 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeskLEP: A Slovak General Language Understanding Benchmark
Jun 26, 2025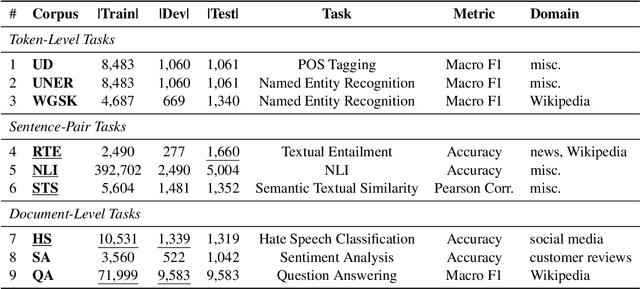

In this work, we introduce skLEP, the first comprehensive benchmark specifically designed for evaluating Slovak natural language understanding (NLU) models. We have compiled skLEP to encompass nine diverse tasks that span token-level, sentence-pair, and document-level challenges, thereby offering a thorough assessment of model capabilities. To create this benchmark, we curated new, original datasets tailored for Slovak and meticulously translated established English NLU resources. Within this paper, we also present the first systematic and extensive evaluation of a wide array of Slovak-specific, multilingual, and English pre-trained language models using the skLEP tasks. Finally, we also release the complete benchmark data, an open-source toolkit facilitating both fine-tuning and evaluation of models, and a public leaderboard at https://github.com/slovak-nlp/sklep in the hopes of fostering reproducibility and drive future research in Slovak NLU.
AI Research is not Magic, it has to be Reproducible and Responsible: Challenges in the AI field from the Perspective of its PhD Students
Aug 13, 2024With the goal of uncovering the challenges faced by European AI students during their research endeavors, we surveyed 28 AI doctoral candidates from 13 European countries. The outcomes underscore challenges in three key areas: (1) the findability and quality of AI resources such as datasets, models, and experiments; (2) the difficulties in replicating the experiments in AI papers; (3) and the lack of trustworthiness and interdisciplinarity. From our findings, it appears that although early stage AI researchers generally tend to share their AI resources, they lack motivation or knowledge to engage more in dataset and code preparation and curation, and ethical assessments, and are not used to cooperate with well-versed experts in application domains. Furthermore, we examine existing practices in data governance and reproducibility both in computer science and in artificial intelligence. For instance, only a minority of venues actively promote reproducibility initiatives such as reproducibility evaluations. Critically, there is need for immediate adoption of responsible and reproducible AI research practices, crucial for society at large, and essential for the AI research community in particular. This paper proposes a combination of social and technical recommendations to overcome the identified challenges. Socially, we propose the general adoption of reproducibility initiatives in AI conferences and journals, as well as improved interdisciplinary collaboration, especially in data governance practices. On the technical front, we call for enhanced tools to better support versioning control of datasets and code, and a computing infrastructure that facilitates the sharing and discovery of AI resources, as well as the sharing, execution, and verification of experiments.
Beyond Image-Text Matching: Verb Understanding in Multimodal Transformers Using Guided Masking
Jan 29, 2024The dominant probing approaches rely on the zero-shot performance of image-text matching tasks to gain a finer-grained understanding of the representations learned by recent multimodal image-language transformer models. The evaluation is carried out on carefully curated datasets focusing on counting, relations, attributes, and others. This work introduces an alternative probing strategy called guided masking. The proposed approach ablates different modalities using masking and assesses the model's ability to predict the masked word with high accuracy. We focus on studying multimodal models that consider regions of interest (ROI) features obtained by object detectors as input tokens. We probe the understanding of verbs using guided masking on ViLBERT, LXMERT, UNITER, and VisualBERT and show that these models can predict the correct verb with high accuracy. This contrasts with previous conclusions drawn from image-text matching probing techniques that frequently fail in situations requiring verb understanding. The code for all experiments will be publicly available https://github.com/ivana-13/guided_masking.
SlovakBERT: Slovak Masked Language Model
Sep 30, 2021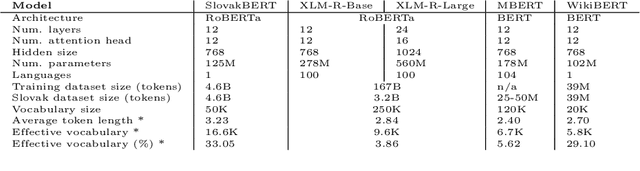
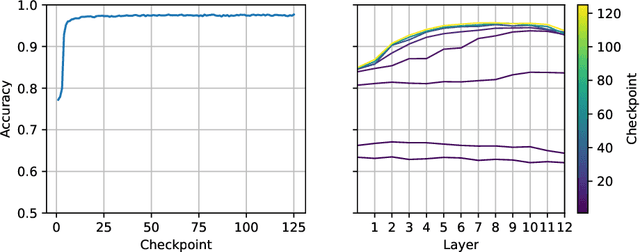

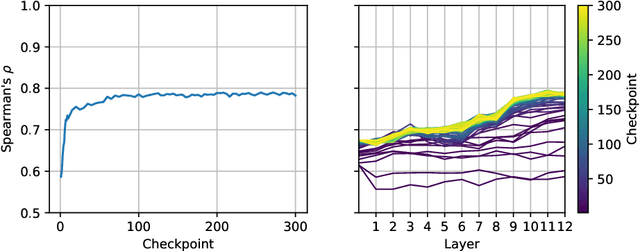
We introduce a new Slovak masked language model called SlovakBERT in this paper. It is the first Slovak-only transformers-based model trained on a sizeable corpus. We evaluate the model on several NLP tasks and achieve state-of-the-art results. We publish the masked language model, as well as the subsequently fine-tuned models for part-of-speech tagging, sentiment analysis and semantic textual similarity.