 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs it indeed bigger better? The comprehensive study of claim detection LMs applied for disinformation tackling
Paper and Code
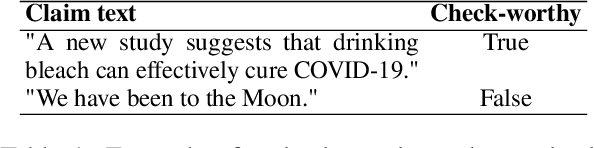
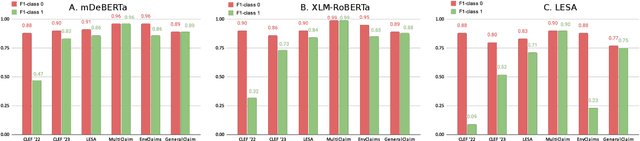
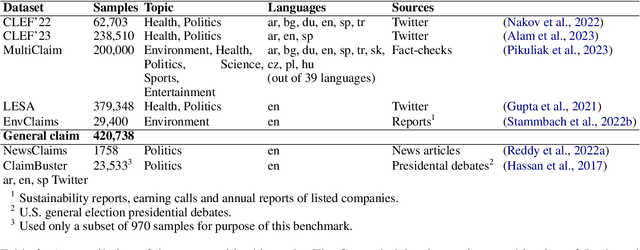
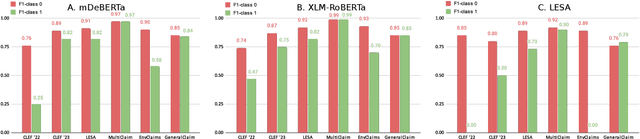
This study compares the performance of (1) fine-tuned models and (2) extremely large language models on the task of check-worthy claim detection. For the purpose of the comparison we composed a multilingual and multi-topical dataset comprising texts of various sources and styles. Building on this, we performed a benchmark analysis to determine the most general multilingual and multi-topical claim detector. We chose three state-of-the-art models in the check-worthy claim detection task and fine-tuned them. Furthermore, we selected three state-of-the-art extremely large language models without any fine-tuning. We made modifications to the models to adapt them for multilingual settings and through extensive experimentation and evaluation. We assessed the performance of all the models in terms of accuracy, recall, and F1-score in in-domain and cross-domain scenarios. Our results demonstrate that despite the technological progress in the area of natural language processing, the models fine-tuned for the task of check-worthy claim detection still outperform the zero-shot approaches in a cross-domain settings.