 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAB: Class Representation Attentive BERT for Hate Speech Identification in Social Media
Paper and Code
Oct 25, 2020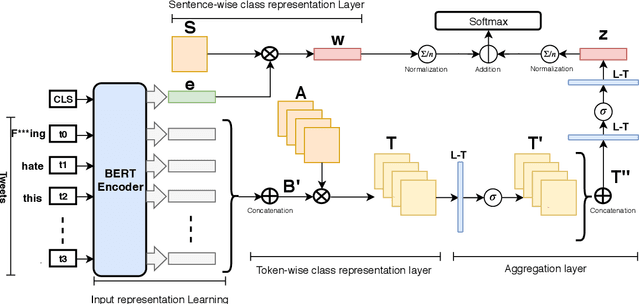
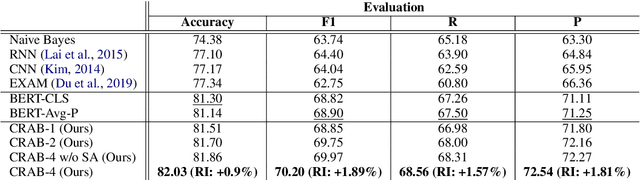
In recent years, social media platforms have hosted an explosion of hate speech and objectionable content. The urgent need for effective automatic hate speech detection models have drawn remarkable investment from companies and researchers. Social media posts are generally short and their semantics could drastically be altered by even a single token. Thus, it is crucial for this task to learn context-aware input representations, and consider relevancy scores between input embeddings and class representations as an additional signal. To accommodate these needs, this paper introduces CRAB (Class Representation Attentive BERT), a neural model for detecting hate speech in social media. The model benefits from two semantic representations: (i) trainable token-wise and sentence-wise class representations, and (ii) contextualized input embeddings from state-of-the-art BERT encoder. To investigate effectiveness of CRAB, we train our model on Twitter data and compare it against strong baselines. Our results show that CRAB achieves 1.89% relative improved Macro-averaged F1 over state-of-the-art baseline. The results of this research open an opportunity for the future research on automated abusive behavior detection in social media