 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Response Interpretation for Automated Structured Interviews: A Case Study in Market Research
Apr 30, 2023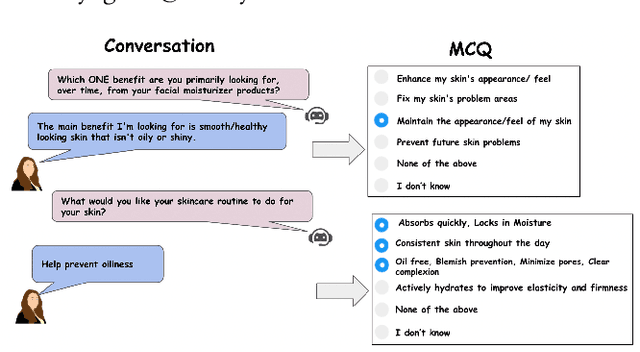
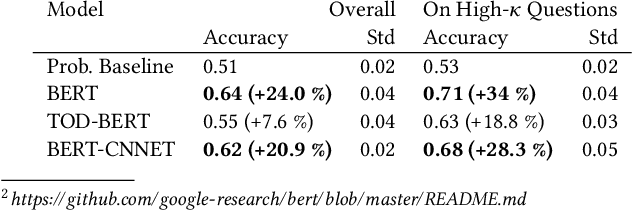
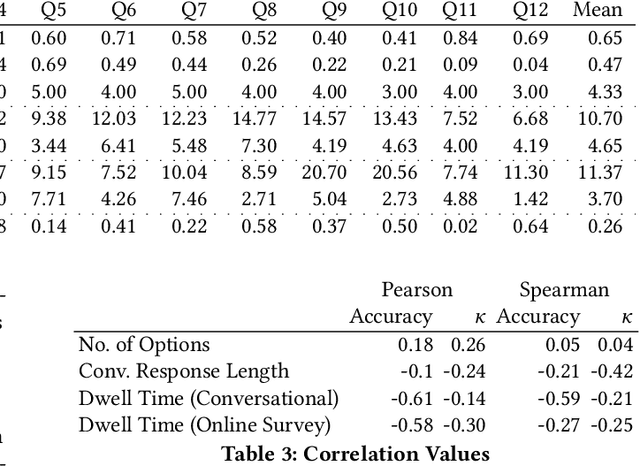
Structured interviews are used in many settings, importantly in market research on topics such as brand perception, customer habits, or preferences, which are critical to product development, marketing, and e-commerce at large. Such interviews generally consist of a series of questions that are asked to a participant. These interviews are typically conducted by skilled interviewers, who interpret the responses from the participants and can adapt the interview accordingly. Using automated conversational agents to conduct such interviews would enable reaching a much larger and potentially more diverse group of participants than currently possible. However, the technical challenges involved in building such a conversational system are relatively unexplored. To learn more about these challenges, we convert a market research multiple-choice questionnaire to a conversational format and conduct a user study. We address the key task of conducting structured interviews, namely interpreting the participant's response, for example, by matching it to one or more predefined options. Our findings can be applied to improve response interpretation for the information elicitation phase of conversational recommender systems.
Emora: An Inquisitive Social Chatbot Who Cares For You
Sep 10, 2020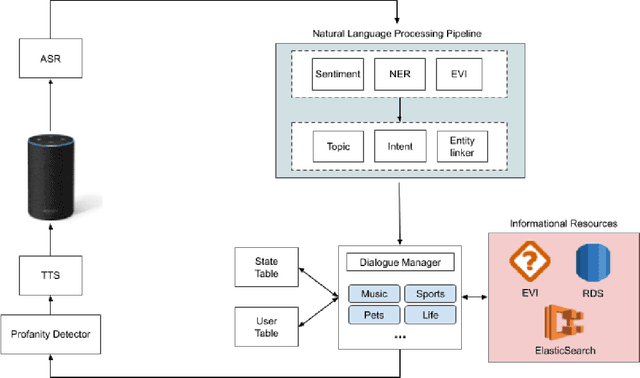
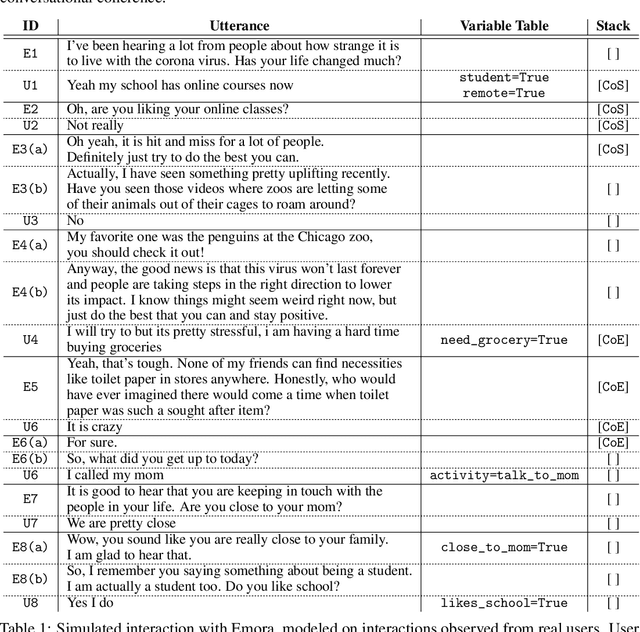
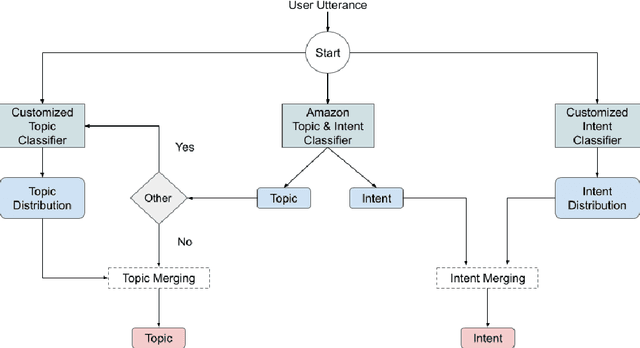
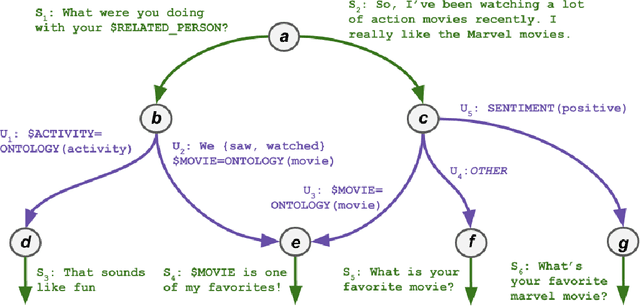
Inspired by studies on the overwhelming presence of experience-sharing in human-human conversations, Emora, the social chatbot developed by Emory University, aims to bring such experience-focused interaction to the current field of conversational AI. The traditional approach of information-sharing topic handlers is balanced with a focus on opinion-oriented exchanges that Emora delivers, and new conversational abilities are developed that support dialogues that consist of a collaborative understanding and learning process of the partner's life experiences. We present a curated dialogue system that leverages highly expressive natural language templates, powerful intent classification, and ontology resources to provide an engaging and interesting conversational experience to every user.
Would you Like to Talk about Sports Now? Towards Contextual Topic Suggestion for Open-Domain Conversational Agents
May 28, 2020
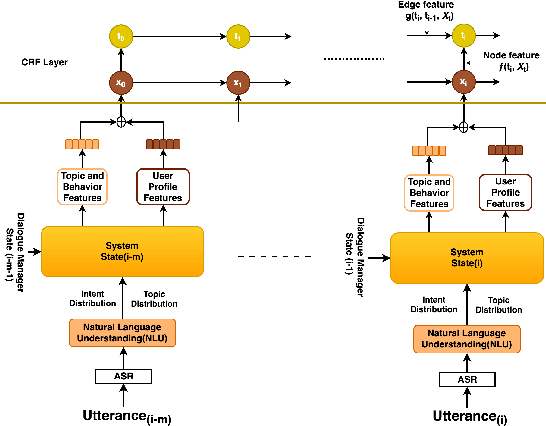

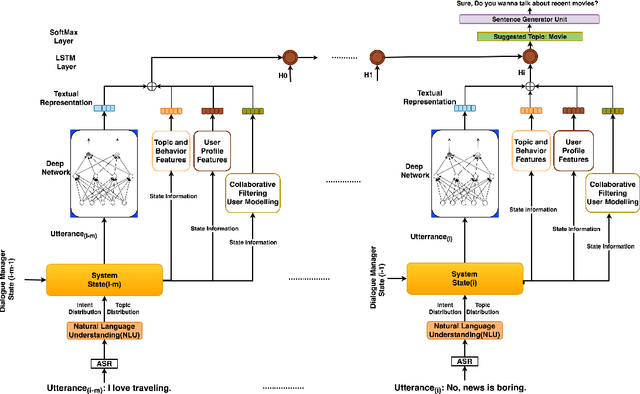
To hold a true conversation, an intelligent agent should be able to occasionally take initiative and recommend the next natural conversation topic. This is a challenging task. A topic suggested by the agent should be relevant to the person, appropriate for the conversation context, and the agent should have something interesting to say about it. Thus, a scripted, or one-size-fits-all, popularity-based topic suggestion is doomed to fail. Instead, we explore different methods for a personalized, contextual topic suggestion for open-domain conversations. We formalize the Conversational Topic Suggestion problem (CTS) to more clearly identify the assumptions and requirements. We also explore three possible approaches to solve this problem: (1) model-based sequential topic suggestion to capture the conversation context (CTS-Seq), (2) Collaborative Filtering-based suggestion to capture previous successful conversations from similar users (CTS-CF), and (3) a hybrid approach combining both conversation context and collaborative filtering. To evaluate the effectiveness of these methods, we use real conversations collected as part of the Amazon Alexa Prize 2018 Conversational AI challenge. The results are promising: the CTS-Seq model suggests topics with 23% higher accuracy than the baseline, and incorporating collaborative filtering signals into a hybrid CTS-Seq-CF model further improves recommendation accuracy by 12%. Together, our proposed models, experiments, and analysis significantly advance the study of open-domain conversational agents, and suggest promising directions for future improvements.
ConCET: Entity-Aware Topic Classification for Open-Domain Conversational Agents
May 28, 2020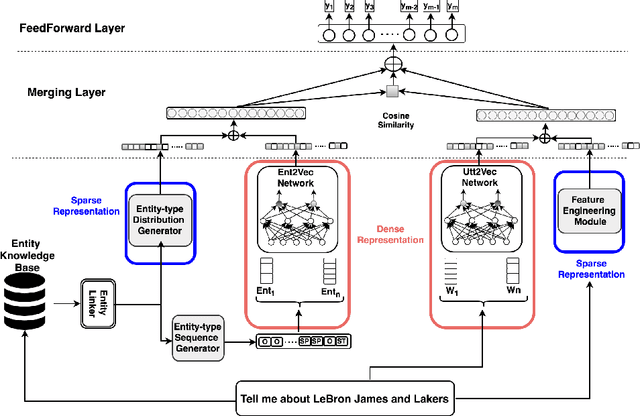

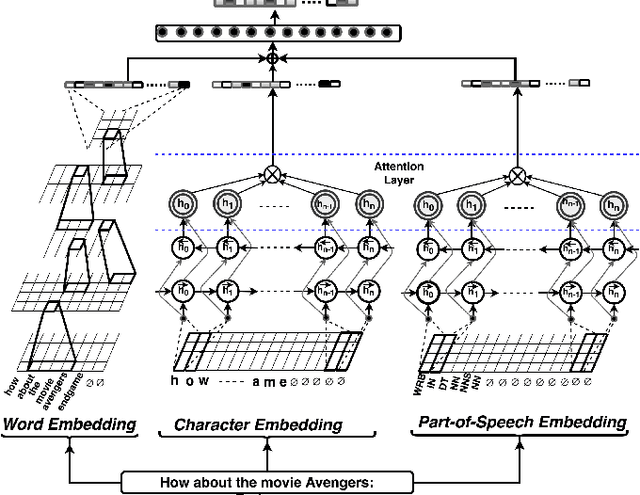
Identifying the topic (domain) of each user's utterance in open-domain conversational systems is a crucial step for all subsequent language understanding and response tasks. In particular, for complex domains, an utterance is often routed to a single component responsible for that domain. Thus, correctly mapping a user utterance to the right domain is critical. To address this problem, we introduce ConCET: a Concurrent Entity-aware conversational Topic classifier, which incorporates entity-type information together with the utterance content features. Specifically, ConCET utilizes entity information to enrich the utterance representation, combining character, word, and entity-type embeddings into a single representation. However, for rich domains with millions of available entities, unrealistic amounts of labeled training data would be required. To complement our model, we propose a simple and effective method for generating synthetic training data, to augment the typically limited amounts of labeled training data, using commonly available knowledge bases to generate additional labeled utterances. We extensively evaluate ConCET and our proposed training method first on an openly available human-human conversational dataset called Self-Dialogue, to calibrate our approach against previous state-of-the-art methods; second, we evaluate ConCET on a large dataset of human-machine conversations with real users, collected as part of the Amazon Alexa Prize. Our results show that ConCET significantly improves topic classification performance on both datasets, including 8-10% improvements over state-of-the-art deep learning methods. We complement our quantitative results with detailed analysis of system performance, which could be used for further improvements of conversational agents.
SimDoc: Topic Sequence Alignment based Document Similarity Framework
Nov 11, 2017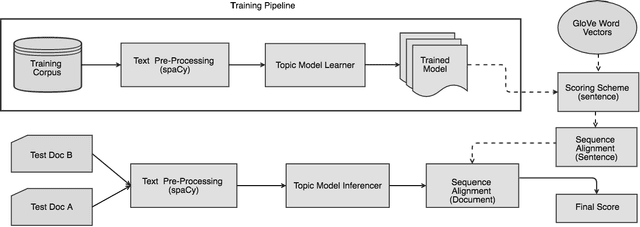

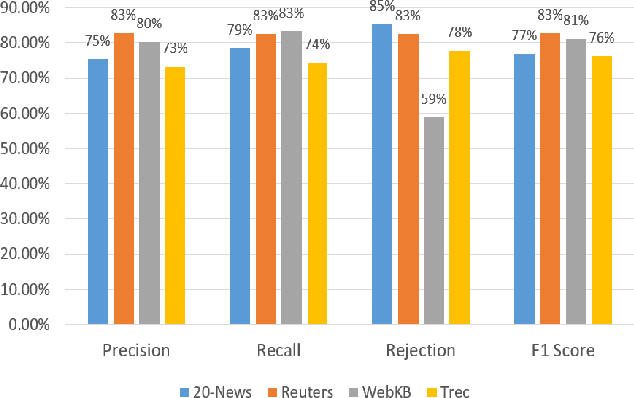

Document similarity is the problem of estimating the degree to which a given pair of documents has similar semantic content. An accurate document similarity measure can improve several enterprise relevant tasks such as document clustering, text mining, and question-answering. In this paper, we show that a document's thematic flow, which is often disregarded by bag-of-word techniques, is pivotal in estimating their similarity. To this end, we propose a novel semantic document similarity framework, called SimDoc. We model documents as topic-sequences, where topics represent latent generative clusters of related words. Then, we use a sequence alignment algorithm to estimate their semantic similarity. We further conceptualize a novel mechanism to compute topic-topic similarity to fine tune our system. In our experiments, we show that SimDoc outperforms many contemporary bag-of-words techniques in accurately computing document similarity, and on practical applications such as document clustering.