 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Induction of Dialogue Task Schemas with Streaming Refinement and Simulated Interactions
Apr 25, 2025In task-oriented dialogue (TOD) systems, Slot Schema Induction (SSI) is essential for automatically identifying key information slots from dialogue data without manual intervention. This paper presents a novel state-of-the-art (SoTA) approach that formulates SSI as a text generation task, where a language model incrementally constructs and refines a slot schema over a stream of dialogue data. To develop this approach, we present a fully automatic LLM-based TOD simulation method that creates data with high-quality state labels for novel task domains. Furthermore, we identify issues in SSI evaluation due to data leakage and poor metric alignment with human judgment. We resolve these by creating new evaluation data using our simulation method with human guidance and correction, as well as designing improved evaluation metrics. These contributions establish a foundation for future SSI research and advance the SoTA in dialogue understanding and system development.
Transforming Slot Schema Induction with Generative Dialogue State Inference
Aug 03, 2024



The challenge of defining a slot schema to represent the state of a task-oriented dialogue system is addressed by Slot Schema Induction (SSI), which aims to automatically induce slots from unlabeled dialogue data. Whereas previous approaches induce slots by clustering value spans extracted directly from the dialogue text, we demonstrate the power of discovering slots using a generative approach. By training a model to generate slot names and values that summarize key dialogue information with no prior task knowledge, our SSI method discovers high-quality candidate information for representing dialogue state. These discovered slot-value candidates can be easily clustered into unified slot schemas that align well with human-authored schemas. Experimental comparisons on the MultiWOZ and SGD datasets demonstrate that Generative Dialogue State Inference (GenDSI) outperforms the previous state-of-the-art on multiple aspects of the SSI task.
Leveraging Diverse Data Generation for Adaptable Zero-Shot Dialogue State Tracking
May 21, 2024



This work demonstrates that substantial gains in zero-shot dialogue state tracking (DST) accuracy can be achieved by increasing the diversity of training data using synthetic data generation techniques. Current DST training resources are severely limited in the number of application domains and slot types they cover due to the high costs of data collection, resulting in limited adaptability to new domains. The presented work overcomes this challenge using a novel, fully automatic data generation approach to create synthetic zero-shot DST training resources. Unlike previous approaches for generating DST data, the presented approach generates entirely new application domains to generate dialogues, complete with silver dialogue state annotations and slot descriptions. This approach is used to create the D0T dataset for training zero-shot DST models, which covers an unprecedented 1,000+ domains. Experiments performed on the MultiWOZ benchmark indicate that training models on diverse synthetic data yields a performance improvement of +6.7% Joint Goal Accuracy, achieving results competitive with much larger models.
Exploring the Impact of Human Evaluator Group on Chat-Oriented Dialogue Evaluation
Sep 14, 2023
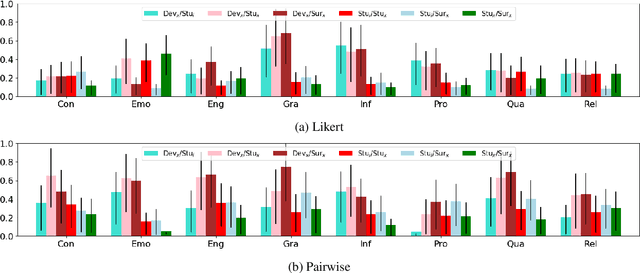


Human evaluation has been widely accepted as the standard for evaluating chat-oriented dialogue systems. However, there is a significant variation in previous work regarding who gets recruited as evaluators. Evaluator groups such as domain experts, university students, and professional annotators have been used to assess and compare dialogue systems, although it is unclear to what extent the choice of an evaluator group can affect results. This paper analyzes the evaluator group impact on dialogue system evaluation by testing 4 state-of-the-art dialogue systems using 4 distinct evaluator groups. Our analysis reveals a robustness towards evaluator groups for Likert evaluations that is not seen for Pairwise, with only minor differences observed when changing evaluator groups. Furthermore, two notable limitations to this robustness are observed, which reveal discrepancies between evaluators with different levels of chatbot expertise and indicate that evaluator objectivity is beneficial for certain dialogue metrics.
Don't Forget Your ABC's: Evaluating the State-of-the-Art in Chat-Oriented Dialogue Systems
Dec 18, 2022



There has been great recent advancement in human-computer chat. However, proper evaluation currently requires human judgements that produce notoriously high-variance metrics due to their inherent subjectivity. Furthermore, there is little standardization in the methods and labels used for evaluation, with an overall lack of work to compare and assess the validity of various evaluation approaches. As a consequence, existing evaluation results likely leave an incomplete picture of the strengths and weaknesses of open-domain chatbots. We aim towards a dimensional evaluation of human-computer chat that can reliably measure several distinct aspects of chat quality. To this end, we present our novel human evaluation method that quantifies the rate of several quality-related chatbot behaviors. Our results demonstrate our method to be more suitable for dimensional chat evaluation than alternative likert-style or comparative methods. We then use our validated method and existing methods to evaluate four open-domain chat models from the recent literature.
What Went Wrong? Explaining Overall Dialogue Quality through Utterance-Level Impacts
Oct 31, 2021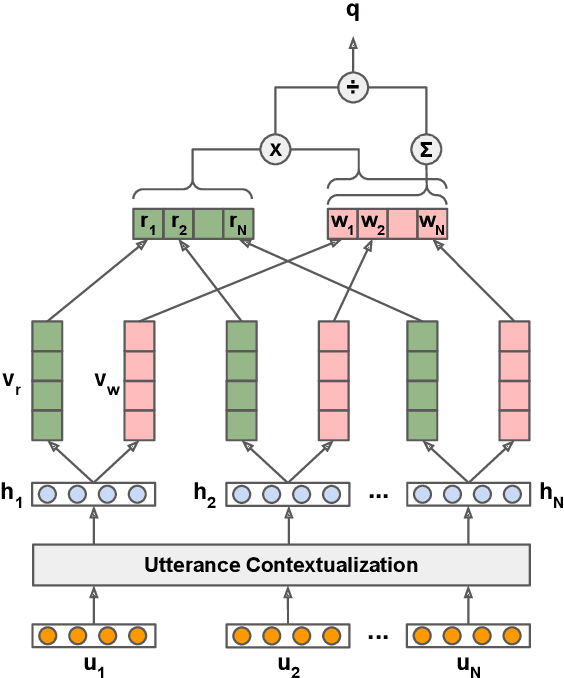
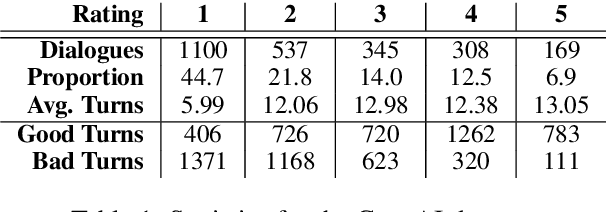

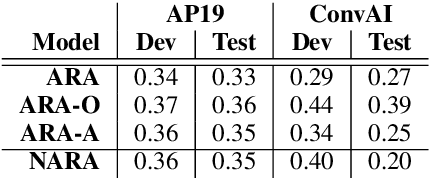
Improving user experience of a dialogue system often requires intensive developer effort to read conversation logs, run statistical analyses, and intuit the relative importance of system shortcomings. This paper presents a novel approach to automated analysis of conversation logs that learns the relationship between user-system interactions and overall dialogue quality. Unlike prior work on utterance-level quality prediction, our approach learns the impact of each interaction from the overall user rating without utterance-level annotation, allowing resultant model conclusions to be derived on the basis of empirical evidence and at low cost. Our model identifies interactions that have a strong correlation with the overall dialogue quality in a chatbot setting. Experiments show that the automated analysis from our model agrees with expert judgments, making this work the first to show that such weakly-supervised learning of utterance-level quality prediction is highly achievable.
An Approach to Inference-Driven Dialogue Management within a Social Chatbot
Oct 31, 2021
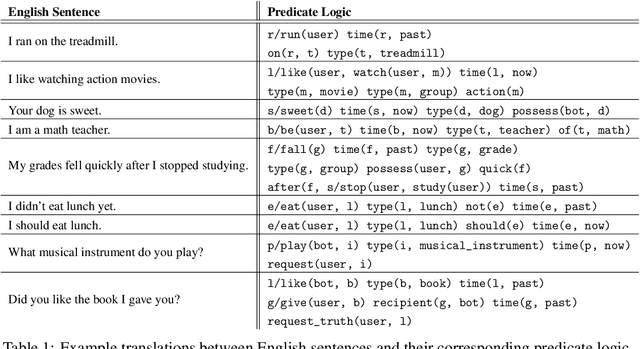

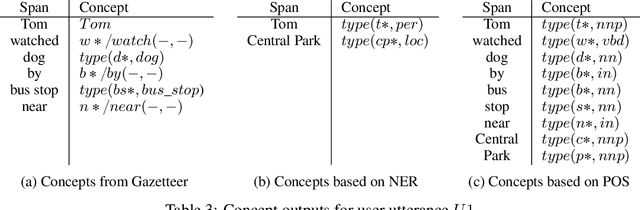
We present a chatbot implementing a novel dialogue management approach based on logical inference. Instead of framing conversation a sequence of response generation tasks, we model conversation as a collaborative inference process in which speakers share information to synthesize new knowledge in real time. Our chatbot pipeline accomplishes this modelling in three broad stages. The first stage translates user utterances into a symbolic predicate representation. The second stage then uses this structured representation in conjunction with a larger knowledge base to synthesize new predicates using efficient graph matching. In the third and final stage, our bot selects a small subset of predicates and translates them into an English response. This approach lends itself to understanding latent semantics of user inputs, flexible initiative taking, and responses that are novel and coherent with the dialogue context.
Emora: An Inquisitive Social Chatbot Who Cares For You
Sep 10, 2020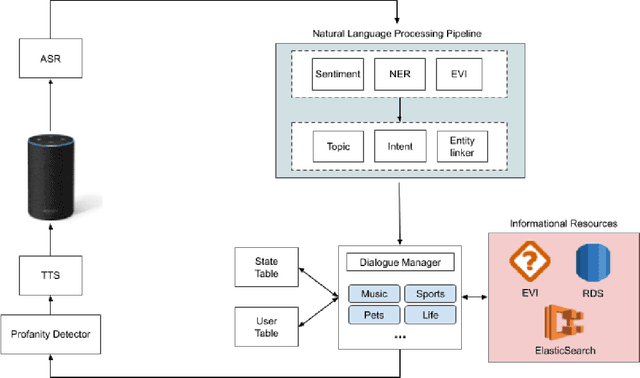
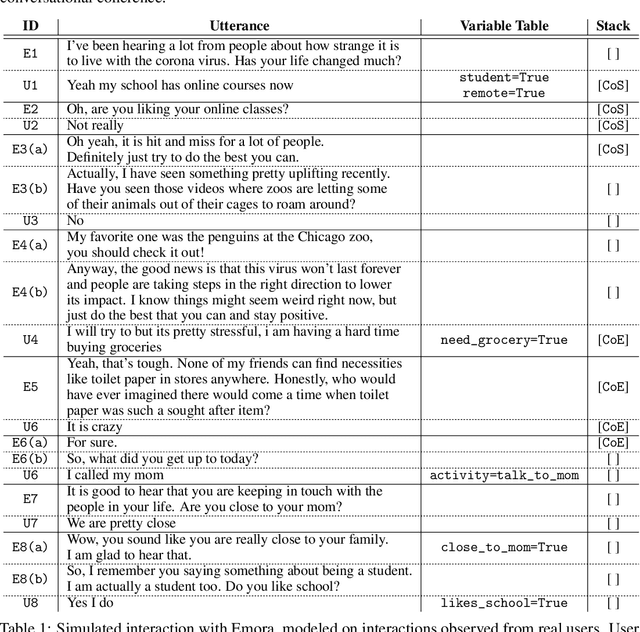
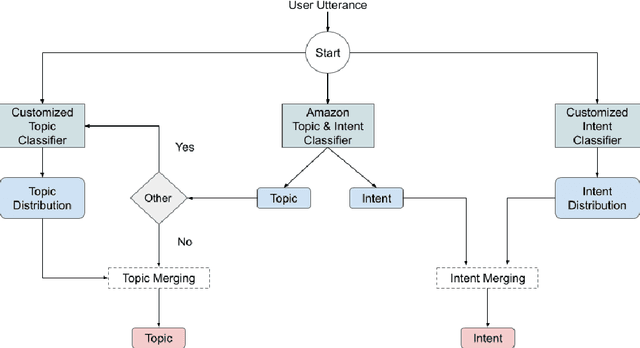
Inspired by studies on the overwhelming presence of experience-sharing in human-human conversations, Emora, the social chatbot developed by Emory University, aims to bring such experience-focused interaction to the current field of conversational AI. The traditional approach of information-sharing topic handlers is balanced with a focus on opinion-oriented exchanges that Emora delivers, and new conversational abilities are developed that support dialogues that consist of a collaborative understanding and learning process of the partner's life experiences. We present a curated dialogue system that leverages highly expressive natural language templates, powerful intent classification, and ontology resources to provide an engaging and interesting conversational experience to every user.
Emora STDM: A Versatile Framework for Innovative Dialogue System Development
Jun 11, 2020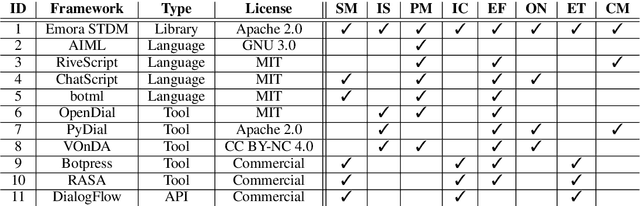
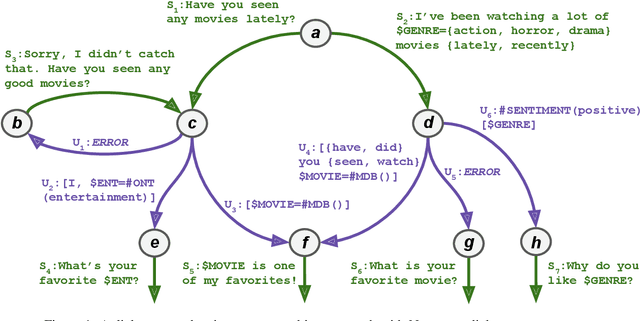
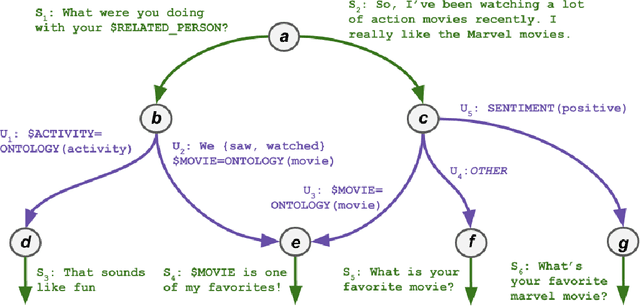
This demo paper presents Emora STDM (State Transition Dialogue Manager), a dialogue system development framework that provides novel workflows for rapid prototyping of chat-based dialogue managers as well as collaborative development of complex interactions. Our framework caters to a wide range of expertise levels by supporting interoperability between two popular approaches, state machine and information state, to dialogue management. Our Natural Language Expression package allows seamless integration of pattern matching, custom NLP modules, and database querying, that makes the workflows much more efficient. As a user study, we adopt this framework to an interdisciplinary undergraduate course where students with both technical and non-technical backgrounds are able to develop creative dialogue managers in a short period of time.