 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText classification in shipping industry using unsupervised models and Transformer based supervised models
Paper and Code
Dec 21, 2022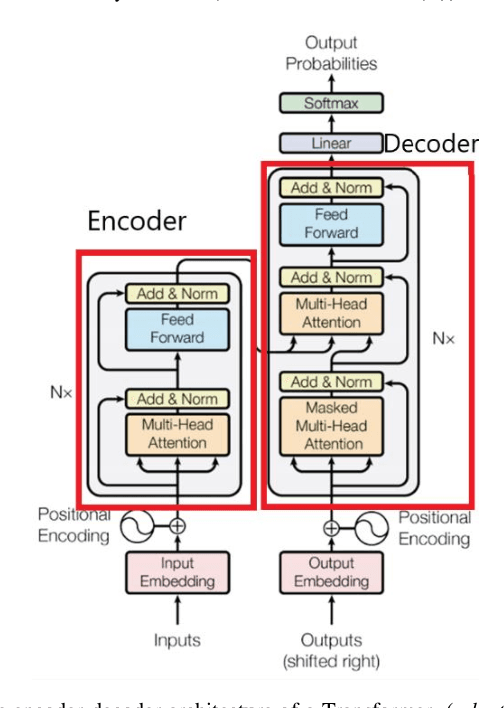
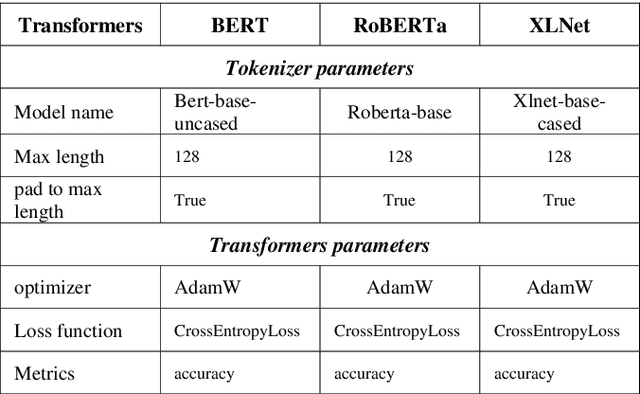
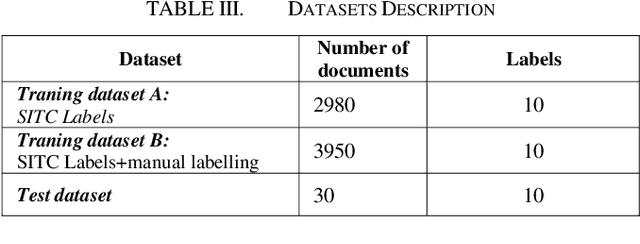
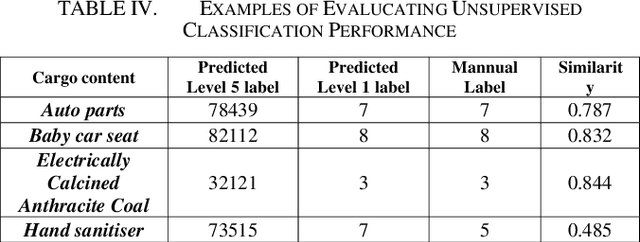
Obtaining labelled data in a particular context could be expensive and time consuming. Although different algorithms, including unsupervised learning, semi-supervised learning, self-learning have been adopted, the performance of text classification varies with context. Given the lack of labelled dataset, we proposed a novel and simple unsupervised text classification model to classify cargo content in international shipping industry using the Standard International Trade Classification (SITC) codes. Our method stems from representing words using pretrained Glove Word Embeddings and finding the most likely label using Cosine Similarity. To compare unsupervised text classification model with supervised classification, we also applied several Transformer models to classify cargo content. Due to lack of training data, the SITC numerical codes and the corresponding textual descriptions were used as training data. A small number of manually labelled cargo content data was used to evaluate the classification performances of the unsupervised classification and the Transformer based supervised classification. The comparison reveals that unsupervised classification significantly outperforms Transformer based supervised classification even after increasing the size of the training dataset by 30%. Lacking training data is a key bottleneck that prohibits deep learning models (such as Transformers) from successful practical applications. Unsupervised classification can provide an alternative efficient and effective method to classify text when there is scarce training data.