 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnaphora Resolution in Dialogue: System Description (CODI-CRAC 2022 Shared Task)
Jan 05, 2023



We describe three models submitted for the CODI-CRAC 2022 shared task. To perform identity anaphora resolution, we test several combinations of the incremental clustering approach based on the Workspace Coreference System (WCS) with other coreference models. The best result is achieved by adding the ''cluster merging'' version of the coref-hoi model, which brings up to 10.33% improvement 1 over vanilla WCS clustering. Discourse deixis resolution is implemented as multi-task learning: we combine the learning objective of corefhoi with anaphor type classification. We adapt the higher-order resolution model introduced in Joshi et al. (2019) for bridging resolution given gold mentions and anaphors.
Message Passing for Hyper-Relational Knowledge Graphs
Sep 22, 2020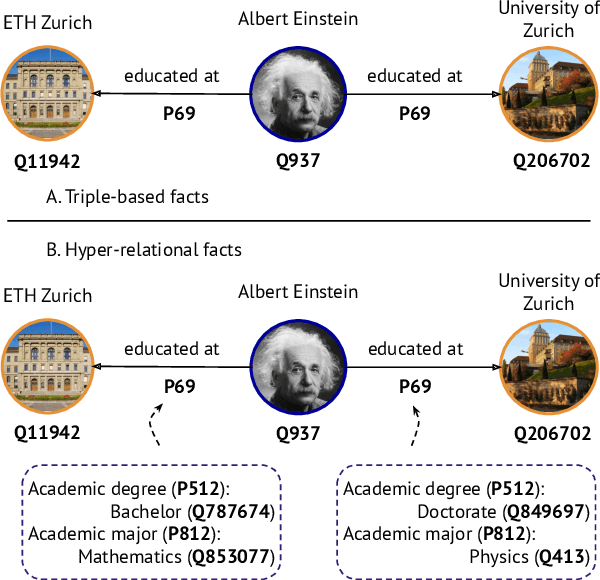
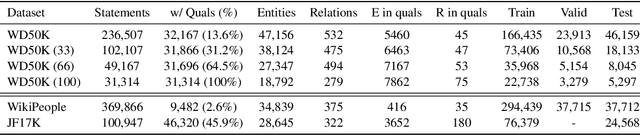
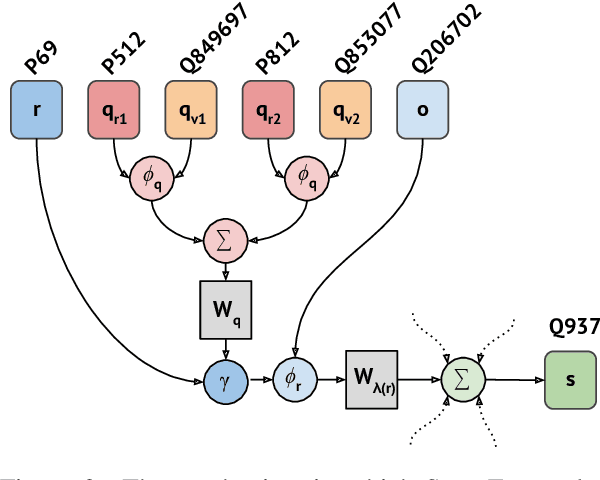
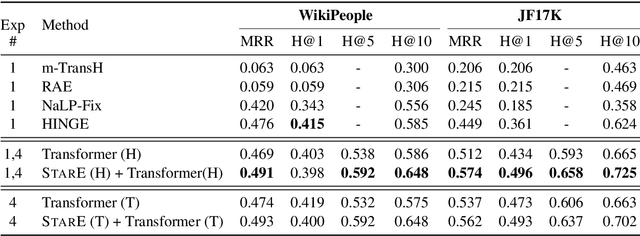
Hyper-relational knowledge graphs (KGs) (e.g., Wikidata) enable associating additional key-value pairs along with the main triple to disambiguate, or restrict the validity of a fact. In this work, we propose a message passing based graph encoder - StarE capable of modeling such hyper-relational KGs. Unlike existing approaches, StarE can encode an arbitrary number of additional information (qualifiers) along with the main triple while keeping the semantic roles of qualifiers and triples intact. We also demonstrate that existing benchmarks for evaluating link prediction (LP) performance on hyper-relational KGs suffer from fundamental flaws and thus develop a new Wikidata-based dataset - WD50K. Our experiments demonstrate that StarE based LP model outperforms existing approaches across multiple benchmarks. We also confirm that leveraging qualifiers is vital for link prediction with gains up to 25 MRR points compared to triple-based representations.
Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
Jul 22, 2019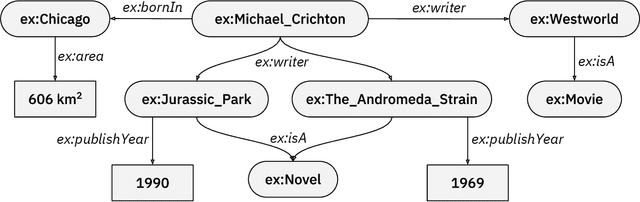
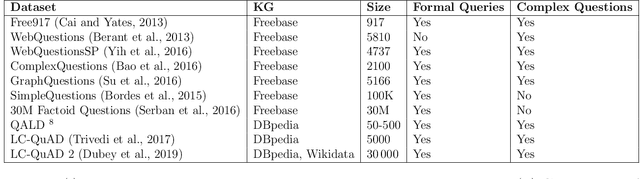
Question answering has emerged as an intuitive way of querying structured data sources, and has attracted significant advancements over the years. In this article, we provide an overview over these recent advancements, focusing on neural network based question answering systems over knowledge graphs. We introduce readers to the challenges in the tasks, current paradigms of approaches, discuss notable advancements, and outline the emerging trends in the field. Through this article, we aim to provide newcomers to the field with a suitable entry point, and ease their process of making informed decisions while creating their own QA system.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs
Nov 02, 2018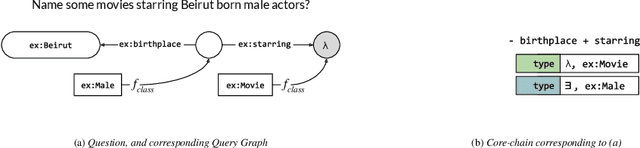
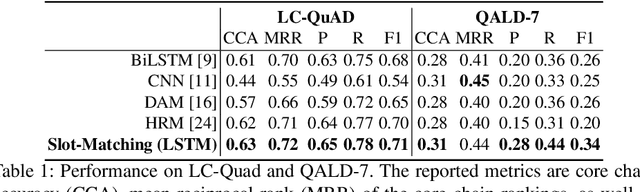
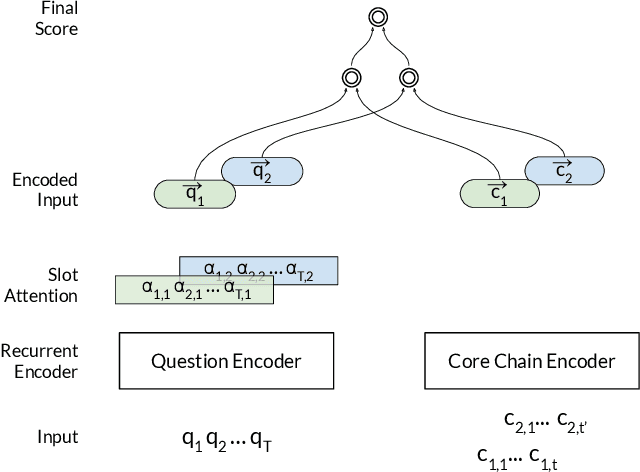
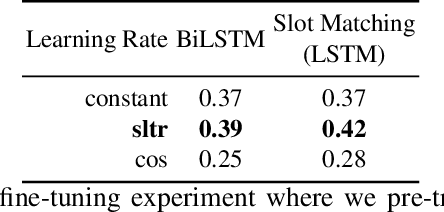
In this paper, we conduct an empirical investigation of neural query graph ranking approaches for the task of complex question answering over knowledge graphs. We experiment with six different ranking models and propose a novel self-attention based slot matching model which exploits the inherent structure of query graphs, our logical form of choice. Our proposed model generally outperforms the other models on two QA datasets over the DBpedia knowledge graph, evaluated in different settings. In addition, we show that transfer learning from the larger of those QA datasets to the smaller dataset yields substantial improvements, effectively offsetting the general lack of training data.
Formal Ontology Learning from English IS-A Sentences
Feb 11, 2018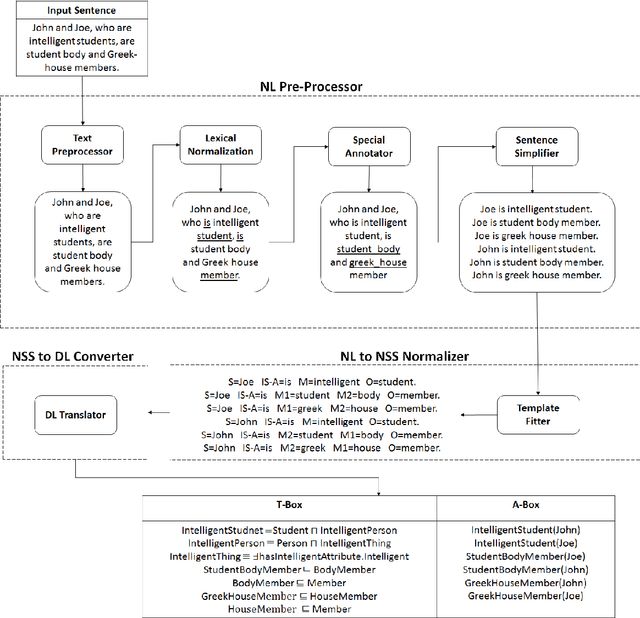
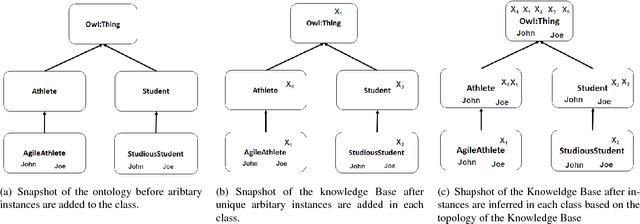
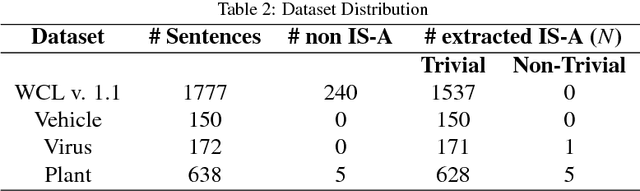

Ontology learning (OL) is the process of automatically generating an ontological knowledge base from a plain text document. In this paper, we propose a new ontology learning approach and tool, called DLOL, which generates a knowledge base in the description logic (DL) SHOQ(D) from a collection of factual non-negative IS-A sentences in English. We provide extensive experimental results on the accuracy of DLOL, giving experimental comparisons to three state-of-the-art existing OL tools, namely Text2Onto, FRED, and LExO. Here, we use the standard OL accuracy measure, called lexical accuracy, and a novel OL accuracy measure, called instance-based inference model. In our experimental results, DLOL turns out to be about 21% and 46%, respectively, better than the best of the other three approaches.
SimDoc: Topic Sequence Alignment based Document Similarity Framework
Nov 11, 2017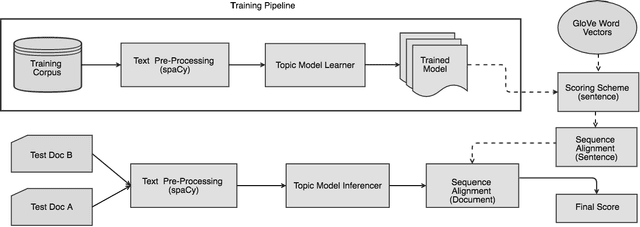

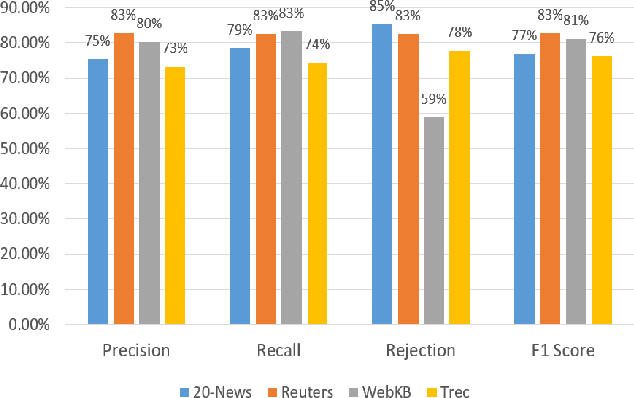

Document similarity is the problem of estimating the degree to which a given pair of documents has similar semantic content. An accurate document similarity measure can improve several enterprise relevant tasks such as document clustering, text mining, and question-answering. In this paper, we show that a document's thematic flow, which is often disregarded by bag-of-word techniques, is pivotal in estimating their similarity. To this end, we propose a novel semantic document similarity framework, called SimDoc. We model documents as topic-sequences, where topics represent latent generative clusters of related words. Then, we use a sequence alignment algorithm to estimate their semantic similarity. We further conceptualize a novel mechanism to compute topic-topic similarity to fine tune our system. In our experiments, we show that SimDoc outperforms many contemporary bag-of-words techniques in accurately computing document similarity, and on practical applications such as document clustering.
BitSim: An Algebraic Similarity Measure for Description Logics Concepts
Mar 19, 2015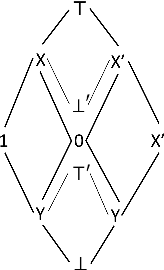
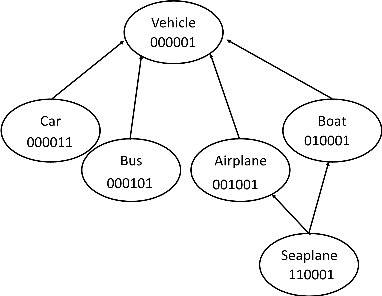
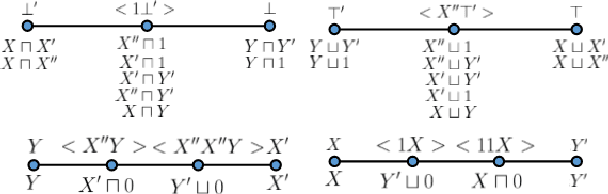
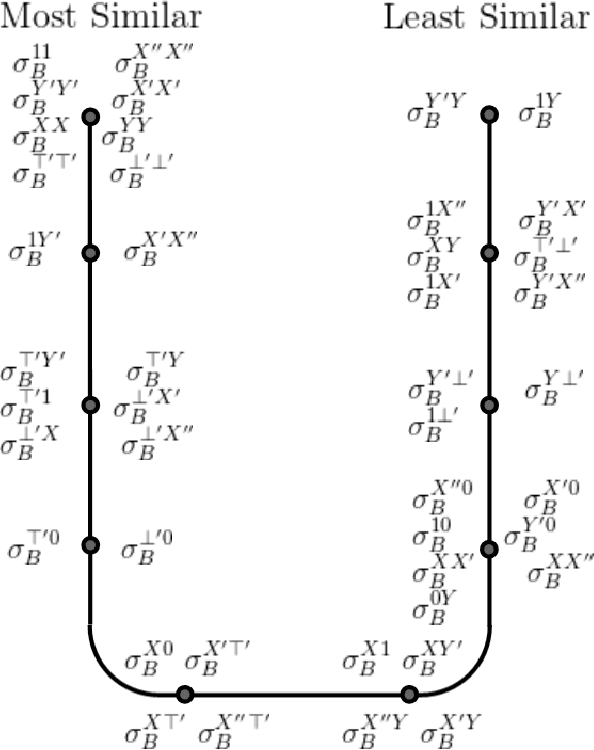
In this paper, we propose an algebraic similarity measure {\sigma}BS (BS stands for BitSim) for assigning semantic similarity score to concept definitions in ALCH+ an expressive fragment of Description Logics (DL). We define an algebraic interpretation function, I_B, that maps a concept definition to a unique string ({\omega}_B) called bit-code) over an alphabet {\Sigma}_B of 11 symbols belonging to L_B - the language over P B. IB has semantic correspondence with conventional model-theoretic interpretation of DL. We then define {\sigma}_BS on L_B. A detailed analysis of I_B and {\sigma}_BS has been given.