 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Research is not Magic, it has to be Reproducible and Responsible: Challenges in the AI field from the Perspective of its PhD Students
Aug 13, 2024With the goal of uncovering the challenges faced by European AI students during their research endeavors, we surveyed 28 AI doctoral candidates from 13 European countries. The outcomes underscore challenges in three key areas: (1) the findability and quality of AI resources such as datasets, models, and experiments; (2) the difficulties in replicating the experiments in AI papers; (3) and the lack of trustworthiness and interdisciplinarity. From our findings, it appears that although early stage AI researchers generally tend to share their AI resources, they lack motivation or knowledge to engage more in dataset and code preparation and curation, and ethical assessments, and are not used to cooperate with well-versed experts in application domains. Furthermore, we examine existing practices in data governance and reproducibility both in computer science and in artificial intelligence. For instance, only a minority of venues actively promote reproducibility initiatives such as reproducibility evaluations. Critically, there is need for immediate adoption of responsible and reproducible AI research practices, crucial for society at large, and essential for the AI research community in particular. This paper proposes a combination of social and technical recommendations to overcome the identified challenges. Socially, we propose the general adoption of reproducibility initiatives in AI conferences and journals, as well as improved interdisciplinary collaboration, especially in data governance practices. On the technical front, we call for enhanced tools to better support versioning control of datasets and code, and a computing infrastructure that facilitates the sharing and discovery of AI resources, as well as the sharing, execution, and verification of experiments.
Women Are Beautiful, Men Are Leaders: Gender Stereotypes in Machine Translation and Language Modeling
Nov 30, 2023



We present GEST -- a new dataset for measuring gender-stereotypical reasoning in masked LMs and English-to-X machine translation systems. GEST contains samples that are compatible with 9 Slavic languages and English for 16 gender stereotypes about men and women (e.g., Women are beautiful, Men are leaders). The definition of said stereotypes was informed by gender experts. We used GEST to evaluate 11 masked LMs and 4 machine translation systems. We discovered significant and consistent amounts of stereotypical reasoning in almost all the evaluated models and languages.
Automated, not Automatic: Needs and Practices in European Fact-checking Organizations as a basis for Designing Human-centered AI Systems
Nov 22, 2022



To mitigate the negative effects of false information more effectively, the development of automated AI (artificial intelligence) tools assisting fact-checkers is needed. Despite the existing research, there is still a gap between the fact-checking practitioners' needs and pains and the current AI research. We aspire to bridge this gap by employing methods of information behavior research to identify implications for designing better human-centered AI-based supporting tools. In this study, we conducted semi-structured in-depth interviews with Central European fact-checkers. The information behavior and requirements on desired supporting tools were analyzed using iterative bottom-up content analysis, bringing the techniques from grounded theory. The most significant needs were validated with a survey extended to fact-checkers from across Europe, in which we collected 24 responses from 20 European countries, i.e., 62% active European IFCN (International Fact-Checking Network) signatories. Our contributions are theoretical as well as practical. First, by being able to map our findings about the needs of fact-checking organizations to the relevant tasks for AI research, we have shown that the methods of information behavior research are relevant for studying the processes in the organizations and that these methods can be used to bridge the gap between the users and AI researchers. Second, we have identified fact-checkers' needs and pains focusing on so far unexplored dimensions and emphasizing the needs of fact-checkers from Central and Eastern Europe as well as from low-resource language groups which have implications for development of new resources (datasets) as well as for the focus of AI research in this domain.
Auditing YouTube's Recommendation Algorithm for Misinformation Filter Bubbles
Oct 18, 2022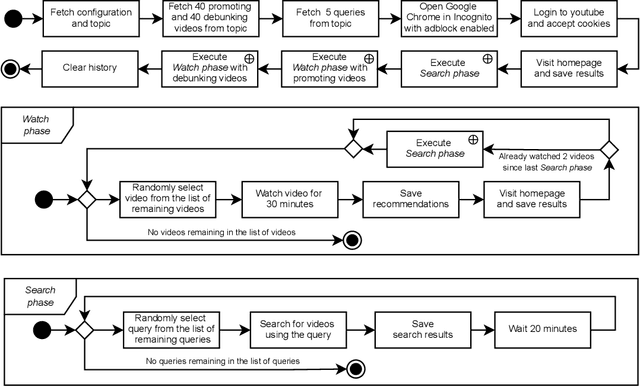
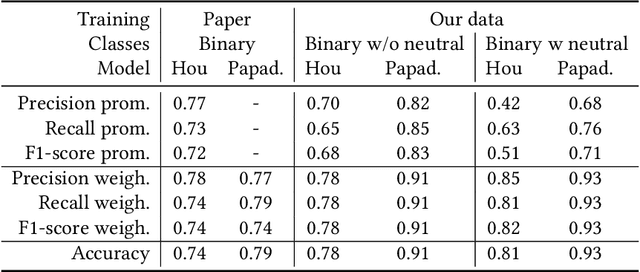
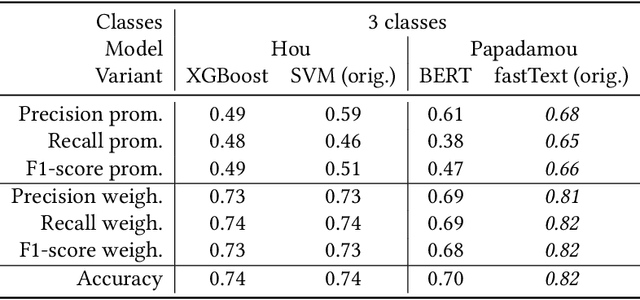
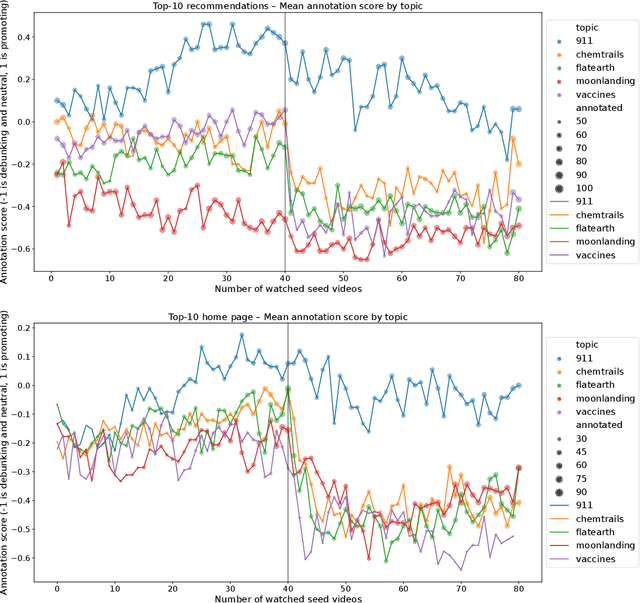
In this paper, we present results of an auditing study performed over YouTube aimed at investigating how fast a user can get into a misinformation filter bubble, but also what it takes to "burst the bubble", i.e., revert the bubble enclosure. We employ a sock puppet audit methodology, in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content. Then they try to burst the bubbles and reach more balanced recommendations by watching misinformation debunking content. We record search results, home page results, and recommendations for the watched videos. Overall, we recorded 17,405 unique videos, out of which we manually annotated 2,914 for the presence of misinformation. The labeled data was used to train a machine learning model classifying videos into three classes (promoting, debunking, neutral) with the accuracy of 0.82. We use the trained model to classify the remaining videos that would not be feasible to annotate manually. Using both the manually and automatically annotated data, we observe the misinformation bubble dynamics for a range of audited topics. Our key finding is that even though filter bubbles do not appear in some situations, when they do, it is possible to burst them by watching misinformation debunking content (albeit it manifests differently from topic to topic). We also observe a sudden decrease of misinformation filter bubble effect when misinformation debunking videos are watched after misinformation promoting videos, suggesting a strong contextuality of recommendations. Finally, when comparing our results with a previous similar study, we do not observe significant improvements in the overall quantity of recommended misinformation content.
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022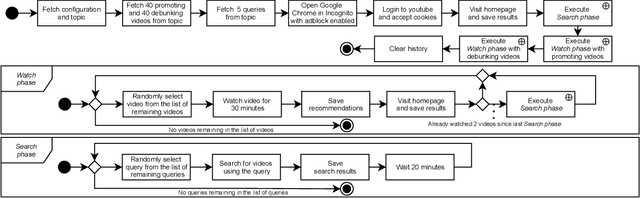


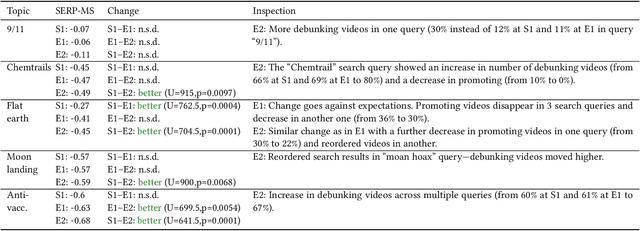
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System