 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Multilingual Encoder Language Model Compression for Low-Resource Languages
May 22, 2025In this paper, we combine two-step knowledge distillation, structured pruning, truncation, and vocabulary trimming for extremely compressing multilingual encoder-only language models for low-resource languages. Our novel approach systematically combines existing techniques and takes them to the extreme, reducing layer depth, feed-forward hidden size, and intermediate layer embedding size to create significantly smaller monolingual models while retaining essential language-specific knowledge. We achieve compression rates of up to 92% with only a marginal performance drop of 2-10% in four downstream tasks, including sentiment analysis, topic classification, named entity recognition, and part-of-speech tagging, across three low-resource languages. Notably, the performance degradation correlates with the amount of language-specific data in the teacher model, with larger datasets resulting in smaller performance losses. Additionally, we conduct extensive ablation studies to identify best practices for multilingual model compression using these techniques.
SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
May 15, 2025The rapid spread of online disinformation presents a global challenge, and machine learning has been widely explored as a potential solution. However, multilingual settings and low-resource languages are often neglected in this field. To address this gap, we conducted a shared task on multilingual claim retrieval at SemEval 2025, aimed at identifying fact-checked claims that match newly encountered claims expressed in social media posts across different languages. The task includes two subtracks: (1) a monolingual track, where social posts and claims are in the same language, and (2) a crosslingual track, where social posts and claims might be in different languages. A total of 179 participants registered for the task contributing to 52 test submissions. 23 out of 31 teams have submitted their system papers. In this paper, we report the best-performing systems as well as the most common and the most effective approaches across both subtracks. This shared task, along with its dataset and participating systems, provides valuable insights into multilingual claim retrieval and automated fact-checking, supporting future research in this field.
A Generative-AI-Driven Claim Retrieval System Capable of Detecting and Retrieving Claims from Social Media Platforms in Multiple Languages
Apr 29, 2025
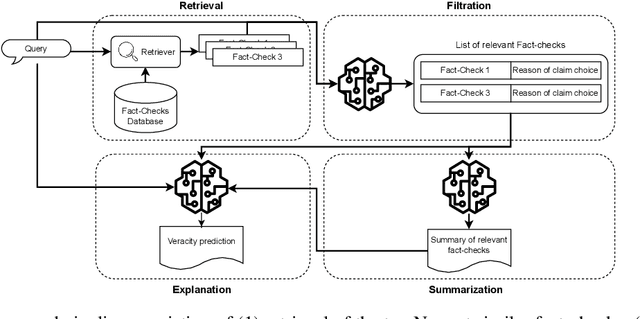

Online disinformation poses a global challenge, placing significant demands on fact-checkers who must verify claims efficiently to prevent the spread of false information. A major issue in this process is the redundant verification of already fact-checked claims, which increases workload and delays responses to newly emerging claims. This research introduces an approach that retrieves previously fact-checked claims, evaluates their relevance to a given input, and provides supplementary information to support fact-checkers. Our method employs large language models (LLMs) to filter irrelevant fact-checks and generate concise summaries and explanations, enabling fact-checkers to faster assess whether a claim has been verified before. In addition, we evaluate our approach through both automatic and human assessments, where humans interact with the developed tool to review its effectiveness. Our results demonstrate that LLMs are able to filter out many irrelevant fact-checks and, therefore, reduce effort and streamline the fact-checking process.
Large Language Models for Multilingual Previously Fact-Checked Claim Detection
Mar 04, 2025In our era of widespread false information, human fact-checkers often face the challenge of duplicating efforts when verifying claims that may have already been addressed in other countries or languages. As false information transcends linguistic boundaries, the ability to automatically detect previously fact-checked claims across languages has become an increasingly important task. This paper presents the first comprehensive evaluation of large language models (LLMs) for multilingual previously fact-checked claim detection. We assess seven LLMs across 20 languages in both monolingual and cross-lingual settings. Our results show that while LLMs perform well for high-resource languages, they struggle with low-resource languages. Moreover, translating original texts into English proved to be beneficial for low-resource languages. These findings highlight the potential of LLMs for multilingual previously fact-checked claim detection and provide a foundation for further research on this promising application of LLMs.
Overshoot: Taking advantage of future gradients in momentum-based stochastic optimization
Jan 16, 2025Overshoot is a novel, momentum-based stochastic gradient descent optimization method designed to enhance performance beyond standard and Nesterov's momentum. In conventional momentum methods, gradients from previous steps are aggregated with the gradient at current model weights before taking a step and updating the model. Rather than calculating gradient at the current model weights, Overshoot calculates the gradient at model weights shifted in the direction of the current momentum. This sacrifices the immediate benefit of using the gradient w.r.t. the exact model weights now, in favor of evaluating at a point, which will likely be more relevant for future updates. We show that incorporating this principle into momentum-based optimizers (SGD with momentum and Adam) results in faster convergence (saving on average at least 15% of steps). Overshoot consistently outperforms both standard and Nesterov's momentum across a wide range of tasks and integrates into popular momentum-based optimizers with zero memory and small computational overhead.
CV-Probes: Studying the interplay of lexical and world knowledge in visually grounded verb understanding
Sep 02, 2024This study investigates the ability of various vision-language (VL) models to ground context-dependent and non-context-dependent verb phrases. To do that, we introduce the CV-Probes dataset, designed explicitly for studying context understanding, containing image-caption pairs with context-dependent verbs (e.g., "beg") and non-context-dependent verbs (e.g., "sit"). We employ the MM-SHAP evaluation to assess the contribution of verb tokens towards model predictions. Our results indicate that VL models struggle to ground context-dependent verb phrases effectively. These findings highlight the challenges in training VL models to integrate context accurately, suggesting a need for improved methodologies in VL model training and evaluation.
Multilingual Models for Check-Worthy Social Media Posts Detection
Aug 13, 2024



This work presents an extensive study of transformer-based NLP models for detection of social media posts that contain verifiable factual claims and harmful claims. The study covers various activities, including dataset collection, dataset pre-processing, architecture selection, setup of settings, model training (fine-tuning), model testing, and implementation. The study includes a comprehensive analysis of different models, with a special focus on multilingual models where the same model is capable of processing social media posts in both English and in low-resource languages such as Arabic, Bulgarian, Dutch, Polish, Czech, Slovak. The results obtained from the study were validated against state-of-the-art models, and the comparison demonstrated the robustness of the proposed models. The novelty of this work lies in the development of multi-label multilingual classification models that can simultaneously detect harmful posts and posts that contain verifiable factual claims in an efficient way.
Beyond Image-Text Matching: Verb Understanding in Multimodal Transformers Using Guided Masking
Jan 29, 2024The dominant probing approaches rely on the zero-shot performance of image-text matching tasks to gain a finer-grained understanding of the representations learned by recent multimodal image-language transformer models. The evaluation is carried out on carefully curated datasets focusing on counting, relations, attributes, and others. This work introduces an alternative probing strategy called guided masking. The proposed approach ablates different modalities using masking and assesses the model's ability to predict the masked word with high accuracy. We focus on studying multimodal models that consider regions of interest (ROI) features obtained by object detectors as input tokens. We probe the understanding of verbs using guided masking on ViLBERT, LXMERT, UNITER, and VisualBERT and show that these models can predict the correct verb with high accuracy. This contrasts with previous conclusions drawn from image-text matching probing techniques that frequently fail in situations requiring verb understanding. The code for all experiments will be publicly available https://github.com/ivana-13/guided_masking.
Using LLVM-based JIT Compilation in Genetic Programming
Jan 20, 2017


The paper describes an approach to implementing genetic programming, which uses the LLVM library to just-in-time compile/interpret the evolved abstract syntax trees. The solution is described in some detail, including a parser (based on FlexC++ and BisonC++) that can construct the trees from a simple toy language with C-like syntax. The approach is compared with a previous implementation (based on direct execution of trees using polymorphic functors) in terms of execution speed.
Fitness-based Adaptive Control of Parameters in Genetic Programming: Adaptive Value Setting of Mutation Rate and Flood Mechanisms
May 05, 2016


This paper concerns applications of genetic algorithms and genetic programming to tasks for which it is difficult to find a representation that does not map to a highly complex and discontinuous fitness landscape. In such cases the standard algorithm is prone to getting trapped in local extremes. The paper proposes several adaptive mechanisms that are useful in preventing the search from getting trapped.