 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeskLEP: A Slovak General Language Understanding Benchmark
Jun 26, 2025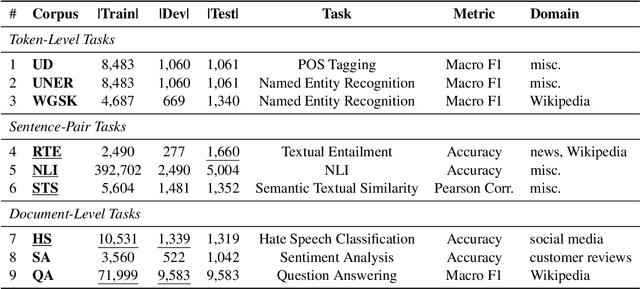

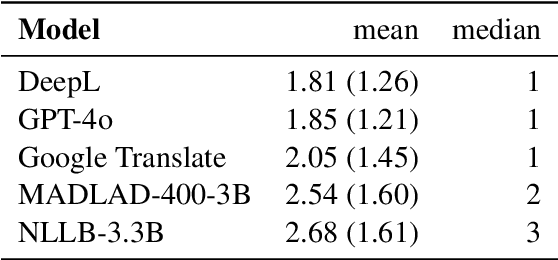
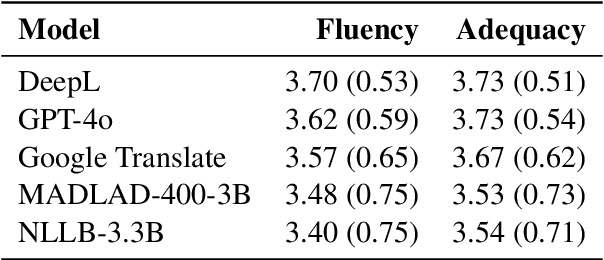
In this work, we introduce skLEP, the first comprehensive benchmark specifically designed for evaluating Slovak natural language understanding (NLU) models. We have compiled skLEP to encompass nine diverse tasks that span token-level, sentence-pair, and document-level challenges, thereby offering a thorough assessment of model capabilities. To create this benchmark, we curated new, original datasets tailored for Slovak and meticulously translated established English NLU resources. Within this paper, we also present the first systematic and extensive evaluation of a wide array of Slovak-specific, multilingual, and English pre-trained language models using the skLEP tasks. Finally, we also release the complete benchmark data, an open-source toolkit facilitating both fine-tuning and evaluation of models, and a public leaderboard at https://github.com/slovak-nlp/sklep in the hopes of fostering reproducibility and drive future research in Slovak NLU.
Large Language Models for Multilingual Previously Fact-Checked Claim Detection
Mar 04, 2025In our era of widespread false information, human fact-checkers often face the challenge of duplicating efforts when verifying claims that may have already been addressed in other countries or languages. As false information transcends linguistic boundaries, the ability to automatically detect previously fact-checked claims across languages has become an increasingly important task. This paper presents the first comprehensive evaluation of large language models (LLMs) for multilingual previously fact-checked claim detection. We assess seven LLMs across 20 languages in both monolingual and cross-lingual settings. Our results show that while LLMs perform well for high-resource languages, they struggle with low-resource languages. Moreover, translating original texts into English proved to be beneficial for low-resource languages. These findings highlight the potential of LLMs for multilingual previously fact-checked claim detection and provide a foundation for further research on this promising application of LLMs.
Generative Large Language Models in Automated Fact-Checking: A Survey
Jul 02, 2024



The dissemination of false information across online platforms poses a serious societal challenge, necessitating robust measures for information verification. While manual fact-checking efforts are still instrumental, the growing volume of false information requires automated methods. Large language models (LLMs) offer promising opportunities to assist fact-checkers, leveraging LLM's extensive knowledge and robust reasoning capabilities. In this survey paper, we investigate the utilization of generative LLMs in the realm of fact-checking, illustrating various approaches that have been employed and techniques for prompting or fine-tuning LLMs. By providing an overview of existing approaches, this survey aims to improve the understanding of utilizing LLMs in fact-checking and to facilitate further progress in LLMs' involvement in this process.
Soft Language Prompts for Language Transfer
Jul 02, 2024


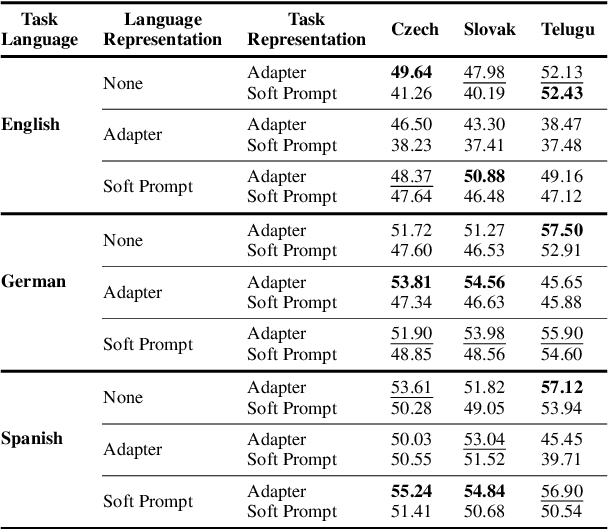
Cross-lingual knowledge transfer, especially between high- and low-resource languages, remains a challenge in natural language processing (NLP). This study offers insights for improving cross-lingual NLP applications through the combination of parameter-efficient fine-tuning methods. We systematically explore strategies for enhancing this cross-lingual transfer through the incorporation of language-specific and task-specific adapters and soft prompts. We present a detailed investigation of various combinations of these methods, exploring their efficiency across six languages, focusing on three low-resource languages, including the to our knowledge first use of soft language prompts. Our findings demonstrate that in contrast to claims of previous work, a combination of language and task adapters does not always work best; instead, combining a soft language prompt with a task adapter outperforms other configurations in many cases.
Beyond Image-Text Matching: Verb Understanding in Multimodal Transformers Using Guided Masking
Jan 29, 2024The dominant probing approaches rely on the zero-shot performance of image-text matching tasks to gain a finer-grained understanding of the representations learned by recent multimodal image-language transformer models. The evaluation is carried out on carefully curated datasets focusing on counting, relations, attributes, and others. This work introduces an alternative probing strategy called guided masking. The proposed approach ablates different modalities using masking and assesses the model's ability to predict the masked word with high accuracy. We focus on studying multimodal models that consider regions of interest (ROI) features obtained by object detectors as input tokens. We probe the understanding of verbs using guided masking on ViLBERT, LXMERT, UNITER, and VisualBERT and show that these models can predict the correct verb with high accuracy. This contrasts with previous conclusions drawn from image-text matching probing techniques that frequently fail in situations requiring verb understanding. The code for all experiments will be publicly available https://github.com/ivana-13/guided_masking.
Women Are Beautiful, Men Are Leaders: Gender Stereotypes in Machine Translation and Language Modeling
Nov 30, 2023



We present GEST -- a new dataset for measuring gender-stereotypical reasoning in masked LMs and English-to-X machine translation systems. GEST contains samples that are compatible with 9 Slavic languages and English for 16 gender stereotypes about men and women (e.g., Women are beautiful, Men are leaders). The definition of said stereotypes was informed by gender experts. We used GEST to evaluate 11 masked LMs and 4 machine translation systems. We discovered significant and consistent amounts of stereotypical reasoning in almost all the evaluated models and languages.
Average Is Not Enough: Caveats of Multilingual Evaluation
Jan 03, 2023This position paper discusses the problem of multilingual evaluation. Using simple statistics, such as average language performance, might inject linguistic biases in favor of dominant language families into evaluation methodology. We argue that a qualitative analysis informed by comparative linguistics is needed for multilingual results to detect this kind of bias. We show in our case study that results in published works can indeed be linguistically biased and we demonstrate that visualization based on URIEL typological database can detect it.
SlovakBERT: Slovak Masked Language Model
Sep 30, 2021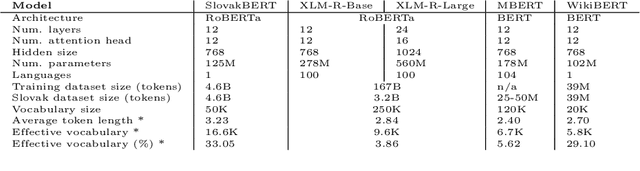
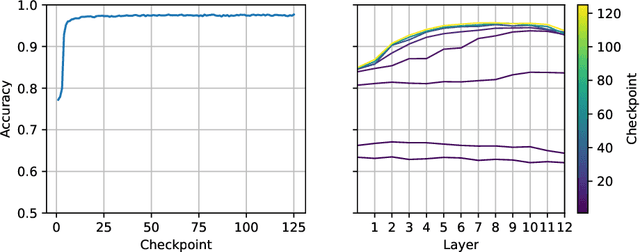

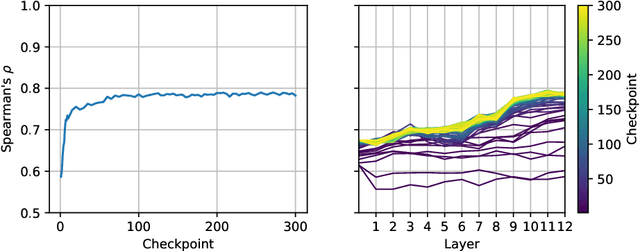
We introduce a new Slovak masked language model called SlovakBERT in this paper. It is the first Slovak-only transformers-based model trained on a sizeable corpus. We evaluate the model on several NLP tasks and achieve state-of-the-art results. We publish the masked language model, as well as the subsequently fine-tuned models for part-of-speech tagging, sentiment analysis and semantic textual similarity.
Improving Moderation of Online Discussions via Interpretable Neural Models
Sep 18, 2018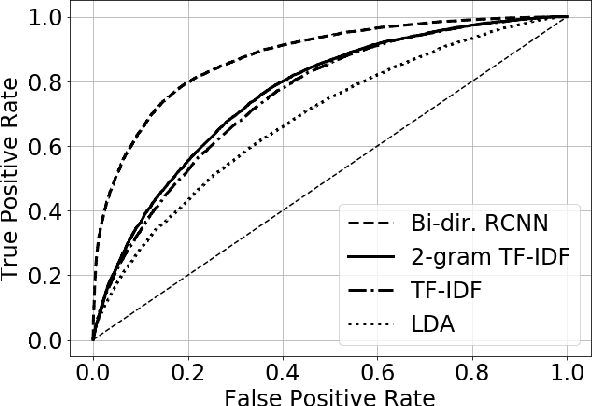
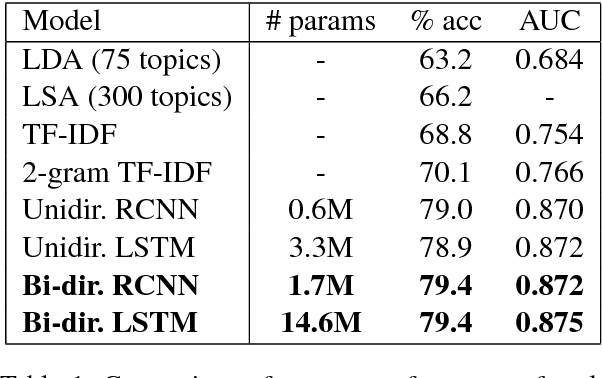
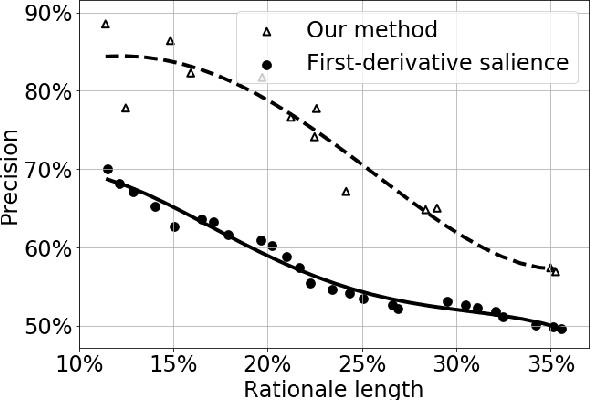
Growing amount of comments make online discussions difficult to moderate by human moderators only. Antisocial behavior is a common occurrence that often discourages other users from participating in discussion. We propose a neural network based method that partially automates the moderation process. It consists of two steps. First, we detect inappropriate comments for moderators to see. Second, we highlight inappropriate parts within these comments to make the moderation faster. We evaluated our method on data from a major Slovak news discussion platform.