 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Depth Look at Word Filling Societal Bias Measures
Feb 24, 2023Many measures of societal bias in language models have been proposed in recent years. A popular approach is to use a set of word filling prompts to evaluate the behavior of the language models. In this work, we analyze the validity of two such measures -- StereoSet and CrowS-Pairs. We show that these measures produce unexpected and illogical results when appropriate control group samples are constructed. Based on this, we believe that they are problematic and using them in the future should be reconsidered. We propose a way forward with an improved testing protocol. Finally, we also introduce a new gender bias dataset for Slovak.
SlovakBERT: Slovak Masked Language Model
Sep 30, 2021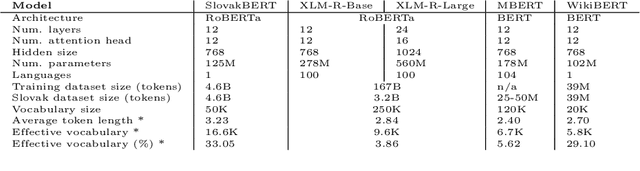
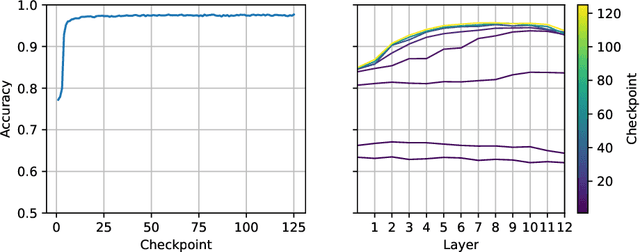

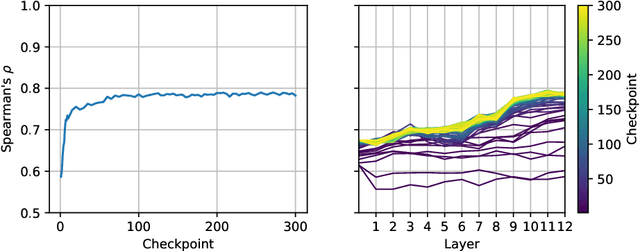
We introduce a new Slovak masked language model called SlovakBERT in this paper. It is the first Slovak-only transformers-based model trained on a sizeable corpus. We evaluate the model on several NLP tasks and achieve state-of-the-art results. We publish the masked language model, as well as the subsequently fine-tuned models for part-of-speech tagging, sentiment analysis and semantic textual similarity.