 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEricson: An Interactive Open-Domain Conversational Search Agent
Apr 05, 2023


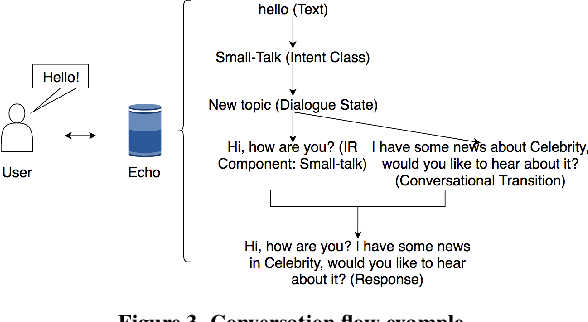
Open-domain conversational search (ODCS) aims to provide valuable, up-to-date information, while maintaining natural conversations to help users refine and ultimately answer information needs. However, creating an effective and robust ODCS agent is challenging. In this paper, we present a fully functional ODCS system, Ericson, which includes state-of-the-art question answering and information retrieval components, as well as intent inference and dialogue management models for proactive question refinement and recommendations. Our system was stress-tested in the Amazon Alexa Prize, by engaging in live conversations with thousands of Alexa users, thus providing empirical basis for the analysis of the ODCS system in real settings. Our interaction data analysis revealed that accurate intent classification, encouraging user engagement, and careful proactive recommendations contribute most to the users satisfaction. Our study further identifies limitations of the existing search techniques, and can serve as a building block for the next generation of ODCS agents.
PREME: Preference-based Meeting Exploration through an Interactive Questionnaire
May 05, 2022

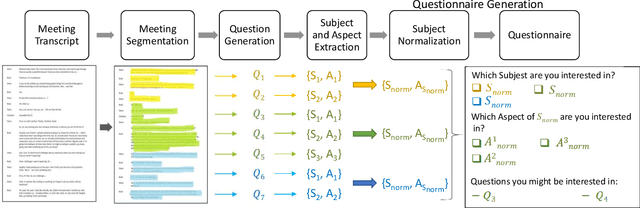

The recent increase in the volume of online meetings necessitates automated tools for managing and organizing the material, especially when an attendee has missed the discussion and needs assistance in quickly exploring it. In this work, we propose a novel end-to-end framework for generating interactive questionnaires for preference-based meeting exploration. As a result, users are supplied with a list of suggested questions reflecting their preferences. Since the task is new, we introduce an automatic evaluation strategy. Namely, it measures how much the generated questions via questionnaire are answerable to ensure factual correctness and covers the source meeting for the depth of possible exploration.
Supporting Complex Information-Seeking Tasks with Implicit Constraints
May 02, 2022
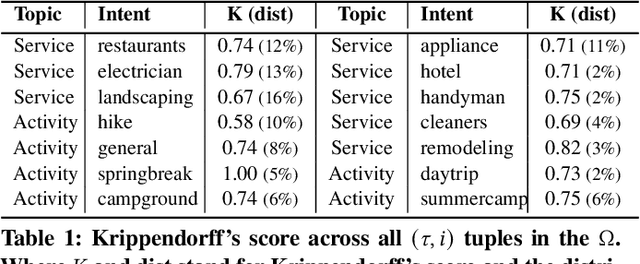
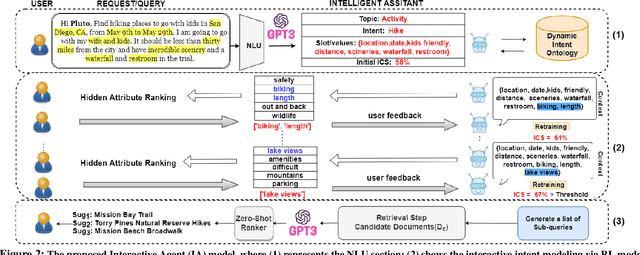
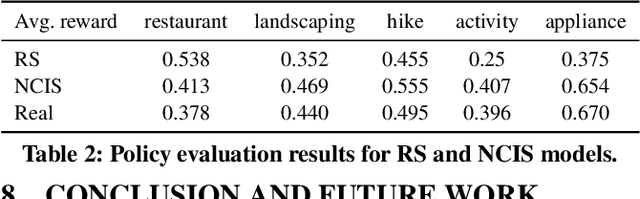
Current interactive systems with natural language interface lack an ability to understand a complex information-seeking request which expresses several implicit constraints at once, and there is no prior information about user preferences, e.g., "find hiking trails around San Francisco which are accessible with toddlers and have beautiful scenery in summer", where output is a list of possible suggestions for users to start their exploration. In such scenarios, the user requests can be issued at once in the form of a complex and long query, unlike conversational and exploratory search models that require short utterances or queries where they often require to be fed into the system step by step. This advancement provides the final user more flexibility and precision in expressing their intent through the search process. Such systems are inherently helpful for day-today user tasks requiring planning that are usually time-consuming, sometimes tricky, and cognitively taxing. We have designed and deployed a platform to collect the data from approaching such complex interactive systems. In this paper, we propose an Interactive Agent (IA) that allows intricately refined user requests by making it complete, which should lead to better retrieval. To demonstrate the performance of the proposed modeling paradigm, we have adopted various pre-retrieval metrics that capture the extent to which guided interactions with our system yield better retrieval results. Through extensive experimentation, we demonstrated that our method significantly outperforms several robust baselines
APRF-Net: Attentive Pseudo-Relevance Feedback Network for Query Categorization
May 10, 2021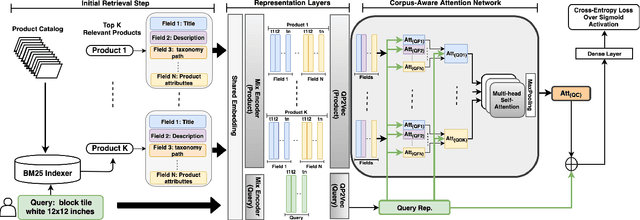
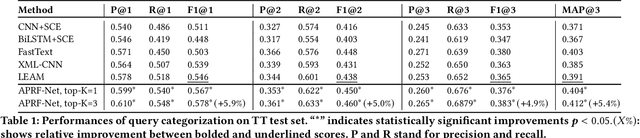
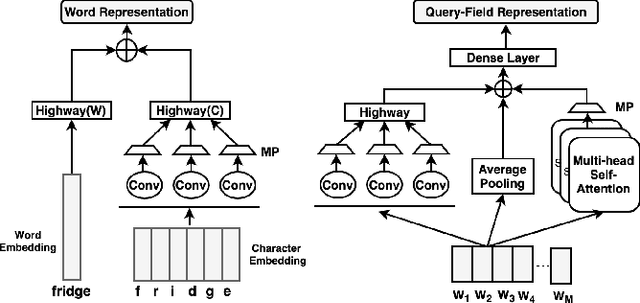
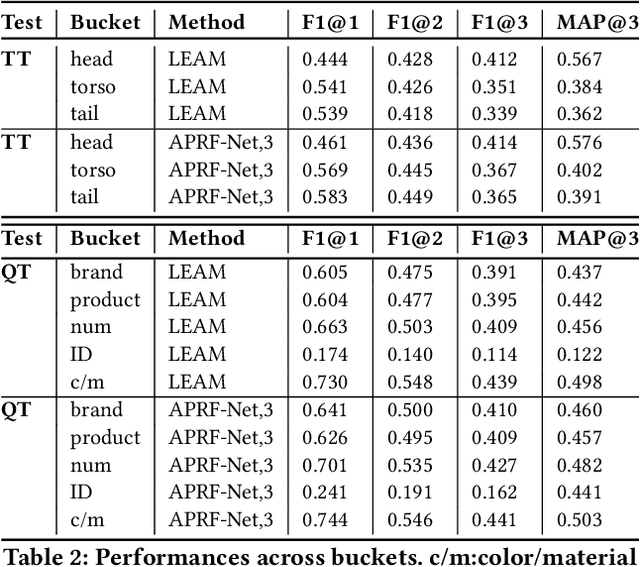
Query categorization is an essential part of query intent understanding in e-commerce search. A common query categorization task is to select the relevant fine-grained product categories in a product taxonomy. For frequent queries, rich customer behavior (e.g., click-through data) can be used to infer the relevant product categories. However, for more rare queries, which cover a large volume of search traffic, relying solely on customer behavior may not suffice due to the lack of this signal. To improve categorization of rare queries, we adapt the Pseudo-Relevance Feedback (PRF) approach to utilize the latent knowledge embedded in semantically or lexically similar product documents to enrich the representation of the more rare queries. To this end, we propose a novel deep neural model named Attentive Pseudo Relevance Feedback Network (APRF-Net) to enhance the representation of rare queries for query categorization. To demonstrate the effectiveness of our approach, we collect search queries from a large commercial search engine, and compare APRF-Net to state-of-the-art deep learning models for text classification. Our results show that the APRF-Net significantly improves query categorization by 5.9% on F1@1 score over the baselines, which increases to 8.2% improvement for the rare (tail) queries. The findings of this paper can be leveraged for further improvements in search query representation and understanding.
DeepCAT: Deep Category Representation for Query Understanding in E-commerce Search
May 10, 2021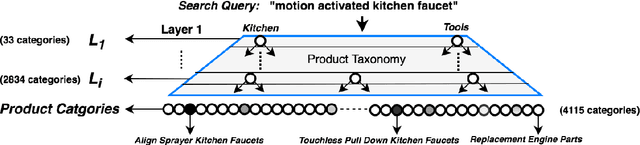
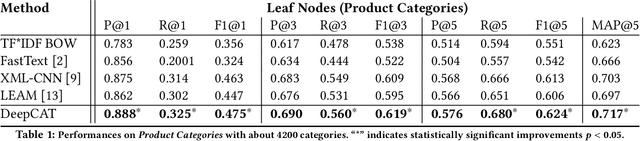
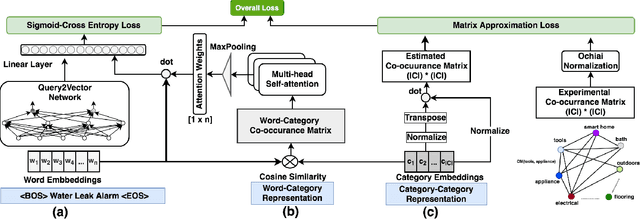
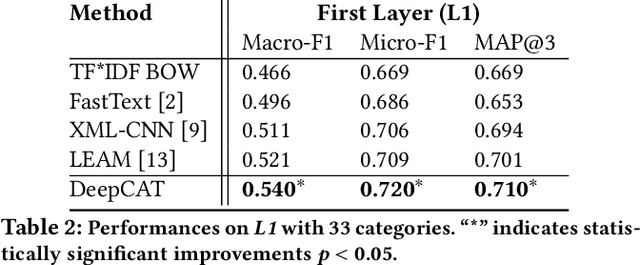
Mapping a search query to a set of relevant categories in the product taxonomy is a significant challenge in e-commerce search for two reasons: 1) Training data exhibits severe class imbalance problem due to biased click behavior, and 2) queries with little customer feedback (e.g., tail queries) are not well-represented in the training set, and cause difficulties for query understanding. To address these problems, we propose a deep learning model, DeepCAT, which learns joint word-category representations to enhance the query understanding process. We believe learning category interactions helps to improve the performance of category mapping on minority classes, tail and torso queries. DeepCAT contains a novel word-category representation model that trains the category representations based on word-category co-occurrences in the training set. The category representation is then leveraged to introduce a new loss function to estimate the category-category co-occurrences for refining joint word-category embeddings. To demonstrate our model's effectiveness on minority categories and tail queries, we conduct two sets of experiments. The results show that DeepCAT reaches a 10% improvement on minority classes and a 7.1% improvement on tail queries over a state-of-the-art label embedding model. Our findings suggest a promising direction for improving e-commerce search by semantic modeling of taxonomy hierarchies.
CRAB: Class Representation Attentive BERT for Hate Speech Identification in Social Media
Oct 25, 2020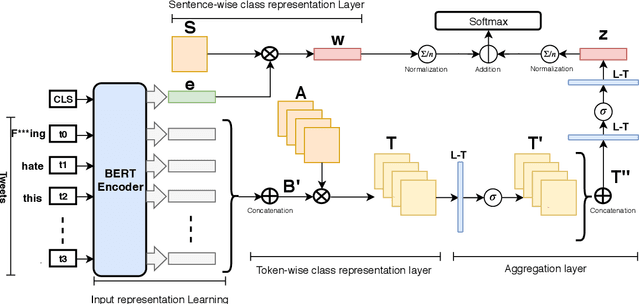
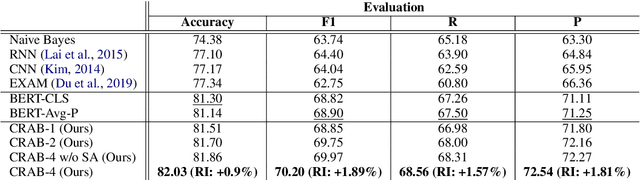
In recent years, social media platforms have hosted an explosion of hate speech and objectionable content. The urgent need for effective automatic hate speech detection models have drawn remarkable investment from companies and researchers. Social media posts are generally short and their semantics could drastically be altered by even a single token. Thus, it is crucial for this task to learn context-aware input representations, and consider relevancy scores between input embeddings and class representations as an additional signal. To accommodate these needs, this paper introduces CRAB (Class Representation Attentive BERT), a neural model for detecting hate speech in social media. The model benefits from two semantic representations: (i) trainable token-wise and sentence-wise class representations, and (ii) contextualized input embeddings from state-of-the-art BERT encoder. To investigate effectiveness of CRAB, we train our model on Twitter data and compare it against strong baselines. Our results show that CRAB achieves 1.89% relative improved Macro-averaged F1 over state-of-the-art baseline. The results of this research open an opportunity for the future research on automated abusive behavior detection in social media
Emora: An Inquisitive Social Chatbot Who Cares For You
Sep 10, 2020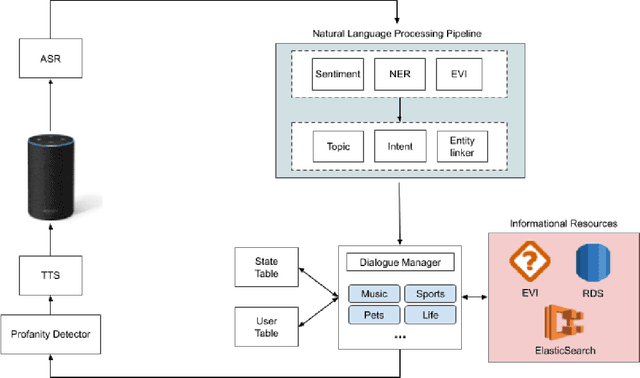
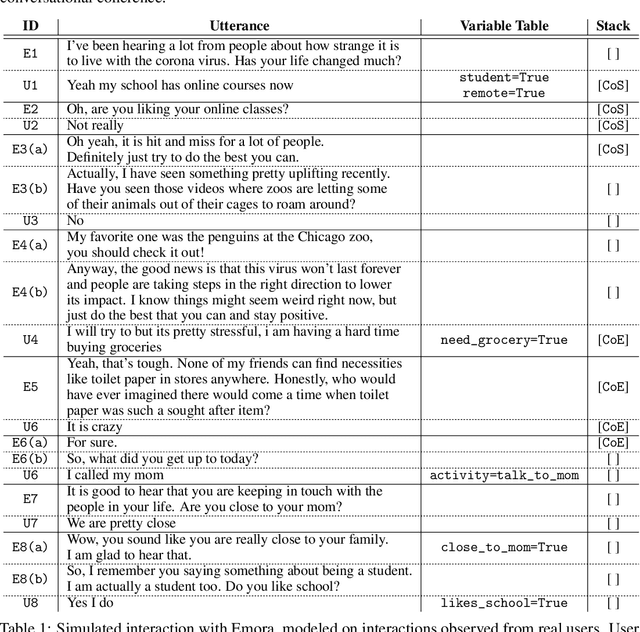
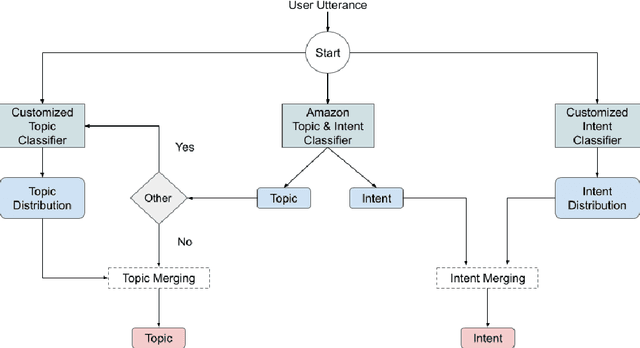
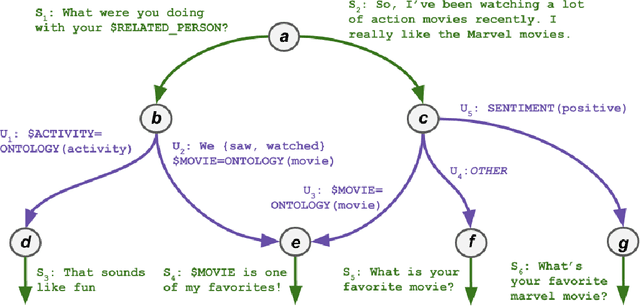
Inspired by studies on the overwhelming presence of experience-sharing in human-human conversations, Emora, the social chatbot developed by Emory University, aims to bring such experience-focused interaction to the current field of conversational AI. The traditional approach of information-sharing topic handlers is balanced with a focus on opinion-oriented exchanges that Emora delivers, and new conversational abilities are developed that support dialogues that consist of a collaborative understanding and learning process of the partner's life experiences. We present a curated dialogue system that leverages highly expressive natural language templates, powerful intent classification, and ontology resources to provide an engaging and interesting conversational experience to every user.
Offline and Online Satisfaction Prediction in Open-Domain Conversational Systems
Jun 02, 2020
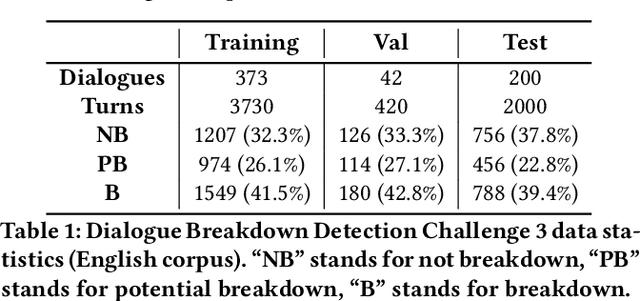
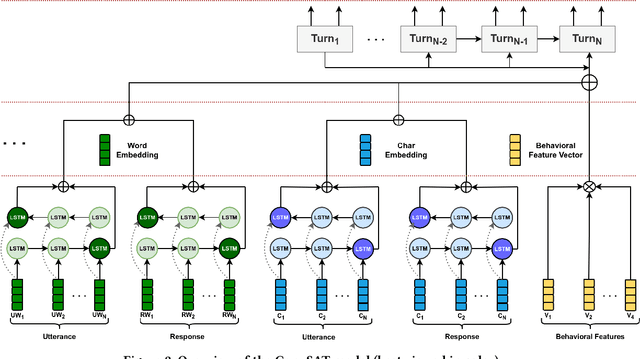

Predicting user satisfaction in conversational systems has become critical, as spoken conversational assistants operate in increasingly complex domains. Online satisfaction prediction (i.e., predicting satisfaction of the user with the system after each turn) could be used as a new proxy for implicit user feedback, and offers promising opportunities to create more responsive and effective conversational agents, which adapt to the user's engagement with the agent. To accomplish this goal, we propose a conversational satisfaction prediction model specifically designed for open-domain spoken conversational agents, called ConvSAT. To operate robustly across domains, ConvSAT aggregates multiple representations of the conversation, namely the conversation history, utterance and response content, and system- and user-oriented behavioral signals. We first calibrate ConvSAT performance against state of the art methods on a standard dataset (Dialogue Breakdown Detection Challenge) in an online regime, and then evaluate ConvSAT on a large dataset of conversations with real users, collected as part of the Alexa Prize competition. Our experimental results show that ConvSAT significantly improves satisfaction prediction for both offline and online setting on both datasets, compared to the previously reported state-of-the-art approaches. The insights from our study can enable more intelligent conversational systems, which could adapt in real-time to the inferred user satisfaction and engagement.
JointMap: Joint Query Intent Understanding For Modeling Intent Hierarchies in E-commerce Search
May 29, 2020
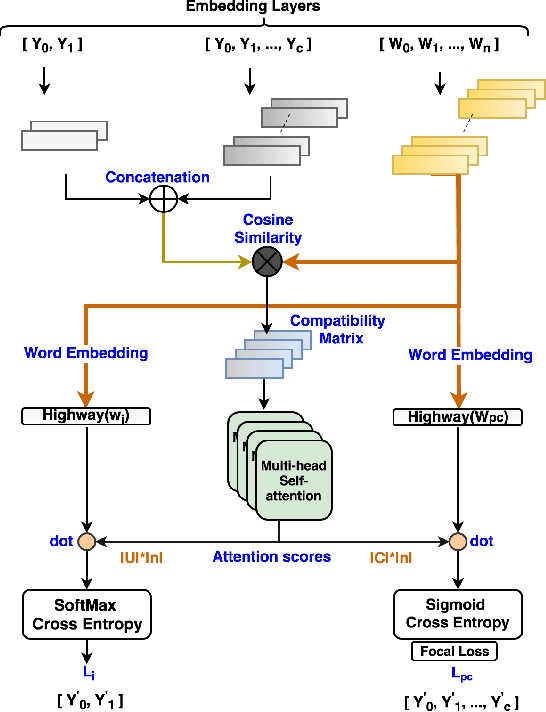
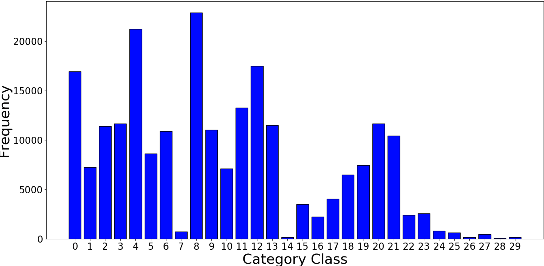
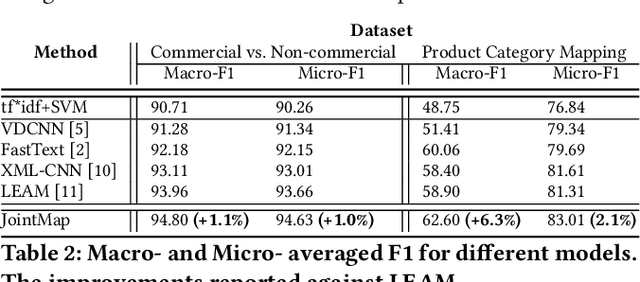
An accurate understanding of a user's query intent can help improve the performance of downstream tasks such as query scoping and ranking. In the e-commerce domain, recent work in query understanding focuses on the query to product-category mapping. But, a small yet significant percentage of queries (in our website 1.5% or 33M queries in 2019) have non-commercial intent associated with them. These intents are usually associated with non-commercial information seeking needs such as discounts, store hours, installation guides, etc. In this paper, we introduce Joint Query Intent Understanding (JointMap), a deep learning model to simultaneously learn two different high-level user intent tasks: 1) identifying a query's commercial vs. non-commercial intent, and 2) associating a set of relevant product categories in taxonomy to a product query. JointMap model works by leveraging the transfer bias that exists between these two related tasks through a joint-learning process. As curating a labeled data set for these tasks can be expensive and time-consuming, we propose a distant supervision approach in conjunction with an active learning model to generate high-quality training data sets. To demonstrate the effectiveness of JointMap, we use search queries collected from a large commercial website. Our results show that JointMap significantly improves both "commercial vs. non-commercial" intent prediction and product category mapping by 2.3% and 10% on average over state-of-the-art deep learning methods. Our findings suggest a promising direction to model the intent hierarchies in an e-commerce search engine.
User Intent Inference for Web Search and Conversational Agents
May 28, 2020User intent understanding is a crucial step in designing both conversational agents and search engines. Detecting or inferring user intent is challenging, since the user utterances or queries can be short, ambiguous, and contextually dependent. To address these research challenges, my thesis work focuses on: 1) Utterance topic and intent classification for conversational agents 2) Query intent mining and classification for Web search engines, focusing on the e-commerce domain. To address the first topic, I proposed novel models to incorporate entity information and conversation-context clues to predict both topic and intent of the user's utterances. For the second research topic, I plan to extend the existing state of the art methods in Web search intent prediction to the e-commerce domain, via: 1) Developing a joint learning model to predict search queries' intents and the product categories associated with them, 2) Discovering new hidden users' intents. All the models will be evaluated on the real queries available from a major e-commerce site search engine. The results from these studies can be leveraged to improve performance of various tasks such as natural language understanding, query scoping, query suggestion, and ranking, resulting in an enriched user experience.