 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Datasets for Custom Input Extraction and Explanation Requests Parsing in Conversational XAI Systems
Aug 20, 2025Conversational explainable artificial intelligence (ConvXAI) systems based on large language models (LLMs) have garnered considerable attention for their ability to enhance user comprehension through dialogue-based explanations. Current ConvXAI systems often are based on intent recognition to accurately identify the user's desired intention and map it to an explainability method. While such methods offer great precision and reliability in discerning users' underlying intentions for English, a significant challenge in the scarcity of training data persists, which impedes multilingual generalization. Besides, the support for free-form custom inputs, which are user-defined data distinct from pre-configured dataset instances, remains largely limited. To bridge these gaps, we first introduce MultiCoXQL, a multilingual extension of the CoXQL dataset spanning five typologically diverse languages, including one low-resource language. Subsequently, we propose a new parsing approach aimed at enhancing multilingual parsing performance, and evaluate three LLMs on MultiCoXQL using various parsing strategies. Furthermore, we present Compass, a new multilingual dataset designed for custom input extraction in ConvXAI systems, encompassing 11 intents across the same five languages as MultiCoXQL. We conduct monolingual, cross-lingual, and multilingual evaluations on Compass, employing three LLMs of varying sizes alongside BERT-type models.
When Scale Meets Diversity: Evaluating Language Models on Fine-Grained Multilingual Claim Verification
Jul 28, 2025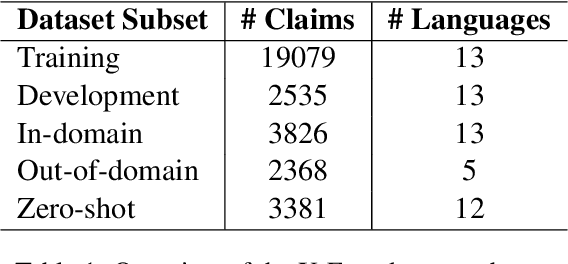
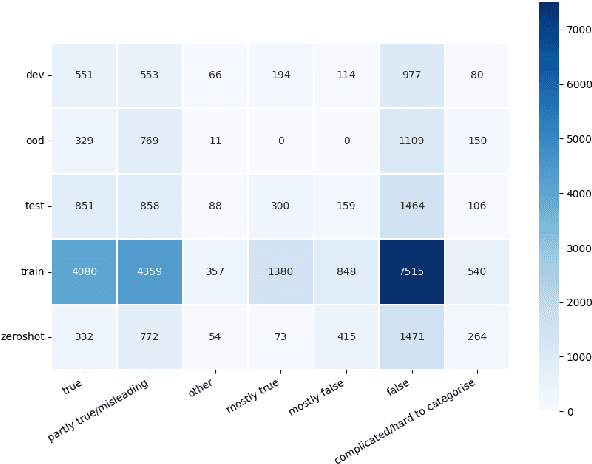
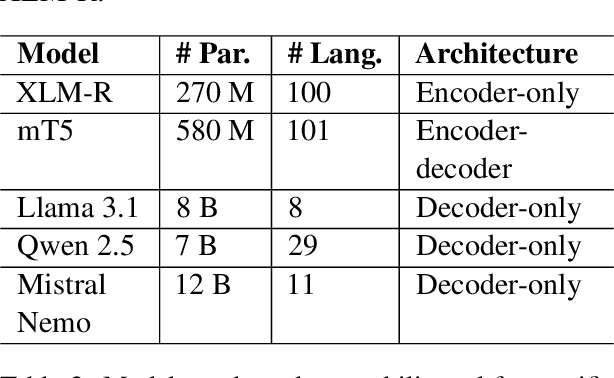
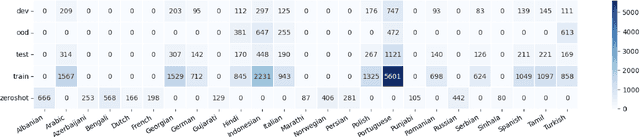
The rapid spread of multilingual misinformation requires robust automated fact verification systems capable of handling fine-grained veracity assessments across diverse languages. While large language models have shown remarkable capabilities across many NLP tasks, their effectiveness for multilingual claim verification with nuanced classification schemes remains understudied. We conduct a comprehensive evaluation of five state-of-the-art language models on the X-Fact dataset, which spans 25 languages with seven distinct veracity categories. Our experiments compare small language models (encoder-based XLM-R and mT5) with recent decoder-only LLMs (Llama 3.1, Qwen 2.5, Mistral Nemo) using both prompting and fine-tuning approaches. Surprisingly, we find that XLM-R (270M parameters) substantially outperforms all tested LLMs (7-12B parameters), achieving 57.7% macro-F1 compared to the best LLM performance of 16.9%. This represents a 15.8% improvement over the previous state-of-the-art (41.9%), establishing new performance benchmarks for multilingual fact verification. Our analysis reveals problematic patterns in LLM behavior, including systematic difficulties in leveraging evidence and pronounced biases toward frequent categories in imbalanced data settings. These findings suggest that for fine-grained multilingual fact verification, smaller specialized models may be more effective than general-purpose large models, with important implications for practical deployment of fact-checking systems.
What Language(s) Does Aya-23 Think In? How Multilinguality Affects Internal Language Representations
Jul 27, 2025Large language models (LLMs) excel at multilingual tasks, yet their internal language processing remains poorly understood. We analyze how Aya-23-8B, a decoder-only LLM trained on balanced multilingual data, handles code-mixed, cloze, and translation tasks compared to predominantly monolingual models like Llama 3 and Chinese-LLaMA-2. Using logit lens and neuron specialization analyses, we find: (1) Aya-23 activates typologically related language representations during translation, unlike English-centric models that rely on a single pivot language; (2) code-mixed neuron activation patterns vary with mixing rates and are shaped more by the base language than the mixed-in one; and (3) Aya-23's languagespecific neurons for code-mixed inputs concentrate in final layers, diverging from prior findings on decoder-only models. Neuron overlap analysis further shows that script similarity and typological relations impact processing across model types. These findings reveal how multilingual training shapes LLM internals and inform future cross-lingual transfer research.
Large Language Models for Multilingual Previously Fact-Checked Claim Detection
Mar 04, 2025In our era of widespread false information, human fact-checkers often face the challenge of duplicating efforts when verifying claims that may have already been addressed in other countries or languages. As false information transcends linguistic boundaries, the ability to automatically detect previously fact-checked claims across languages has become an increasingly important task. This paper presents the first comprehensive evaluation of large language models (LLMs) for multilingual previously fact-checked claim detection. We assess seven LLMs across 20 languages in both monolingual and cross-lingual settings. Our results show that while LLMs perform well for high-resource languages, they struggle with low-resource languages. Moreover, translating original texts into English proved to be beneficial for low-resource languages. These findings highlight the potential of LLMs for multilingual previously fact-checked claim detection and provide a foundation for further research on this promising application of LLMs.
Reverse Probing: Evaluating Knowledge Transfer via Finetuned Task Embeddings for Coreference Resolution
Jan 31, 2025



In this work, we reimagine classical probing to evaluate knowledge transfer from simple source to more complex target tasks. Instead of probing frozen representations from a complex source task on diverse simple target probing tasks (as usually done in probing), we explore the effectiveness of embeddings from multiple simple source tasks on a single target task. We select coreference resolution, a linguistically complex problem requiring contextual understanding, as focus target task, and test the usefulness of embeddings from comparably simpler tasks tasks such as paraphrase detection, named entity recognition, and relation extraction. Through systematic experiments, we evaluate the impact of individual and combined task embeddings. Our findings reveal that task embeddings vary significantly in utility for coreference resolution, with semantic similarity tasks (e.g., paraphrase detection) proving most beneficial. Additionally, representations from intermediate layers of fine-tuned models often outperform those from final layers. Combining embeddings from multiple tasks consistently improves performance, with attention-based aggregation yielding substantial gains. These insights shed light on relationships between task-specific representations and their adaptability to complex downstream tasks, encouraging further exploration of embedding-level task transfer.
Cross-Refine: Improving Natural Language Explanation Generation by Learning in Tandem
Sep 11, 2024Natural language explanations (NLEs) are vital for elucidating the reasoning behind large language model (LLM) decisions. Many techniques have been developed to generate NLEs using LLMs. However, like humans, LLMs might not always produce optimal NLEs on first attempt. Inspired by human learning processes, we introduce Cross-Refine, which employs role modeling by deploying two LLMs as generator and critic, respectively. The generator outputs a first NLE and then refines this initial explanation using feedback and suggestions provided by the critic. Cross-Refine does not require any supervised training data or additional training. We validate Cross-Refine across three NLP tasks using three state-of-the-art open-source LLMs through automatic and human evaluation. We select Self-Refine (Madaan et al., 2023) as the baseline, which only utilizes self-feedback to refine the explanations. Our findings from automatic evaluation and a user study indicate that Cross-Refine outperforms Self-Refine. Meanwhile, Cross-Refine can perform effectively with less powerful LLMs, whereas Self-Refine only yields strong results with ChatGPT. Additionally, we conduct an ablation study to assess the importance of feedback and suggestions. Both of them play an important role in refining explanations. We further evaluate Cross-Refine on a bilingual dataset in English and German.
Multilingual Large Language Models and Curse of Multilinguality
Jun 15, 2024

Multilingual Large Language Models (LLMs) have gained large popularity among Natural Language Processing (NLP) researchers and practitioners. These models, trained on huge datasets, show proficiency across various languages and demonstrate effectiveness in numerous downstream tasks. This paper navigates the landscape of multilingual LLMs, providing an introductory overview of their technical aspects. It explains underlying architectures, objective functions, pre-training data sources, and tokenization methods. This work explores the unique features of different model types: encoder-only (mBERT, XLM-R), decoder-only (XGLM, PALM, BLOOM, GPT-3), and encoder-decoder models (mT5, mBART). Additionally, it addresses one of the significant limitations of multilingual LLMs - the curse of multilinguality - and discusses current attempts to overcome it.
CoXQL: A Dataset for Parsing Explanation Requests in Conversational XAI Systems
Jun 12, 2024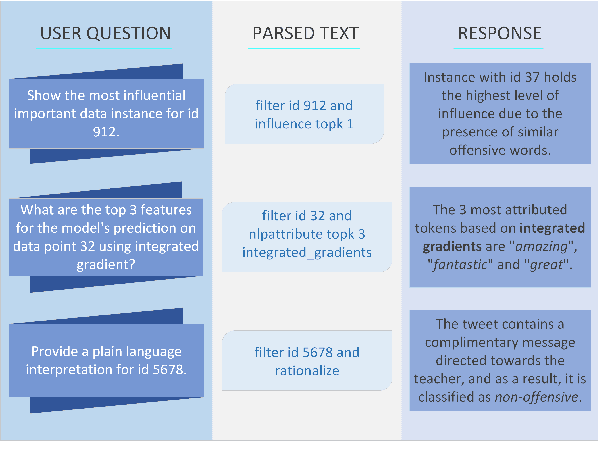

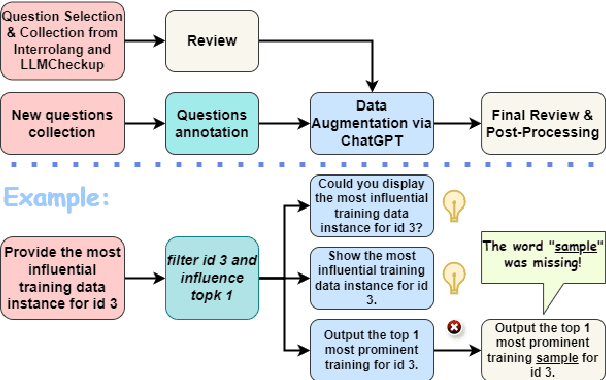

Conversational explainable artificial intelligence (ConvXAI) systems based on large language models (LLMs) have garnered significant interest from the research community in natural language processing (NLP) and human-computer interaction (HCI). Such systems can provide answers to user questions about explanations, have the potential to enhance users' comprehension and offer more information about the decision-making and generation processes of LLMs. Currently available ConvXAI systems are based on intent recognition rather than free chat. Thus, reliably grasping users' intentions in ConvXAI systems still presents a challenge, because there is a broad range of XAI methods to map requests onto and each of them can have multiple slots to take care of. In order to bridge this gap, we present CoXQL, the first dataset for user intent recognition in ConvXAI, covering 31 intents, seven of which require filling additional slots. Subsequently, we enhance an existing parsing approach by incorporating template validations, and conduct an evaluation of several LLMs on CoXQL using different parsing strategies. We conclude that the improved parsing approach (MP+) surpasses the performance of previous approaches. We also discover that intents with multiple slots remain highly challenging for LLMs.
LLMCheckup: Conversational Examination of Large Language Models via Interpretability Tools
Jan 23, 2024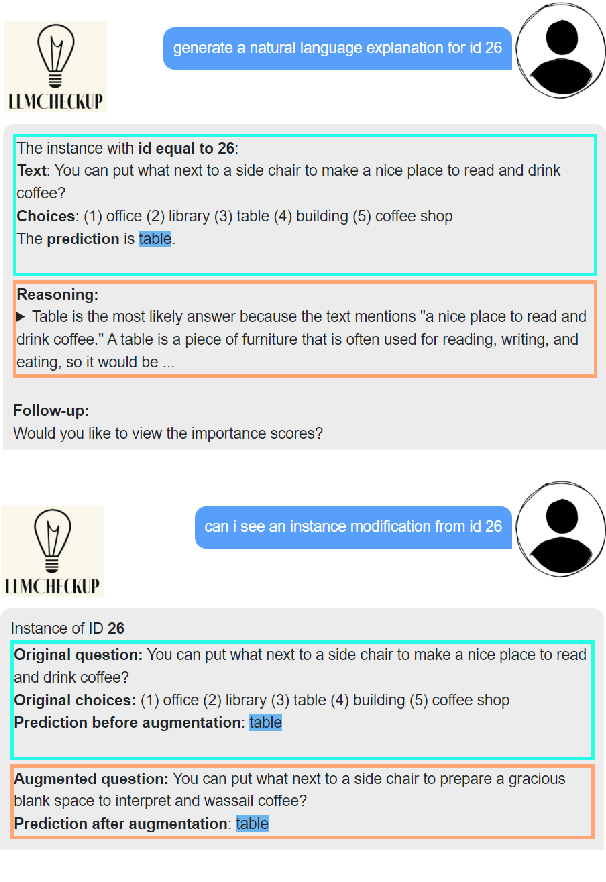

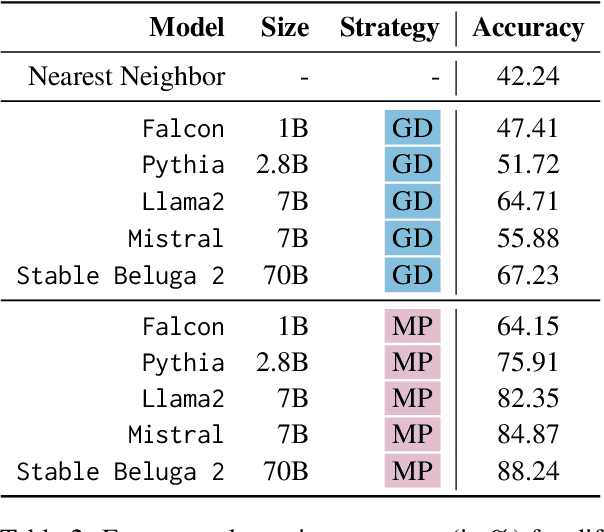
Interpretability tools that offer explanations in the form of a dialogue have demonstrated their efficacy in enhancing users' understanding, as one-off explanations may occasionally fall short in providing sufficient information to the user. Current solutions for dialogue-based explanations, however, require many dependencies and are not easily transferable to tasks they were not designed for. With LLMCheckup, we present an easily accessible tool that allows users to chat with any state-of-the-art large language model (LLM) about its behavior. We enable LLMs to generate all explanations by themselves and take care of intent recognition without fine-tuning, by connecting them with a broad spectrum of Explainable AI (XAI) tools, e.g. feature attributions, embedding-based similarity, and prompting strategies for counterfactual and rationale generation. LLM (self-)explanations are presented as an interactive dialogue that supports follow-up questions and generates suggestions. LLMCheckup provides tutorials for operations available in the system, catering to individuals with varying levels of expertise in XAI and supports multiple input modalities. We introduce a new parsing strategy called multi-prompt parsing substantially enhancing the parsing accuracy of LLMs. Finally, we showcase the tasks of fact checking and commonsense question answering.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023



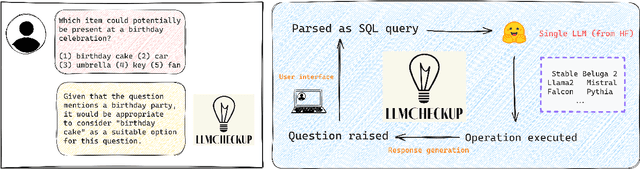
While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.