 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Language Model for Improved E-Commerce Retrieval and Ranking: Leveraging Query Similarity and Fine-Tuning for Personalized Results
Sep 25, 2023This paper proposes a novel method to improve the accuracy of product search in e-commerce by utilizing a cluster language model. The method aims to address the limitations of the bi-encoder architecture while maintaining a minimal additional training burden. The approach involves labeling top products for each query, generating semantically similar query clusters using the K-Means clustering algorithm, and fine-tuning a global language model into cluster language models on individual clusters. The parameters of each cluster language model are fine-tuned to learn local manifolds in the feature space efficiently, capturing the nuances of various query types within each cluster. The inference is performed by assigning a new query to its respective cluster and utilizing the corresponding cluster language model for retrieval. The proposed method results in more accurate and personalized retrieval results, offering a superior alternative to the popular bi-encoder based retrieval models in semantic search.
De-Biased Modelling of Search Click Behavior with Reinforcement Learning
May 21, 2021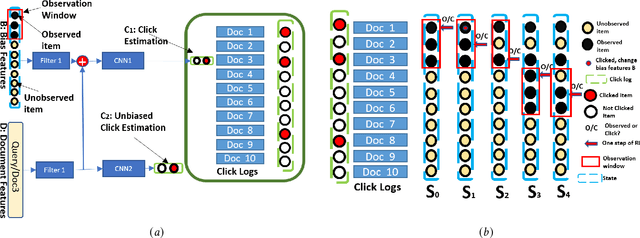

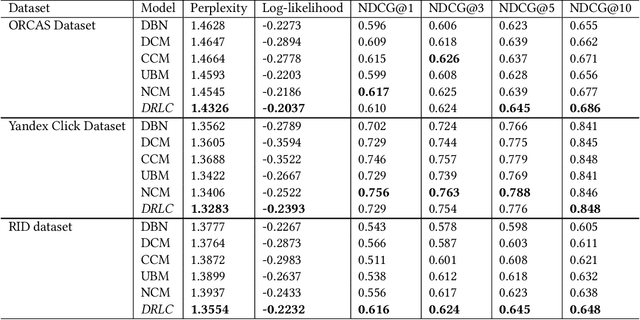
Users' clicks on Web search results are one of the key signals for evaluating and improving web search quality and have been widely used as part of current state-of-the-art Learning-To-Rank(LTR) models. With a large volume of search logs available for major search engines, effective models of searcher click behavior have emerged to evaluate and train LTR models. However, when modeling the users' click behavior, considering the bias of the behavior is imperative. In particular, when a search result is not clicked, it is not necessarily chosen as not relevant by the user, but instead could have been simply missed, especially for lower-ranked results. These kinds of biases in the click log data can be incorporated into the click models, propagating the errors to the resulting LTR ranking models or evaluation metrics. In this paper, we propose the De-biased Reinforcement Learning Click model (DRLC). The DRLC model relaxes previously made assumptions about the users' examination behavior and resulting latent states. To implement the DRLC model, convolutional neural networks are used as the value networks for reinforcement learning, trained to learn a policy to reduce bias in the click logs. To demonstrate the effectiveness of the DRLC model, we first compare performance with the previous state-of-art approaches using established click prediction metrics, including log-likelihood and perplexity. We further show that DRLC also leads to improvements in ranking performance. Our experiments demonstrate the effectiveness of the DRLC model in learning to reduce bias in click logs, leading to improved modeling performance and showing the potential for using DRLC for improving Web search quality.
APRF-Net: Attentive Pseudo-Relevance Feedback Network for Query Categorization
May 10, 2021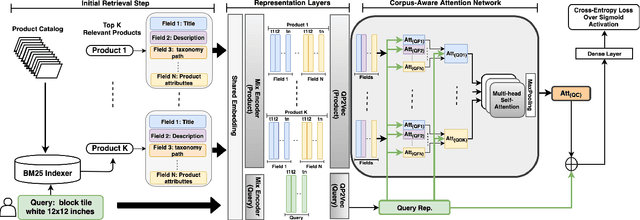
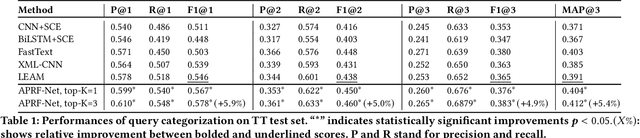
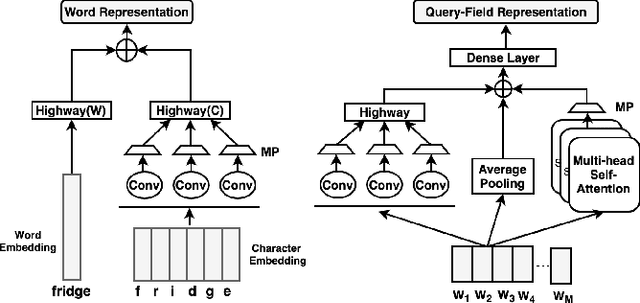
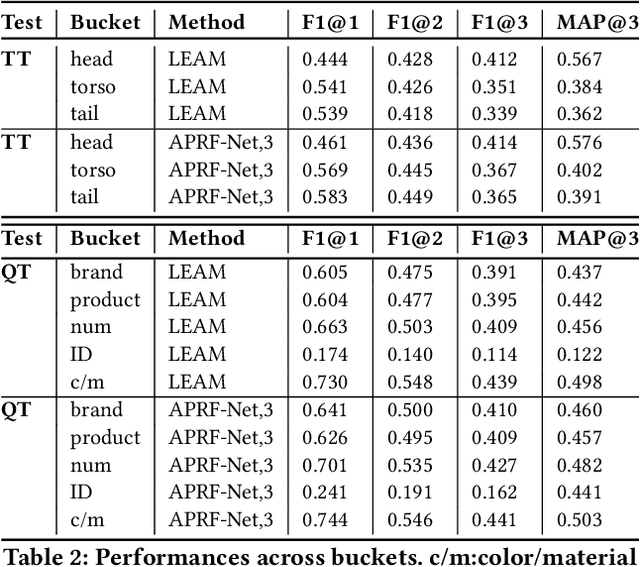
Query categorization is an essential part of query intent understanding in e-commerce search. A common query categorization task is to select the relevant fine-grained product categories in a product taxonomy. For frequent queries, rich customer behavior (e.g., click-through data) can be used to infer the relevant product categories. However, for more rare queries, which cover a large volume of search traffic, relying solely on customer behavior may not suffice due to the lack of this signal. To improve categorization of rare queries, we adapt the Pseudo-Relevance Feedback (PRF) approach to utilize the latent knowledge embedded in semantically or lexically similar product documents to enrich the representation of the more rare queries. To this end, we propose a novel deep neural model named Attentive Pseudo Relevance Feedback Network (APRF-Net) to enhance the representation of rare queries for query categorization. To demonstrate the effectiveness of our approach, we collect search queries from a large commercial search engine, and compare APRF-Net to state-of-the-art deep learning models for text classification. Our results show that the APRF-Net significantly improves query categorization by 5.9% on F1@1 score over the baselines, which increases to 8.2% improvement for the rare (tail) queries. The findings of this paper can be leveraged for further improvements in search query representation and understanding.
Online Product Feature Recommendations with Interpretable Machine Learning
Apr 28, 2021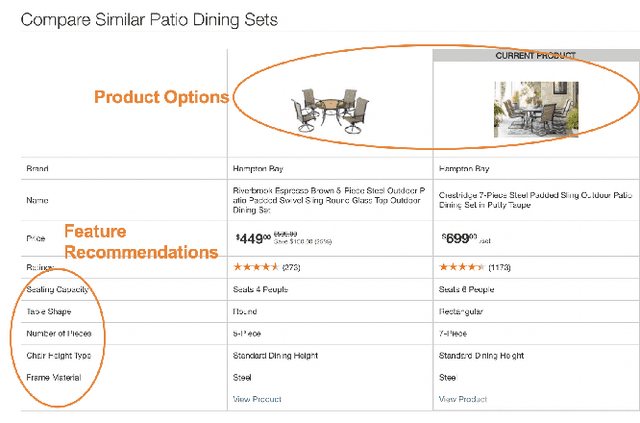
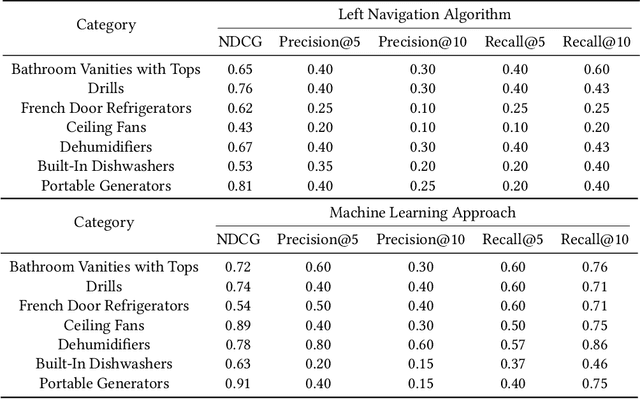
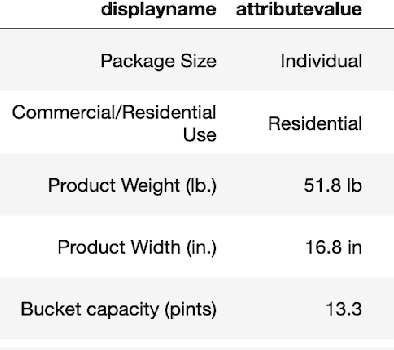

Product feature recommendations are critical for online customers to purchase the right products based on the right features. For a customer, selecting the product that has the best trade-off between price and functionality is a time-consuming step in an online shopping experience, and customers can be overwhelmed by the available choices. However, determining the set of product features that most differentiate a particular product is still an open question in online recommender systems. In this paper, we focus on using interpretable machine learning methods to tackle this problem. First, we identify this unique product feature recommendation problem from a business perspective on a major US e-commerce site. Second, we formulate the problem into a price-driven supervised learning problem to discover the product features that could best explain the price of a product in a given product category. We build machine learning models with a model-agnostic method Shapley Values to understand the importance of each feature, rank and recommend the most essential features. Third, we leverage human experts to evaluate its relevancy. The results show that our method is superior to a strong baseline method based on customer behavior and significantly boosts the coverage by 45%. Finally, our proposed method shows comparable conversion rate against the baseline in online A/B tests.