 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware adaptive personalised recommendation: a meta-hybrid
Oct 17, 2024



Recommenders take place on a wide scale of e-commerce systems, reducing the problem of information overload. The most common approach is to choose a recommender used by the system to make predictions. However, users vary from each other; thus, a one-fits-all approach seems to be sub-optimal. In this paper, we propose a meta-hybrid recommender that uses machine learning to predict an optimal algorithm. In this way, the best-performing recommender is used for each specific session and user. This selection depends on contextual and preferential information collected about the user. We use standard MovieLens and The Movie DB datasets for offline evaluation. We show that based on the proposed model, it is possible to predict which recommender will provide the most precise recommendations to a user. The theoretical performance of our meta-hybrid outperforms separate approaches by 20-50% in normalized Discounted Gain and Root Mean Square Error metrics. However, it is hard to obtain the optimal performance based on widely-used standard information stored about users.
Cross-Validated Off-Policy Evaluation
May 27, 2024In this paper, we study the problem of estimator selection and hyper-parameter tuning in off-policy evaluation. Although cross-validation is the most popular method for model selection in supervised learning, off-policy evaluation relies mostly on theory-based approaches, which provide only limited guidance to practitioners. We show how to use cross-validation for off-policy evaluation. This challenges a popular belief that cross-validation in off-policy evaluation is not feasible. We evaluate our method empirically and show that it addresses a variety of use cases.
Auditing YouTube's Recommendation Algorithm for Misinformation Filter Bubbles
Oct 18, 2022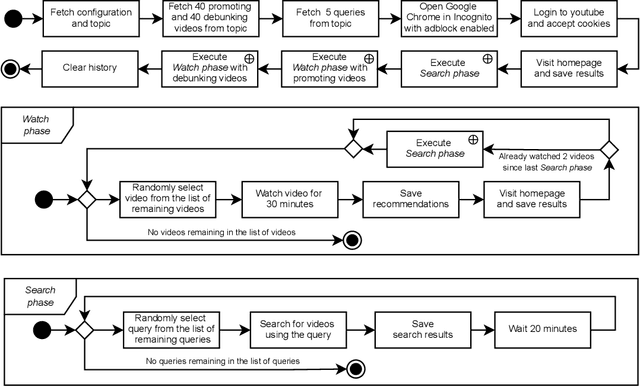
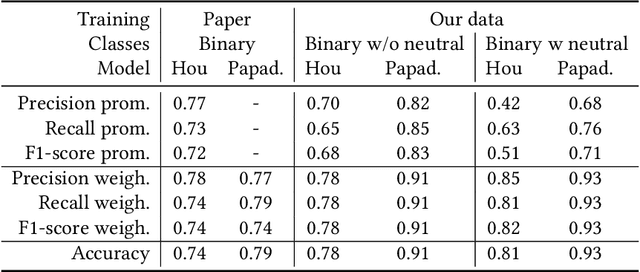
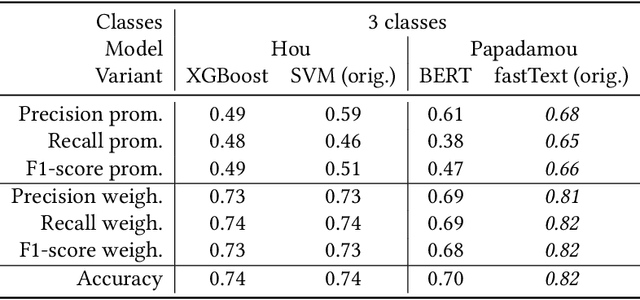
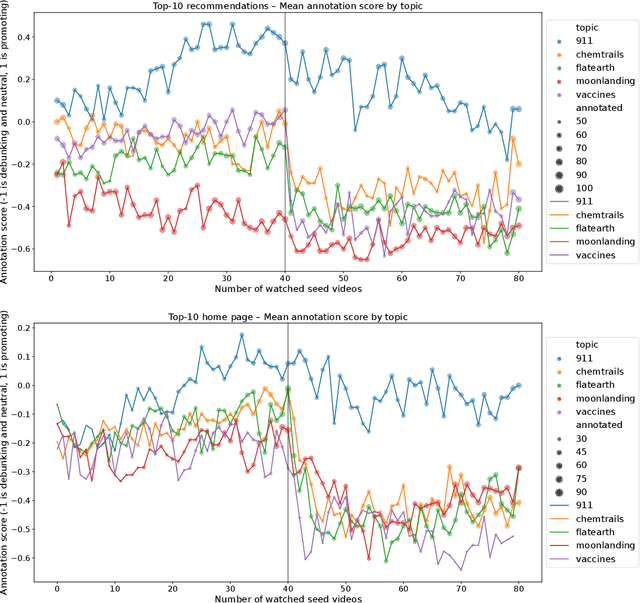
In this paper, we present results of an auditing study performed over YouTube aimed at investigating how fast a user can get into a misinformation filter bubble, but also what it takes to "burst the bubble", i.e., revert the bubble enclosure. We employ a sock puppet audit methodology, in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content. Then they try to burst the bubbles and reach more balanced recommendations by watching misinformation debunking content. We record search results, home page results, and recommendations for the watched videos. Overall, we recorded 17,405 unique videos, out of which we manually annotated 2,914 for the presence of misinformation. The labeled data was used to train a machine learning model classifying videos into three classes (promoting, debunking, neutral) with the accuracy of 0.82. We use the trained model to classify the remaining videos that would not be feasible to annotate manually. Using both the manually and automatically annotated data, we observe the misinformation bubble dynamics for a range of audited topics. Our key finding is that even though filter bubbles do not appear in some situations, when they do, it is possible to burst them by watching misinformation debunking content (albeit it manifests differently from topic to topic). We also observe a sudden decrease of misinformation filter bubble effect when misinformation debunking videos are watched after misinformation promoting videos, suggesting a strong contextuality of recommendations. Finally, when comparing our results with a previous similar study, we do not observe significant improvements in the overall quantity of recommended misinformation content.
Pessimistic Off-Policy Optimization for Learning to Rank
Jun 06, 2022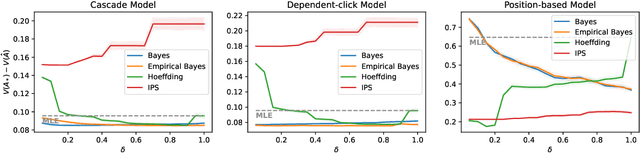
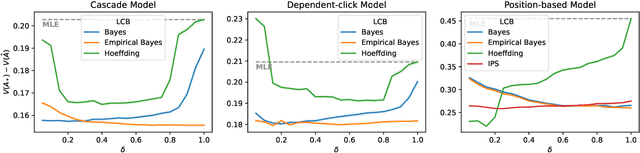
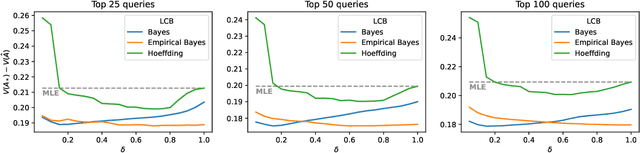
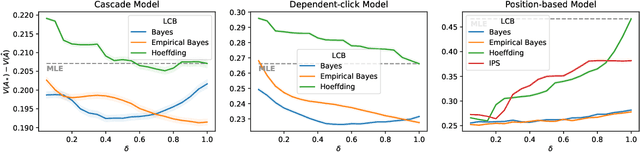
Off-policy learning is a framework for optimizing policies without deploying them, using data collected by another policy. In recommender systems, this is especially challenging due to the imbalance in logged data: some items are recommended and thus logged much more frequently than others. This is further perpetuated when recommending a list of items, as the action space is combinatorial. To address this challenge, we study pessimistic off-policy optimization for learning to rank. The key idea is to compute lower confidence bounds on parameters of click models and then return the list with the highest pessimistic estimate of its value. This approach is computationally efficient and we analyze it. We study its Bayesian and frequentist variants, and overcome the limitation of unknown prior by incorporating empirical Bayes. To show the empirical effectiveness of our approach, we compare it to off-policy optimizers that use inverse propensity scores or neglect uncertainty. Our approach outperforms all baselines, is robust, and is also general.
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022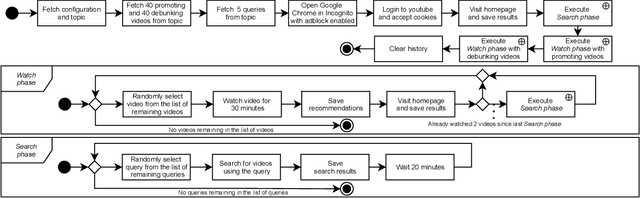


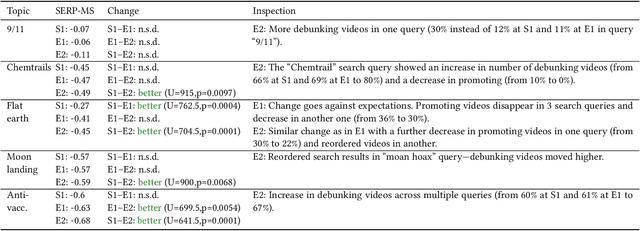
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System
Exploring Customer Price Preference and Product Profit Role in Recommender Systems
Mar 13, 2022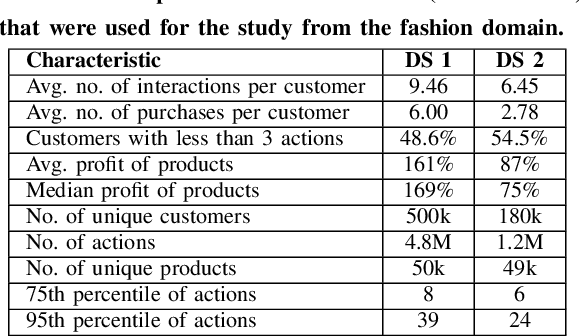
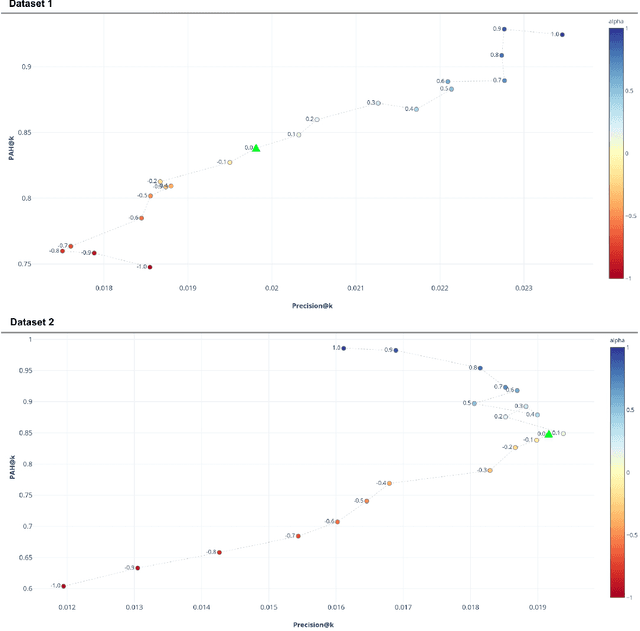
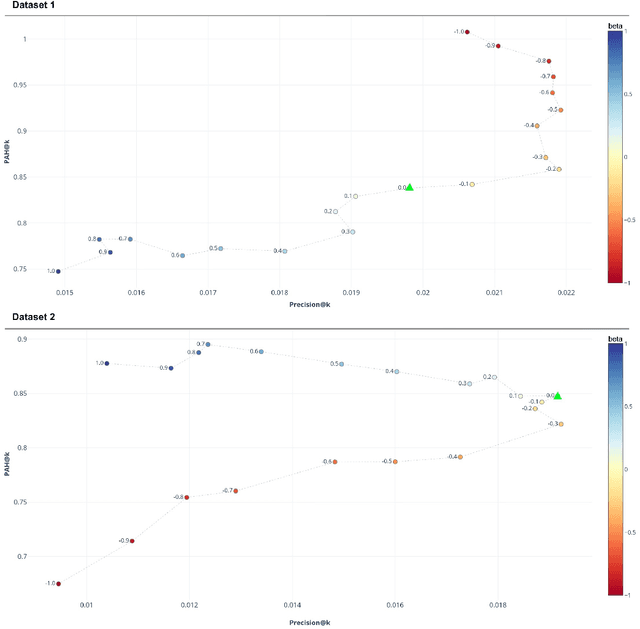
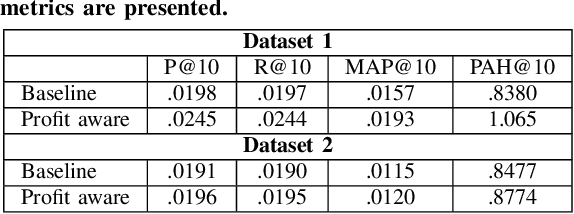
Most of the research in the recommender systems domain is focused on the optimization of the metrics based on historical data such as Mean Average Precision (MAP) or Recall. However, there is a gap between the research and industry since the leading Key Performance Indicators (KPIs) for businesses are revenue and profit. In this paper, we explore the impact of manipulating the profit awareness of a recommender system. An average e-commerce business does not usually use a complicated recommender algorithm. We propose an adjustment of a predicted ranking for score-based recommender systems and explore the effect of the profit and customers' price preferences on two industry datasets from the fashion domain. In the experiments, we show the ability to improve both the precision and the generated recommendations' profit. Such an outcome represents a win-win situation when e-commerce increases the profit and customers get more valuable recommendations.
The Cold-start Problem: Minimal Users' Activity Estimation
May 31, 2021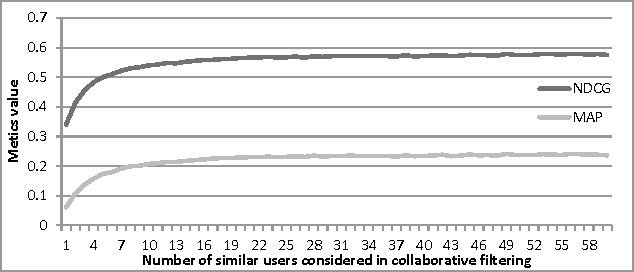

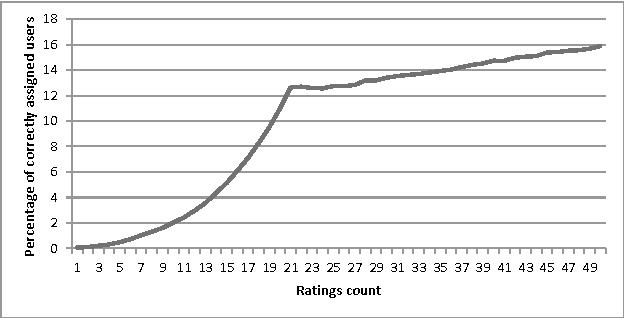
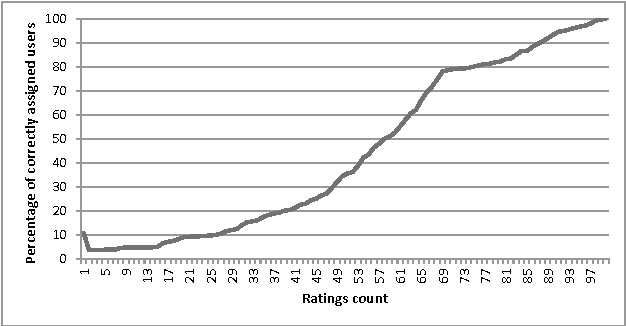
Cold-start problem, which arises upon the new users arrival, is one of the fundamental problems in today's recommender approaches. Moreover, in some domains as TV or multime-dia-items take long time to experience by users, thus users usually do not provide rich preference information. In this paper we analyze the minimal amount of ratings needs to be done by a user over a set of items, in order to solve or reduce the cold-start problem. In our analysis we applied clustering data mining technique in order to identify minimal amount of item's ratings required from recommender system's users, in order to be assigned to a correct cluster. In this context, cluster quality is being monitored and in case of reaching certain cluster quality threshold, the rec-ommender system could start to generate recommendations for given user, as in this point cold-start problem is considered as resolved. Our proposed approach is applicable to any domain in which user preferences are received based on explicit items rating. Our experiments are performed within the movie and jokes recommendation domain using the MovieLens and Jester dataset.