to identifying product variants. It combines both constrained clustering and tailored NLP techniques (e.g. extraction of product family name from unstructured product title and identification of products with similar model numbers) to achieve superior performance compared with an existing baseline using a vanilla classification approach. In addition, we design the algorithm to meet certain business criteria, including meeting high accuracy requirements on a wide range of categories (e.g. appliances, decor, tools, and building materials, etc.) as well as prioritizing the interpretability of the model to make it accessible and understandable to all business partners.
Entity Type Recognition using an Ensemble of Distributional Semantic Models to Enhance Query Understanding
Apr 04, 2016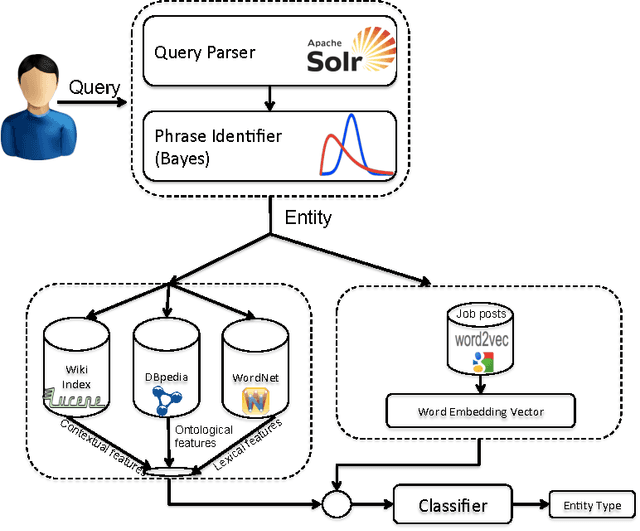
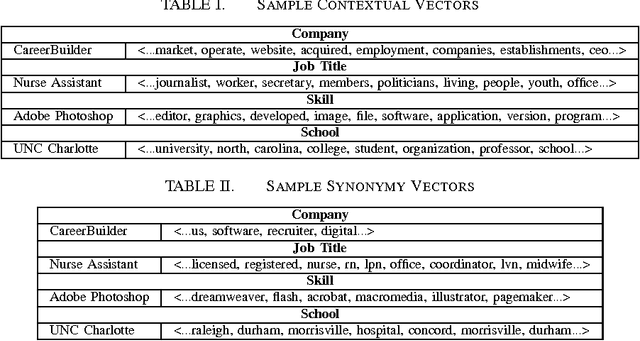
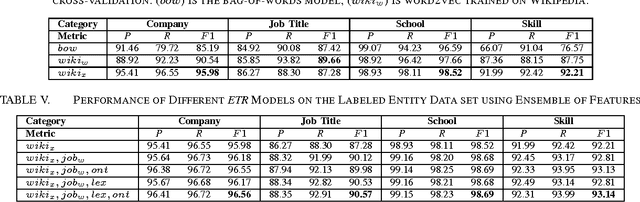
We present an ensemble approach for categorizing search query entities in the recruitment domain. Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. Our approach instead combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using word2vec. Additionally, our approach utilizes both entity linguistic properties obtained from WordNet and ontological properties extracted from DBpedia. We evaluate our approach on a data set created at CareerBuilder; the largest job board in the US. The data set contains entities extracted from millions of job seekers/recruiters search queries, job postings, and resume documents. After constructing the distributional vectors of search entities, we use supervised machine learning to infer search entity types. Empirical results show that our approach outperforms the state-of-the-art word2vec distributional semantics model trained on Wikipedia. Moreover, we achieve micro-averaged F 1 score of 97% using the proposed distributional representations ensemble.