 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Previously Fact-Checked Claim Retrieval
May 13, 2023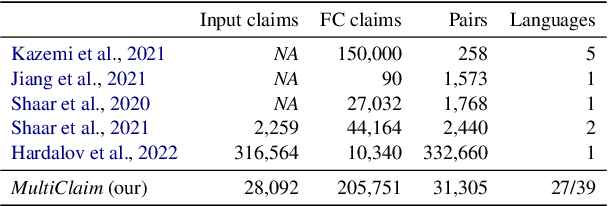



Fact-checkers are often hampered by the sheer amount of online content that needs to be fact-checked. NLP can help them by retrieving already existing fact-checks relevant to the content being investigated. This paper introduces a new multilingual dataset -- MultiClaim -- for previously fact-checked claim retrieval. We collected 28k posts in 27 languages from social media, 206k fact-checks in 39 languages written by professional fact-checkers, as well as 31k connections between these two groups. This is the most extensive and the most linguistically diverse dataset of this kind to date. We evaluated how different unsupervised methods fare on this dataset and its various dimensions. We show that evaluating such a diverse dataset has its complexities and proper care needs to be taken before interpreting the results. We also evaluated a supervised fine-tuning approach, improving upon the unsupervised method significantly.
KInITVeraAI at SemEval-2023 Task 3: Simple yet Powerful Multilingual Fine-Tuning for Persuasion Techniques Detection
Apr 24, 2023



This paper presents the best-performing solution to the SemEval 2023 Task 3 on the subtask 3 dedicated to persuasion techniques detection. Due to a high multilingual character of the input data and a large number of 23 predicted labels (causing a lack of labelled data for some language-label combinations), we opted for fine-tuning pre-trained transformer-based language models. Conducting multiple experiments, we find the best configuration, which consists of large multilingual model (XLM-RoBERTa large) trained jointly on all input data, with carefully calibrated confidence thresholds for seen and surprise languages separately. Our final system performed the best on 6 out of 9 languages (including two surprise languages) and achieved highly competitive results on the remaining three languages.