 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Subject EEG Emotion Recognition Based on Temporal Asynchronous Alignment Contrastive Learning
May 21, 2026With the advancement of science and technology, the importance of emotion research has become increasingly evident. Electroencephalography (EEG)-based emotion recognition has emerged as an active research area in recent years, owing to its objectivity and high temporal resolution. However, most existing methods focus on optimizing encoder structures to enhance feature extraction capabilities, while paying relatively little attention to similarity calculation strategies, particularly overlooking the potential temporal misalignment of responses among different subjects. To address these shortcomings, this paper draws inspiration from the late interaction mechanism of ColBERT in natural language processing (NLP) and proposes a Temporal Asynchronous Alignment-based Contrastive Learning (TA2CL) framework. This method transforms the traditional global "hard alignment" similarity calculation approach into a fine-grained local matching mechanism, enabling the model to adaptively search for and align "locally highly correlated" segments between two EEG signals, thereby effectively mitigating the effects of inter-subject differences and temporal delays. Experimental results demonstrate that the proposed method achieves strong performance across multiple public datasets. Specifically, on the FACED dataset, it achieves an accuracy of 64.5% for the nine-class classification task and 79.5% for the binary classification task, while on the SEED and SEED-V datasets, it achieves accuracies of 86.4% and 70.1%, respectively, validating the method's effectiveness and generalization capability.
Self-Monitoring Benefits from Structural Integration: Lessons from Metacognition in Continuous-Time Multi-Timescale Agents
Apr 13, 2026Self-monitoring capabilities -- metacognition, self-prediction, and subjective duration -- are often proposed as useful additions to reinforcement learning agents. But do they actually help? We investigate this question in a continuous-time multi-timescale agent operating in predator-prey survival environments of varying complexity, including a 2D partially observable variant. We first show that three self-monitoring modules, implemented as auxiliary-loss add-ons to a multi-timescale cortical hierarchy, provide no statistically significant benefit across 20 random seeds, 1D and 2D predator-prey environments with standard and non-stationary variants, and training horizons up to 50,000 steps. Diagnosing the failure, we find the modules collapse to near-constant outputs (confidence std < 0.006, attention allocation std < 0.011) and the subjective duration mechanism shifts the discount factor by less than 0.03%. Policy sensitivity analysis confirms the agent's decisions are unaffected by module outputs in this design. We then show that structurally integrating the module outputs -- using confidence to gate exploration, surprise to trigger workspace broadcasts, and self-model predictions as policy input -- produces a medium-large improvement over the add-on approach (Cohen's d = 0.62, p = 0.06, paired) in a non-stationary environment. Component-wise ablations reveal that the TSM-to-policy pathway contributes most of this gain. However, structural integration does not significantly outperform a baseline with no self-monitoring (d = 0.15, p = 0.67), and a parameter-matched control without modules performs comparably, so the benefit may lie in recovering from the trend-level harm of ignored modules rather than in self-monitoring content. The architectural implication is that self-monitoring should sit on the decision pathway, not beside it.
General365: Benchmarking General Reasoning in Large Language Models Across Diverse and Challenging Tasks
Apr 13, 2026Contemporary large language models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in specialized domains like mathematics and physics. However, their ability to generalize these reasoning skills to more general and broader contexts--often termed general reasoning--remains under-explored. Unlike domain-specific reasoning, general reasoning relies less on expert knowledge but still presents formidable reasoning challenges, such as complex constraints, nested logical branches, and semantic interference. To address this gap, we introduce General365, a benchmark specifically designed to assess general reasoning in LLMs. By restricting background knowledge to a K-12 level, General365 explicitly decouples reasoning from specialized expertise. The benchmark comprises 365 seed problems and 1,095 variant problems across eight categories, ensuring both high difficulty and diversity. Evaluations across 26 leading LLMs reveal that even the top-performing model achieves only 62.8% accuracy, in stark contrast to the near-perfect performances of LLMs in math and physics benchmarks. These results suggest that the reasoning abilities of current LLMs are heavily domain-dependent, leaving significant room for improvement in broader applications. We envision General365 as a catalyst for advancing LLM reasoning beyond domain-specific tasks toward robust, general-purpose real-world scenarios. Code, Dataset, and Leaderboard: https://general365.github.io
VibeGuard: A Security Gate Framework for AI-Generated Code
Apr 01, 2026"Vibe coding," in which developers delegate code generation to AI assistants and accept the output with little manual review, has gained rapid adoption in production settings. On March 31, 2026, Anthropic's Claude Code CLI shipped a 59.8 MB source map file in its npm package, exposing roughly 512,000 lines of proprietary TypeScript. The tool had itself been largely vibe-coded, and the leak traced to a misconfigured packaging rule rather than a logic bug. Existing static-analysis and secret-scanning tools did not cover this failure mode, pointing to a gap between the vulnerabilities AI tends to introduce and the vulnerabilities current tooling is built to find. We present VibeGuard, a pre-publish security gate that targets five such blind spots: artifact hygiene, packaging-configuration drift, source-map exposure, hardcoded secrets, and supply-chain risk. In controlled experiments on eight synthetic projects (seven vulnerable, one clean control), VibeGuard achieved 100% recall, 89.47% precision (F1 = 94.44%), and correct pass/fail gate decisions on all eight projects across three policy levels. We discuss how these results inform a defense-in-depth workflow for teams that rely on AI code generation.
Learning to Forget: Sleep-Inspired Memory Consolidation for Resolving Proactive Interference in Large Language Models
Mar 15, 2026Large language models (LLMs) suffer from proactive interference (PI): outdated information in the context window disrupts retrieval of current values. This interference degrades retrieval accuracy log-linearly as stale associations accumulate, a bottleneck that persists regardless of context length and resists prompt-engineering mitigations. Biological brains resolve an analogous challenge through sleep-dependent memory consolidation: synaptic downscaling, selective replay, and targeted forgetting. We propose SleepGate, a biologically inspired framework that augments transformer-based LLMs with a learned sleep cycle over the key-value (KV) cache. SleepGate introduces three mechanisms: (1) a conflict-aware temporal tagger detecting when new entries supersede old ones; (2) a lightweight forgetting gate trained to selectively evict or compress stale cache entries; and (3) a consolidation module that merges surviving entries into compact summaries. These components activate periodically during inference in sleep micro-cycles, governed by an adaptive entropy-based trigger. We formalize a dual-phase training objective jointly optimizing language modeling during the wake phase and post-consolidation retrieval during the sleep phase. Theoretical analysis shows SleepGate reduces the interference horizon from O(n) to O(log n). In experiments with a small-scale transformer (4 layers, 793K parameters), SleepGate achieves 99.5% retrieval accuracy at PI depth 5 and 97.0% at depth 10, while all five baselines -- full KV cache, sliding window, H2O, StreamingLLM, and decay-only ablation -- remain below 18%. Our framework offers an architecture-level solution that prompt engineering cannot address.
Artificial Intelligence-Enabled Holistic Design of Catalysts Tailored for Semiconducting Carbon Nanotube Growth
Dec 18, 2025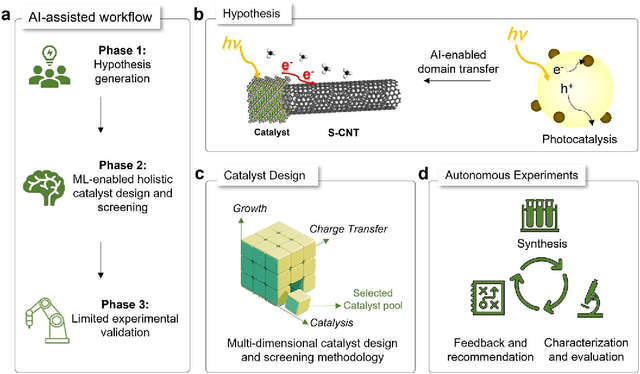
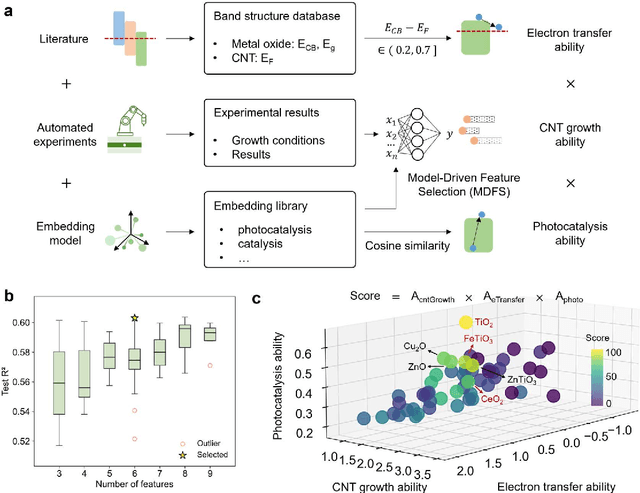
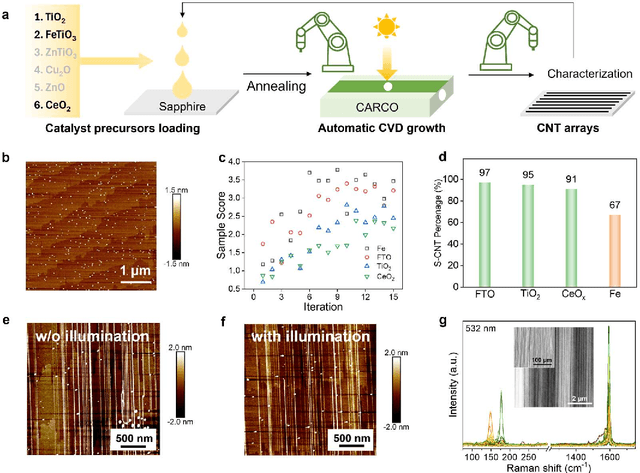
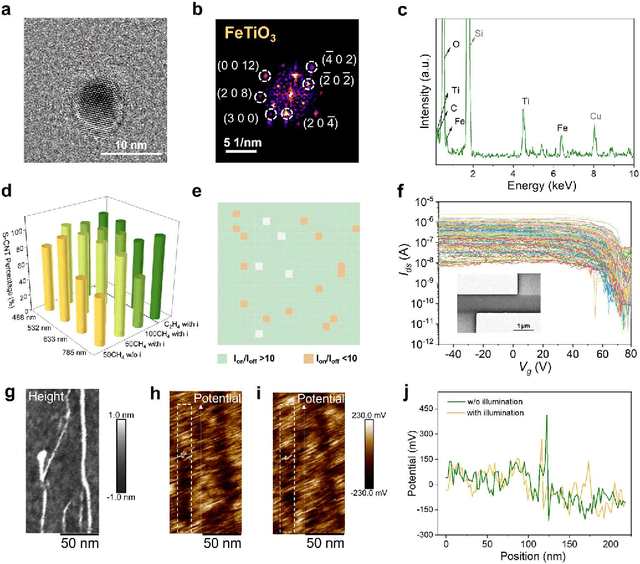
Catalyst design is crucial for materials synthesis, especially for complex reaction networks. Strategies like collaborative catalytic systems and multifunctional catalysts are effective but face challenges at the nanoscale. Carbon nanotube synthesis contains complicated nanoscale catalytic reactions, thus achieving high-density, high-quality semiconducting CNTs demands innovative catalyst design. In this work, we present a holistic framework integrating machine learning into traditional catalyst design for semiconducting CNT synthesis. It combines knowledge-based insights with data-driven techniques. Three key components, including open-access electronic structure databases for precise physicochemical descriptors, pre-trained natural language processing-based embedding model for higher-level abstractions, and physical - driven predictive models based on experiment data, are utilized. Through this framework, a new method for selective semiconducting CNT synthesis via catalyst - mediated electron injection, tuned by light during growth, is proposed. 54 candidate catalysts are screened, and three with high potential are identified. High-throughput experiments validate the predictions, with semiconducting selectivity exceeding 91% and the FeTiO3 catalyst reaching 98.6%. This approach not only addresses semiconducting CNT synthesis but also offers a generalizable methodology for global catalyst design and nanomaterials synthesis, advancing materials science in precise control.
TWLR: Text-Guided Weakly-Supervised Lesion Localization and Severity Regression for Explainable Diabetic Retinopathy Grading
Dec 15, 2025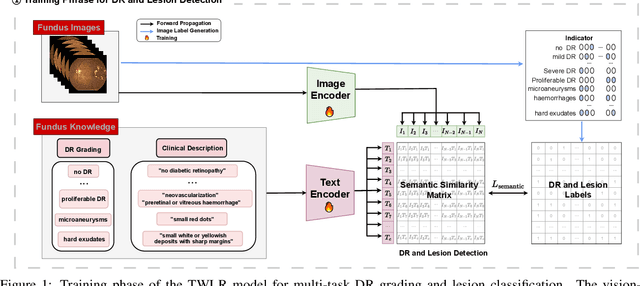

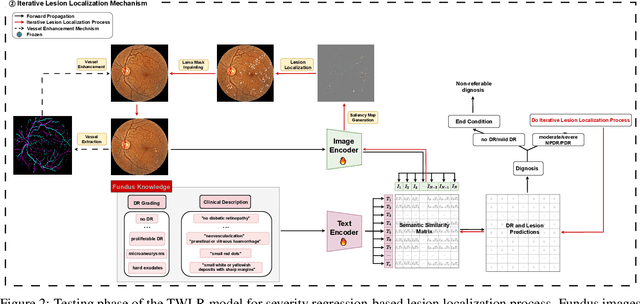
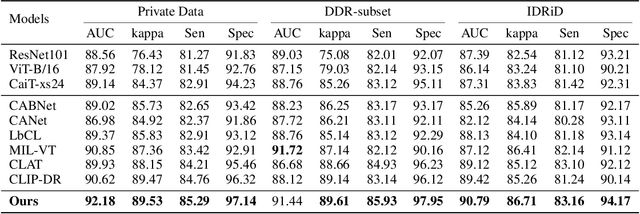
Accurate medical image analysis can greatly assist clinical diagnosis, but its effectiveness relies on high-quality expert annotations Obtaining pixel-level labels for medical images, particularly fundus images, remains costly and time-consuming. Meanwhile, despite the success of deep learning in medical imaging, the lack of interpretability limits its clinical adoption. To address these challenges, we propose TWLR, a two-stage framework for interpretable diabetic retinopathy (DR) assessment. In the first stage, a vision-language model integrates domain-specific ophthalmological knowledge into text embeddings to jointly perform DR grading and lesion classification, effectively linking semantic medical concepts with visual features. The second stage introduces an iterative severity regression framework based on weakly-supervised semantic segmentation. Lesion saliency maps generated through iterative refinement direct a progressive inpainting mechanism that systematically eliminates pathological features, effectively downgrading disease severity toward healthier fundus appearances. Critically, this severity regression approach achieves dual benefits: accurate lesion localization without pixel-level supervision and providing an interpretable visualization of disease-to-healthy transformations. Experimental results on the FGADR, DDR, and a private dataset demonstrate that TWLR achieves competitive performance in both DR classification and lesion segmentation, offering a more explainable and annotation-efficient solution for automated retinal image analysis.
Inferring Latent Market Forces: Evaluating LLM Detection of Gamma Exposure Patterns via Obfuscation Testing
Dec 08, 2025We introduce obfuscation testing, a novel methodology for validating whether large language models detect structural market patterns through causal reasoning rather than temporal association. Testing three dealer hedging constraint patterns (gamma positioning, stock pinning, 0DTE hedging) on 242 trading days (95.6% coverage) of S&P 500 options data, we find LLMs achieve 71.5% detection rate using unbiased prompts that provide only raw gamma exposure values without regime labels or temporal context. The WHO-WHOM-WHAT causal framework forces models to identify the economic actors (dealers), affected parties (directional traders), and structural mechanisms (forced hedging) underlying observed market dynamics. Critically, detection accuracy (91.2%) remains stable even as economic profitability varies quarterly, demonstrating that models identify structural constraints rather than profitable patterns. When prompted with regime labels, detection increases to 100%, but the 71.5% unbiased rate validates genuine pattern recognition. Our findings suggest LLMs possess emergent capabilities for detecting complex financial mechanisms through pure structural reasoning, with implications for systematic strategy development, risk management, and our understanding of how transformer architectures process financial market dynamics.
Multi-view Normal and Distance Guidance Gaussian Splatting for Surface Reconstruction
Aug 13, 20253D Gaussian Splatting (3DGS) achieves remarkable results in the field of surface reconstruction. However, when Gaussian normal vectors are aligned within the single-view projection plane, while the geometry appears reasonable in the current view, biases may emerge upon switching to nearby views. To address the distance and global matching challenges in multi-view scenes, we design multi-view normal and distance-guided Gaussian splatting. This method achieves geometric depth unification and high-accuracy reconstruction by constraining nearby depth maps and aligning 3D normals. Specifically, for the reconstruction of small indoor and outdoor scenes, we propose a multi-view distance reprojection regularization module that achieves multi-view Gaussian alignment by computing the distance loss between two nearby views and the same Gaussian surface. Additionally, we develop a multi-view normal enhancement module, which ensures consistency across views by matching the normals of pixel points in nearby views and calculating the loss. Extensive experimental results demonstrate that our method outperforms the baseline in both quantitative and qualitative evaluations, significantly enhancing the surface reconstruction capability of 3DGS. Our code will be made publicly available at (https://github.com/Bistu3DV/MND-GS/).
From Glue-Code to Protocols: A Critical Analysis of A2A and MCP Integration for Scalable Agent Systems
May 06, 2025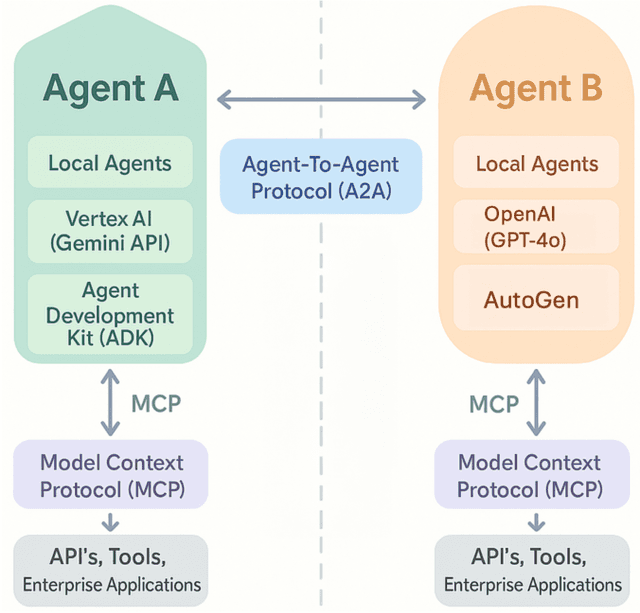

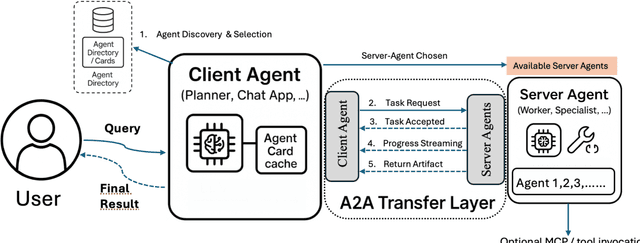
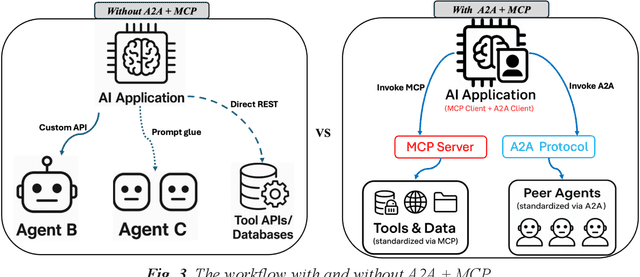
Artificial intelligence is rapidly evolving towards multi-agent systems where numerous AI agents collaborate and interact with external tools. Two key open standards, Google's Agent to Agent (A2A) protocol for inter-agent communication and Anthropic's Model Context Protocol (MCP) for standardized tool access, promise to overcome the limitations of fragmented, custom integration approaches. While their potential synergy is significant, this paper argues that effectively integrating A2A and MCP presents unique, emergent challenges at their intersection, particularly concerning semantic interoperability between agent tasks and tool capabilities, the compounded security risks arising from combined discovery and execution, and the practical governance required for the envisioned "Agent Economy". This work provides a critical analysis, moving beyond a survey to evaluate the practical implications and inherent difficulties of combining these horizontal and vertical integration standards. We examine the benefits (e.g., specialization, scalability) while critically assessing their dependencies and trade-offs in an integrated context. We identify key challenges increased by the integration, including novel security vulnerabilities, privacy complexities, debugging difficulties across protocols, and the need for robust semantic negotiation mechanisms. In summary, A2A+MCP offers a vital architectural foundation, but fully realizing its potential requires substantial advancements to manage the complexities of their combined operation.