 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Language Model for Improved E-Commerce Retrieval and Ranking: Leveraging Query Similarity and Fine-Tuning for Personalized Results
Sep 25, 2023This paper proposes a novel method to improve the accuracy of product search in e-commerce by utilizing a cluster language model. The method aims to address the limitations of the bi-encoder architecture while maintaining a minimal additional training burden. The approach involves labeling top products for each query, generating semantically similar query clusters using the K-Means clustering algorithm, and fine-tuning a global language model into cluster language models on individual clusters. The parameters of each cluster language model are fine-tuned to learn local manifolds in the feature space efficiently, capturing the nuances of various query types within each cluster. The inference is performed by assigning a new query to its respective cluster and utilizing the corresponding cluster language model for retrieval. The proposed method results in more accurate and personalized retrieval results, offering a superior alternative to the popular bi-encoder based retrieval models in semantic search.
DCSVM: Fast Multi-class Classification using Support Vector Machines
Oct 23, 2018

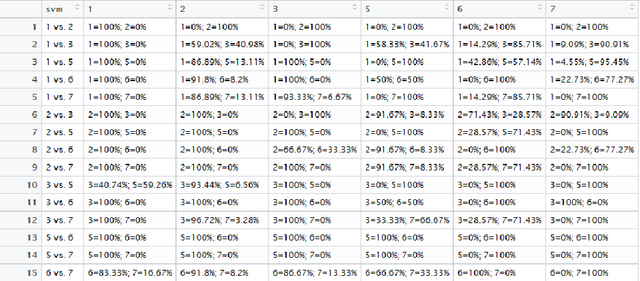

We present DCSVM, an efficient algorithm for multi-class classification using Support Vector Machines. DCSVM is a divide and conquer algorithm which relies on data sparsity in high dimensional space and performs a smart partitioning of the whole training data set into disjoint subsets that are easily separable. A single prediction performed between two partitions eliminates at once one or more classes in one partition, leaving only a reduced number of candidate classes for subsequent steps. The algorithm continues recursively, reducing the number of classes at each step, until a final binary decision is made between the last two classes left in the competition. In the best case scenario, our algorithm makes a final decision between $k$ classes in $O(\log k)$ decision steps and in the worst case scenario DCSVM makes a final decision in $k-1$ steps, which is not worse than the existent techniques.