 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Previously Fact-Checked Claim Retrieval
May 13, 2023



Fact-checkers are often hampered by the sheer amount of online content that needs to be fact-checked. NLP can help them by retrieving already existing fact-checks relevant to the content being investigated. This paper introduces a new multilingual dataset -- MultiClaim -- for previously fact-checked claim retrieval. We collected 28k posts in 27 languages from social media, 206k fact-checks in 39 languages written by professional fact-checkers, as well as 31k connections between these two groups. This is the most extensive and the most linguistically diverse dataset of this kind to date. We evaluated how different unsupervised methods fare on this dataset and its various dimensions. We show that evaluating such a diverse dataset has its complexities and proper care needs to be taken before interpreting the results. We also evaluated a supervised fine-tuning approach, improving upon the unsupervised method significantly.
Auditing YouTube's Recommendation Algorithm for Misinformation Filter Bubbles
Oct 18, 2022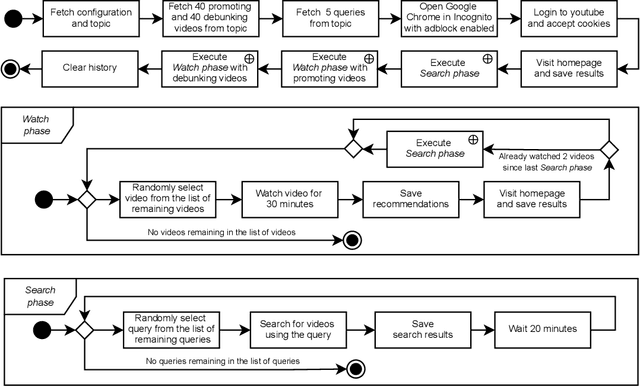
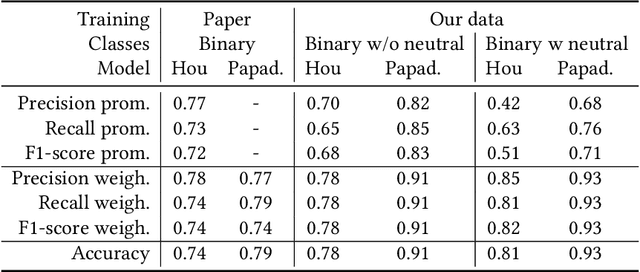
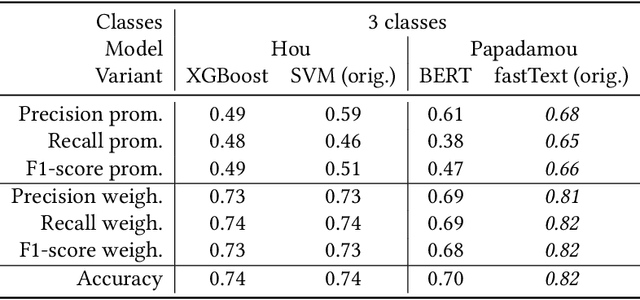
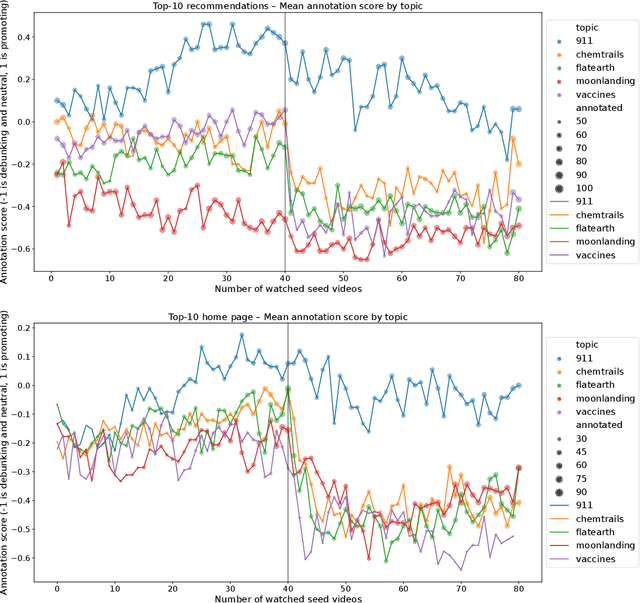
In this paper, we present results of an auditing study performed over YouTube aimed at investigating how fast a user can get into a misinformation filter bubble, but also what it takes to "burst the bubble", i.e., revert the bubble enclosure. We employ a sock puppet audit methodology, in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content. Then they try to burst the bubbles and reach more balanced recommendations by watching misinformation debunking content. We record search results, home page results, and recommendations for the watched videos. Overall, we recorded 17,405 unique videos, out of which we manually annotated 2,914 for the presence of misinformation. The labeled data was used to train a machine learning model classifying videos into three classes (promoting, debunking, neutral) with the accuracy of 0.82. We use the trained model to classify the remaining videos that would not be feasible to annotate manually. Using both the manually and automatically annotated data, we observe the misinformation bubble dynamics for a range of audited topics. Our key finding is that even though filter bubbles do not appear in some situations, when they do, it is possible to burst them by watching misinformation debunking content (albeit it manifests differently from topic to topic). We also observe a sudden decrease of misinformation filter bubble effect when misinformation debunking videos are watched after misinformation promoting videos, suggesting a strong contextuality of recommendations. Finally, when comparing our results with a previous similar study, we do not observe significant improvements in the overall quantity of recommended misinformation content.
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022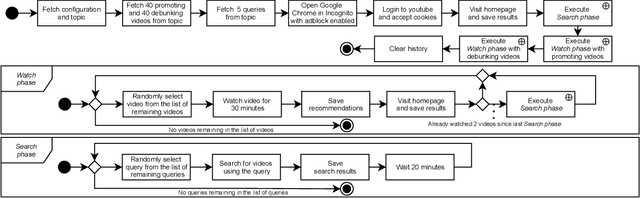


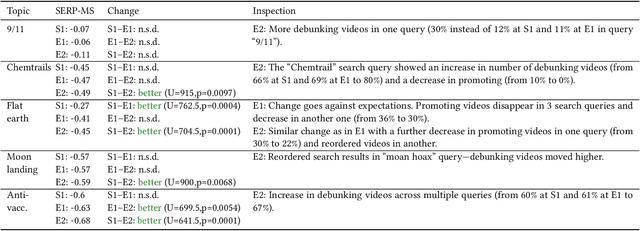
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System