 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Political Views of Large Language Models: Identification and Steering
Jul 30, 2025Large language models (LLMs) are increasingly used in everyday tools and applications, raising concerns about their potential influence on political views. While prior research has shown that LLMs often exhibit measurable political biases--frequently skewing toward liberal or progressive positions--key gaps remain. Most existing studies evaluate only a narrow set of models and languages, leaving open questions about the generalizability of political biases across architectures, scales, and multilingual settings. Moreover, few works examine whether these biases can be actively controlled. In this work, we address these gaps through a large-scale study of political orientation in modern open-source instruction-tuned LLMs. We evaluate seven models, including LLaMA-3.1, Qwen-3, and Aya-Expanse, across 14 languages using the Political Compass Test with 11 semantically equivalent paraphrases per statement to ensure robust measurement. Our results reveal that larger models consistently shift toward libertarian-left positions, with significant variations across languages and model families. To test the manipulability of political stances, we utilize a simple center-of-mass activation intervention technique and show that it reliably steers model responses toward alternative ideological positions across multiple languages. Our code is publicly available at https://github.com/d-gurgurov/Political-Ideologies-LLMs.
A Generative-AI-Driven Claim Retrieval System Capable of Detecting and Retrieving Claims from Social Media Platforms in Multiple Languages
Apr 29, 2025Online disinformation poses a global challenge, placing significant demands on fact-checkers who must verify claims efficiently to prevent the spread of false information. A major issue in this process is the redundant verification of already fact-checked claims, which increases workload and delays responses to newly emerging claims. This research introduces an approach that retrieves previously fact-checked claims, evaluates their relevance to a given input, and provides supplementary information to support fact-checkers. Our method employs large language models (LLMs) to filter irrelevant fact-checks and generate concise summaries and explanations, enabling fact-checkers to faster assess whether a claim has been verified before. In addition, we evaluate our approach through both automatic and human assessments, where humans interact with the developed tool to review its effectiveness. Our results demonstrate that LLMs are able to filter out many irrelevant fact-checks and, therefore, reduce effort and streamline the fact-checking process.
Large Language Models for Multilingual Previously Fact-Checked Claim Detection
Mar 04, 2025In our era of widespread false information, human fact-checkers often face the challenge of duplicating efforts when verifying claims that may have already been addressed in other countries or languages. As false information transcends linguistic boundaries, the ability to automatically detect previously fact-checked claims across languages has become an increasingly important task. This paper presents the first comprehensive evaluation of large language models (LLMs) for multilingual previously fact-checked claim detection. We assess seven LLMs across 20 languages in both monolingual and cross-lingual settings. Our results show that while LLMs perform well for high-resource languages, they struggle with low-resource languages. Moreover, translating original texts into English proved to be beneficial for low-resource languages. These findings highlight the potential of LLMs for multilingual previously fact-checked claim detection and provide a foundation for further research on this promising application of LLMs.
Generative Large Language Models in Automated Fact-Checking: A Survey
Jul 02, 2024



The dissemination of false information across online platforms poses a serious societal challenge, necessitating robust measures for information verification. While manual fact-checking efforts are still instrumental, the growing volume of false information requires automated methods. Large language models (LLMs) offer promising opportunities to assist fact-checkers, leveraging LLM's extensive knowledge and robust reasoning capabilities. In this survey paper, we investigate the utilization of generative LLMs in the realm of fact-checking, illustrating various approaches that have been employed and techniques for prompting or fine-tuning LLMs. By providing an overview of existing approaches, this survey aims to improve the understanding of utilizing LLMs in fact-checking and to facilitate further progress in LLMs' involvement in this process.
Soft Language Prompts for Language Transfer
Jul 02, 2024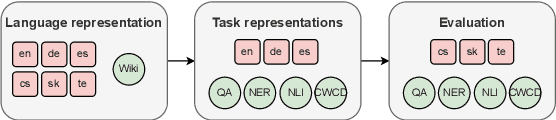


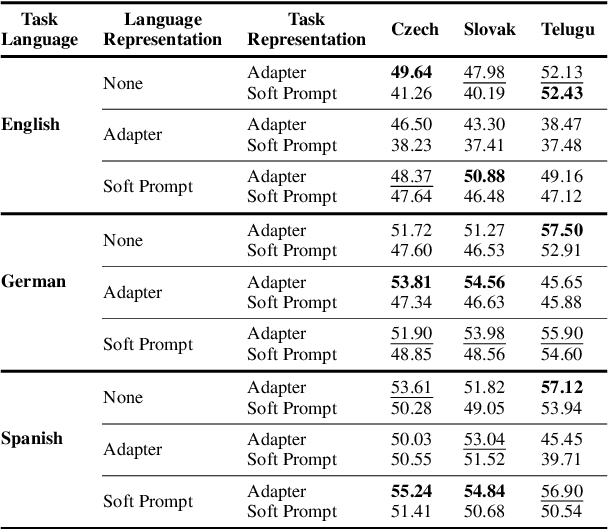
Cross-lingual knowledge transfer, especially between high- and low-resource languages, remains a challenge in natural language processing (NLP). This study offers insights for improving cross-lingual NLP applications through the combination of parameter-efficient fine-tuning methods. We systematically explore strategies for enhancing this cross-lingual transfer through the incorporation of language-specific and task-specific adapters and soft prompts. We present a detailed investigation of various combinations of these methods, exploring their efficiency across six languages, focusing on three low-resource languages, including the to our knowledge first use of soft language prompts. Our findings demonstrate that in contrast to claims of previous work, a combination of language and task adapters does not always work best; instead, combining a soft language prompt with a task adapter outperforms other configurations in many cases.
Disinformation Capabilities of Large Language Models
Nov 15, 2023



Automated disinformation generation is often listed as one of the risks of large language models (LLMs). The theoretical ability to flood the information space with disinformation content might have dramatic consequences for democratic societies around the world. This paper presents a comprehensive study of the disinformation capabilities of the current generation of LLMs to generate false news articles in English language. In our study, we evaluated the capabilities of 10 LLMs using 20 disinformation narratives. We evaluated several aspects of the LLMs: how well they are at generating news articles, how strongly they tend to agree or disagree with the disinformation narratives, how often they generate safety warnings, etc. We also evaluated the abilities of detection models to detect these articles as LLM-generated. We conclude that LLMs are able to generate convincing news articles that agree with dangerous disinformation narratives.
Multilingual Previously Fact-Checked Claim Retrieval
May 13, 2023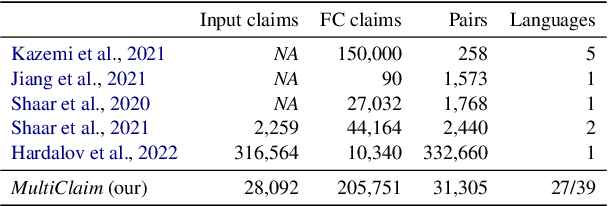



Fact-checkers are often hampered by the sheer amount of online content that needs to be fact-checked. NLP can help them by retrieving already existing fact-checks relevant to the content being investigated. This paper introduces a new multilingual dataset -- MultiClaim -- for previously fact-checked claim retrieval. We collected 28k posts in 27 languages from social media, 206k fact-checks in 39 languages written by professional fact-checkers, as well as 31k connections between these two groups. This is the most extensive and the most linguistically diverse dataset of this kind to date. We evaluated how different unsupervised methods fare on this dataset and its various dimensions. We show that evaluating such a diverse dataset has its complexities and proper care needs to be taken before interpreting the results. We also evaluated a supervised fine-tuning approach, improving upon the unsupervised method significantly.