 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Models for Check-Worthy Social Media Posts Detection
Aug 13, 2024



This work presents an extensive study of transformer-based NLP models for detection of social media posts that contain verifiable factual claims and harmful claims. The study covers various activities, including dataset collection, dataset pre-processing, architecture selection, setup of settings, model training (fine-tuning), model testing, and implementation. The study includes a comprehensive analysis of different models, with a special focus on multilingual models where the same model is capable of processing social media posts in both English and in low-resource languages such as Arabic, Bulgarian, Dutch, Polish, Czech, Slovak. The results obtained from the study were validated against state-of-the-art models, and the comparison demonstrated the robustness of the proposed models. The novelty of this work lies in the development of multi-label multilingual classification models that can simultaneously detect harmful posts and posts that contain verifiable factual claims in an efficient way.
Is it indeed bigger better? The comprehensive study of claim detection LMs applied for disinformation tackling
Nov 10, 2023
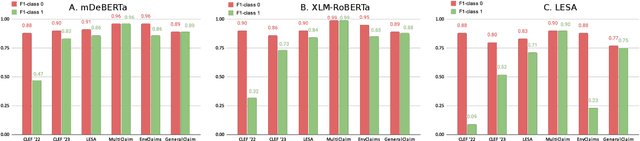
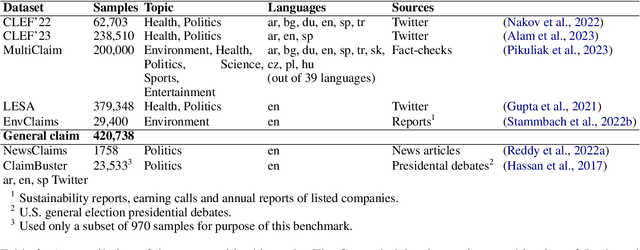
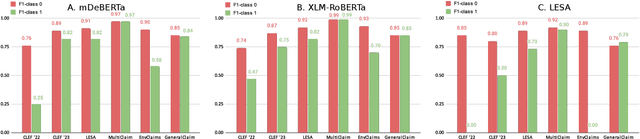
This study compares the performance of (1) fine-tuned models and (2) extremely large language models on the task of check-worthy claim detection. For the purpose of the comparison we composed a multilingual and multi-topical dataset comprising texts of various sources and styles. Building on this, we performed a benchmark analysis to determine the most general multilingual and multi-topical claim detector. We chose three state-of-the-art models in the check-worthy claim detection task and fine-tuned them. Furthermore, we selected three state-of-the-art extremely large language models without any fine-tuning. We made modifications to the models to adapt them for multilingual settings and through extensive experimentation and evaluation. We assessed the performance of all the models in terms of accuracy, recall, and F1-score in in-domain and cross-domain scenarios. Our results demonstrate that despite the technological progress in the area of natural language processing, the models fine-tuned for the task of check-worthy claim detection still outperform the zero-shot approaches in a cross-domain settings.