 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCET: Entity-Aware Topic Classification for Open-Domain Conversational Agents
Paper and Code
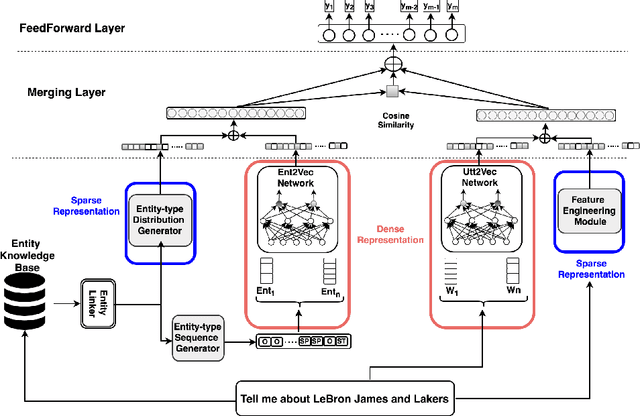

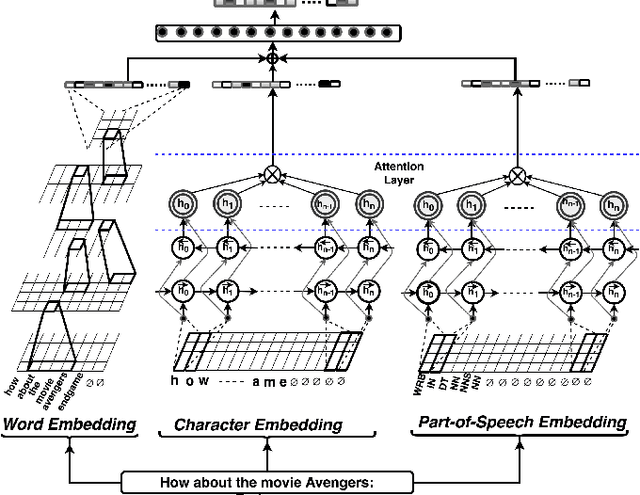
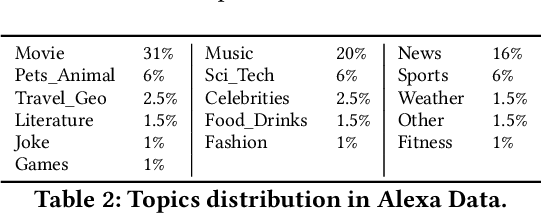
Identifying the topic (domain) of each user's utterance in open-domain conversational systems is a crucial step for all subsequent language understanding and response tasks. In particular, for complex domains, an utterance is often routed to a single component responsible for that domain. Thus, correctly mapping a user utterance to the right domain is critical. To address this problem, we introduce ConCET: a Concurrent Entity-aware conversational Topic classifier, which incorporates entity-type information together with the utterance content features. Specifically, ConCET utilizes entity information to enrich the utterance representation, combining character, word, and entity-type embeddings into a single representation. However, for rich domains with millions of available entities, unrealistic amounts of labeled training data would be required. To complement our model, we propose a simple and effective method for generating synthetic training data, to augment the typically limited amounts of labeled training data, using commonly available knowledge bases to generate additional labeled utterances. We extensively evaluate ConCET and our proposed training method first on an openly available human-human conversational dataset called Self-Dialogue, to calibrate our approach against previous state-of-the-art methods; second, we evaluate ConCET on a large dataset of human-machine conversations with real users, collected as part of the Amazon Alexa Prize. Our results show that ConCET significantly improves topic classification performance on both datasets, including 8-10% improvements over state-of-the-art deep learning methods. We complement our quantitative results with detailed analysis of system performance, which could be used for further improvements of conversational agents.