 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Image-Text Matching and Retrieval by Grounding Entities
May 04, 2025

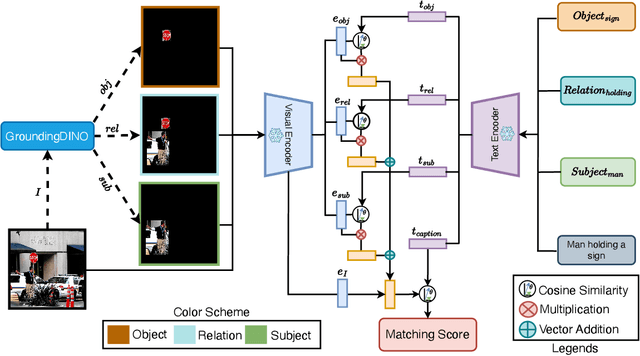
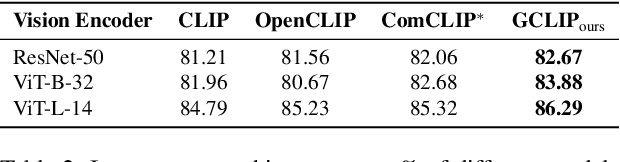
Vision-language pretraining on large datasets of images-text pairs is one of the main building blocks of current Vision-Language Models. While with additional training, these models excel in various downstream tasks, including visual question answering, image captioning, and visual commonsense reasoning. However, a notable weakness of pretrained models like CLIP, is their inability to perform entity grounding and compositional image and text matching~\cite{Jiang2024ComCLIP, yang2023amc, Rajabi2023GroundedVSR, learninglocalizeCVPR24}. In this work we propose a novel learning-free zero-shot augmentation of CLIP embeddings that has favorable compositional properties. We compute separate embeddings of sub-images of object entities and relations that are localized by the state of the art open vocabulary detectors and dynamically adjust the baseline global image embedding. % The final embedding is obtained by computing a weighted combination of the sub-image embeddings. The resulting embedding is then utilized for similarity computation with text embedding, resulting in a average 1.5\% improvement in image-text matching accuracy on the Visual Genome and SVO Probes datasets~\cite{krishna2017visualgenome, svo}. Notably, the enhanced embeddings demonstrate superior retrieval performance, thus achieving significant gains on the Flickr30K and MS-COCO retrieval benchmarks~\cite{flickr30ke, mscoco}, improving the state-of-the-art Recall@1 by 12\% and 0.4\%, respectively. Our code is available at https://github.com/madhukarreddyvongala/GroundingCLIP.
Gloss2Text: Sign Language Gloss translation using LLMs and Semantically Aware Label Smoothing
Jul 01, 2024



Sign language translation from video to spoken text presents unique challenges owing to the distinct grammar, expression nuances, and high variation of visual appearance across different speakers and contexts. The intermediate gloss annotations of videos aim to guide the translation process. In our work, we focus on {\em Gloss2Text} translation stage and propose several advances by leveraging pre-trained large language models (LLMs), data augmentation, and novel label-smoothing loss function exploiting gloss translation ambiguities improving significantly the performance of state-of-the-art approaches. Through extensive experiments and ablation studies on the PHOENIX Weather 2014T dataset, our approach surpasses state-of-the-art performance in {\em Gloss2Text} translation, indicating its efficacy in addressing sign language translation and suggesting promising avenues for future research and development.
Beyond Image-Text Matching: Verb Understanding in Multimodal Transformers Using Guided Masking
Jan 29, 2024The dominant probing approaches rely on the zero-shot performance of image-text matching tasks to gain a finer-grained understanding of the representations learned by recent multimodal image-language transformer models. The evaluation is carried out on carefully curated datasets focusing on counting, relations, attributes, and others. This work introduces an alternative probing strategy called guided masking. The proposed approach ablates different modalities using masking and assesses the model's ability to predict the masked word with high accuracy. We focus on studying multimodal models that consider regions of interest (ROI) features obtained by object detectors as input tokens. We probe the understanding of verbs using guided masking on ViLBERT, LXMERT, UNITER, and VisualBERT and show that these models can predict the correct verb with high accuracy. This contrasts with previous conclusions drawn from image-text matching probing techniques that frequently fail in situations requiring verb understanding. The code for all experiments will be publicly available https://github.com/ivana-13/guided_masking.
SLAW: Scaled Loss Approximate Weighting for Efficient Multi-Task Learning
Sep 16, 2021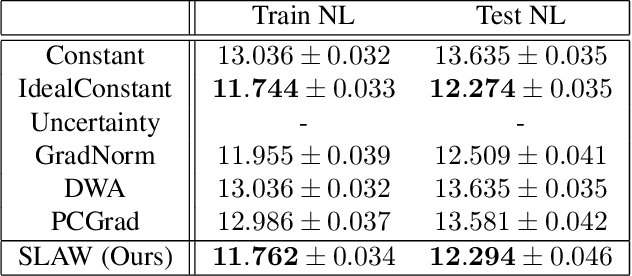
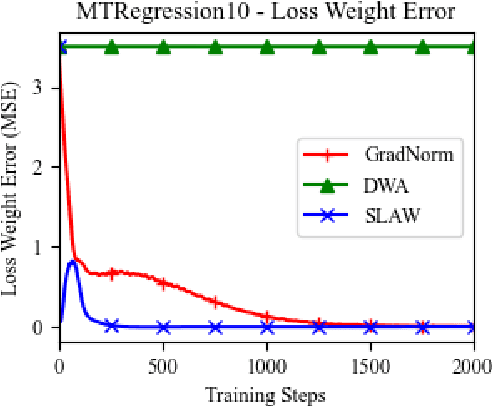

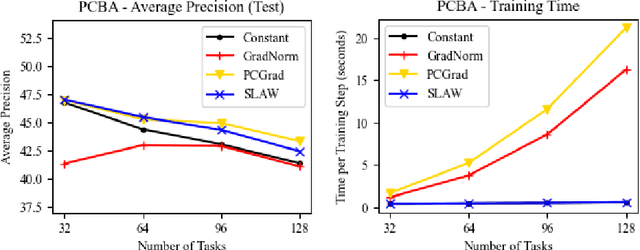
Multi-task learning (MTL) is a subfield of machine learning with important applications, but the multi-objective nature of optimization in MTL leads to difficulties in balancing training between tasks. The best MTL optimization methods require individually computing the gradient of each task's loss function, which impedes scalability to a large number of tasks. In this paper, we propose Scaled Loss Approximate Weighting (SLAW), a method for multi-task optimization that matches the performance of the best existing methods while being much more efficient. SLAW balances learning between tasks by estimating the magnitudes of each task's gradient without performing any extra backward passes. We provide theoretical and empirical justification for SLAW's estimation of gradient magnitudes. Experimental results on non-linear regression, multi-task computer vision, and virtual screening for drug discovery demonstrate that SLAW is significantly more efficient than strong baselines without sacrificing performance and applicable to a diverse range of domains.