 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning
May 21, 2025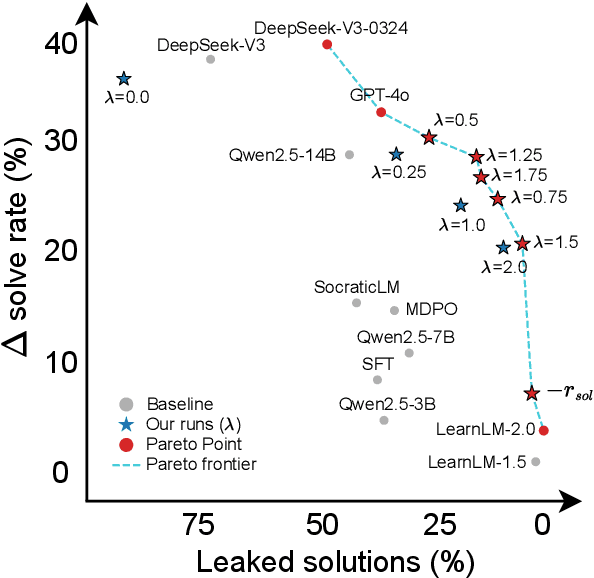
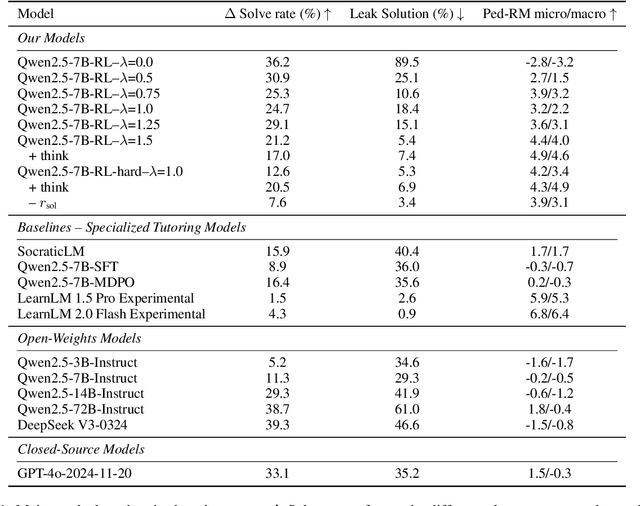
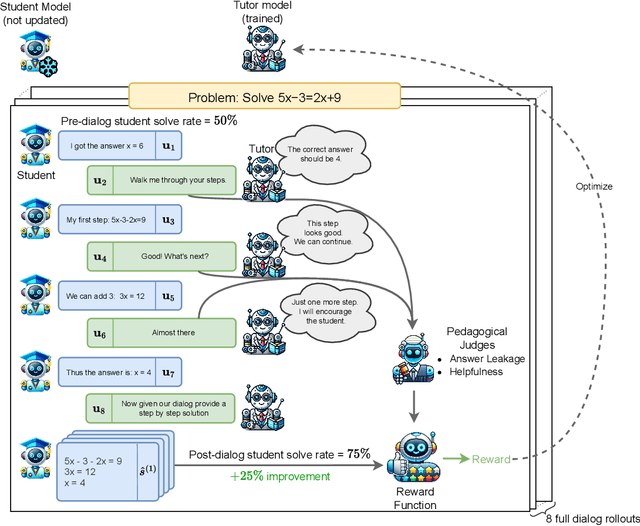
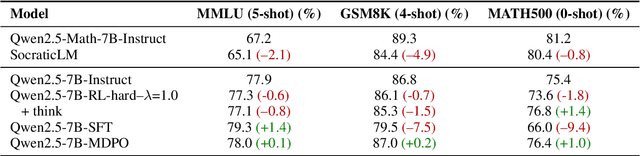
Large language models (LLMs) can transform education, but their optimization for direct question-answering often undermines effective pedagogy which requires strategically withholding answers. To mitigate this, we propose an online reinforcement learning (RL)-based alignment framework that can quickly adapt LLMs into effective tutors using simulated student-tutor interactions by emphasizing pedagogical quality and guided problem-solving over simply giving away answers. We use our method to train a 7B parameter tutor model without human annotations which reaches similar performance to larger proprietary models like LearnLM. We introduce a controllable reward weighting to balance pedagogical support and student solving accuracy, allowing us to trace the Pareto frontier between these two objectives. Our models better preserve reasoning capabilities than single-turn SFT baselines and can optionally enhance interpretability through thinking tags that expose the model's instructional planning.
MathTutorBench: A Benchmark for Measuring Open-ended Pedagogical Capabilities of LLM Tutors
Feb 26, 2025Evaluating the pedagogical capabilities of AI-based tutoring models is critical for making guided progress in the field. Yet, we lack a reliable, easy-to-use, and simple-to-run evaluation that reflects the pedagogical abilities of models. To fill this gap, we present MathTutorBench, an open-source benchmark for holistic tutoring model evaluation. MathTutorBench contains a collection of datasets and metrics that broadly cover tutor abilities as defined by learning sciences research in dialog-based teaching. To score the pedagogical quality of open-ended teacher responses, we train a reward model and show it can discriminate expert from novice teacher responses with high accuracy. We evaluate a wide set of closed- and open-weight models on MathTutorBench and find that subject expertise, indicated by solving ability, does not immediately translate to good teaching. Rather, pedagogy and subject expertise appear to form a trade-off that is navigated by the degree of tutoring specialization of the model. Furthermore, tutoring appears to become more challenging in longer dialogs, where simpler questioning strategies begin to fail. We release the benchmark, code, and leaderboard openly to enable rapid benchmarking of future models.
Towards the Pedagogical Steering of Large Language Models for Tutoring: A Case Study with Modeling Productive Failure
Oct 03, 2024



One-to-one tutoring is one of the most efficient methods of teaching. Following the rise in popularity of Large Language Models (LLMs), there have been efforts to use them to create conversational tutoring systems, which can make the benefits of one-to-one tutoring accessible to everyone. However, current LLMs are primarily trained to be helpful assistants and thus lack crucial pedagogical skills. For example, they often quickly reveal the solution to the student and fail to plan for a richer multi-turn pedagogical interaction. To use LLMs in pedagogical scenarios, they need to be steered towards using effective teaching strategies: a problem we introduce as Pedagogical Steering and believe to be crucial for the efficient use of LLMs as tutors. We address this problem by formalizing a concept of tutoring strategy, and introducing StratL, an algorithm to model a strategy and use prompting to steer the LLM to follow this strategy. As a case study, we create a prototype tutor for high school math following Productive Failure (PF), an advanced and effective learning design. To validate our approach in a real-world setting, we run a field study with 17 high school students in Singapore. We quantitatively show that StratL succeeds in steering the LLM to follow a Productive Failure tutoring strategy. We also thoroughly investigate the existence of spillover effects on desirable properties of the LLM, like its ability to generate human-like answers. Based on these results, we highlight the challenges in Pedagogical Steering and suggest opportunities for further improvements. We further encourage follow-up research by releasing a dataset of Productive Failure problems and the code of our prototype and algorithm.
Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
Jul 12, 2024Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.
Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots
Mar 05, 2024



Educational chatbots are a promising tool for assisting student learning. However, the development of effective chatbots in education has been challenging, as high-quality data is seldom available in this domain. In this paper, we propose a framework for generating synthetic teacher-student interactions grounded in a set of textbooks. Our approaches capture one aspect of learning interactions where curious students with partial knowledge interactively ask a teacher questions about the material in the textbook. We highlight various quality criteria that such dialogues should fulfill and compare several approaches relying on either prompting or fine-tuning large language models. We use synthetic dialogues to train educational chatbots and show benefits of further fine-tuning in different educational domains. However, human evaluation shows that our best data synthesis method still suffers from hallucinations and tends to reiterate information from previous conversations. Our findings offer insights for future efforts in synthesizing conversational data that strikes a balance between size and quality. We will open-source our data and code.
MathDial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems
May 23, 2023

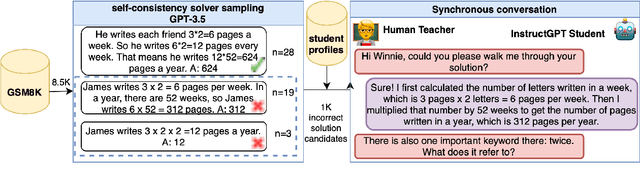

Although automatic dialogue tutors hold great potential in making education personalized and more accessible, research on such systems has been hampered by a lack of sufficiently large and high-quality datasets. However, collecting such datasets remains challenging, as recording tutoring sessions raises privacy concerns and crowdsourcing leads to insufficient data quality. To address this problem, we propose a framework to semi-synthetically generate such dialogues by pairing real teachers with a large language model (LLM) scaffolded to represent common student errors. In this paper, we describe our ongoing efforts to use this framework to collect MathDial, a dataset of currently ca. 1.5k tutoring dialogues grounded in multi-step math word problems. We show that our dataset exhibits rich pedagogical properties, focusing on guiding students using sense-making questions to let them explore problems. Moreover, we outline that MathDial and its grounding annotations can be used to finetune language models to be more effective tutors (and not just solvers) and highlight remaining challenges that need to be addressed by the research community. We will release our dataset publicly to foster research in this socially important area of NLP.
Opportunities and Challenges in Neural Dialog Tutoring
Jan 24, 2023
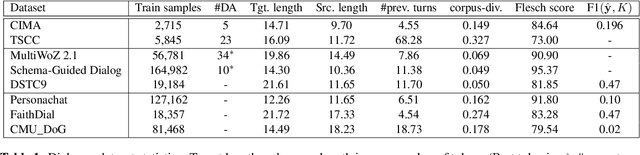


Designing dialog tutors has been challenging as it involves modeling the diverse and complex pedagogical strategies employed by human tutors. Although there have been significant recent advances in neural conversational systems using large language models and growth in available dialog corpora, dialog tutoring has largely remained unaffected by these advances. In this paper, we rigorously analyze various generative language models on two dialog tutoring datasets for language learning using automatic and human evaluations to understand the new opportunities brought by these advances as well as the challenges we must overcome to build models that would be usable in real educational settings. We find that although current approaches can model tutoring in constrained learning scenarios when the number of concepts to be taught and possible teacher strategies are small, they perform poorly in less constrained scenarios. Our human quality evaluation shows that both models and ground-truth annotations exhibit low performance in terms of equitable tutoring, which measures learning opportunities for students and how engaging the dialog is. To understand the behavior of our models in a real tutoring setting, we conduct a user study using expert annotators and find a significantly large number of model reasoning errors in 45% of conversations. Finally, we connect our findings to outline future work.
Automatic Generation of Socratic Subquestions for Teaching Math Word Problems
Nov 23, 2022



Socratic questioning is an educational method that allows students to discover answers to complex problems by asking them a series of thoughtful questions. Generation of didactically sound questions is challenging, requiring understanding of the reasoning process involved in the problem. We hypothesize that such questioning strategy can not only enhance the human performance, but also assist the math word problem (MWP) solvers. In this work, we explore the ability of large language models (LMs) in generating sequential questions for guiding math word problem-solving. We propose various guided question generation schemes based on input conditioning and reinforcement learning. On both automatic and human quality evaluations, we find that LMs constrained with desirable question properties generate superior questions and improve the overall performance of a math word problem solver. We conduct a preliminary user study to examine the potential value of such question generation models in the education domain. Results suggest that the difficulty level of problems plays an important role in determining whether questioning improves or hinders human performance. We discuss the future of using such questioning strategies in education.
Exploring Customer Price Preference and Product Profit Role in Recommender Systems
Mar 13, 2022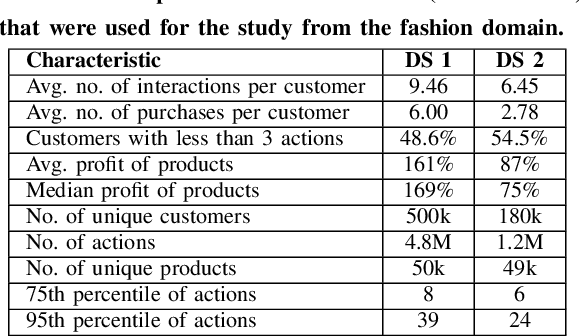
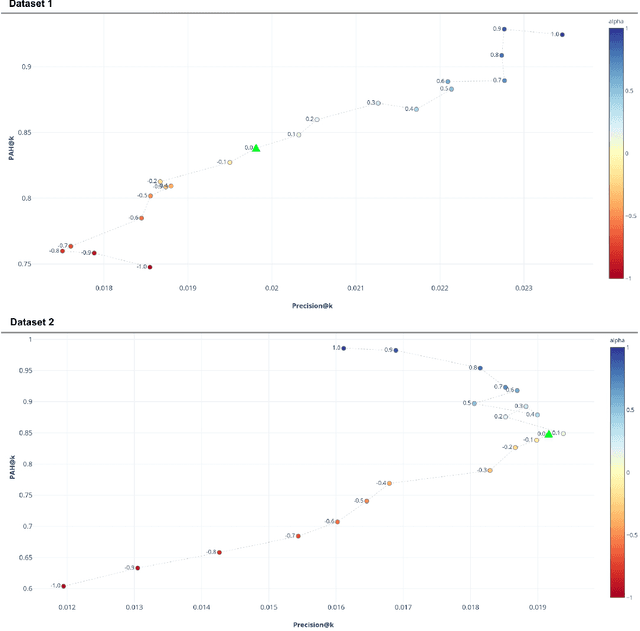
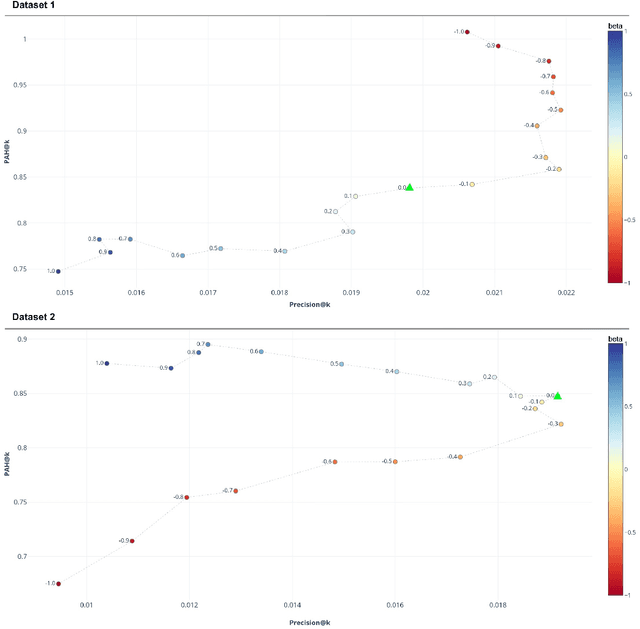
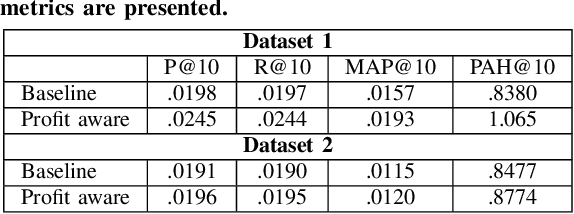
Most of the research in the recommender systems domain is focused on the optimization of the metrics based on historical data such as Mean Average Precision (MAP) or Recall. However, there is a gap between the research and industry since the leading Key Performance Indicators (KPIs) for businesses are revenue and profit. In this paper, we explore the impact of manipulating the profit awareness of a recommender system. An average e-commerce business does not usually use a complicated recommender algorithm. We propose an adjustment of a predicted ranking for score-based recommender systems and explore the effect of the profit and customers' price preferences on two industry datasets from the fashion domain. In the experiments, we show the ability to improve both the precision and the generated recommendations' profit. Such an outcome represents a win-win situation when e-commerce increases the profit and customers get more valuable recommendations.